本文的标题为“无服务器挑战”,因为它探讨了在应用程序开发中实现可扩展性,成本效益和可维护性的各种方法和挑战。这些目标通常很难同时实现。
所讨论的应用程序是基于群集的,而且非常大。它使用Amazon Elasticache以缓存模式重新进行。
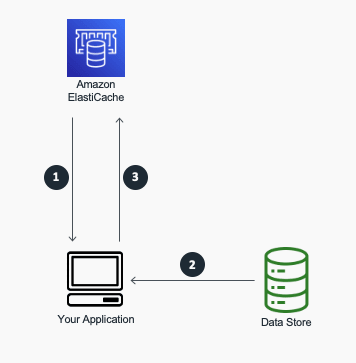
可以总结缓存流量如下:
-
首先检查缓存以确定数据是否可用。
-
如果数据可用,则是缓存命中,并且返回缓存的数据。
-
如果数据不可用,则是缓存失误。查询数据库以获取数据。然后将缓存带有从数据库中检索到的数据,该数据库返回。
请阅读更多Source
该应用程序有效,但是多年来它变得巨大,而过度交流的文化“准备就绪,以防万一”不再适合。
最后,无服务器计算的核心价值,其中包括仅为所使用的费用付款以及让提供商处理基础架构和可扩展性,现在正在管理级别上识别。
要求
- 我们希望架构每秒支持10,000多个请求,理想情况下是100 ms响应时间
- 保持费用在控制之下
- 保持表演并与其他服务集成
这里的问题是:
无法满足这些要求?
答案是YES ,但它非常复杂,因为开箱即用,无服务器的服务并非全部相同,并且它们并没有在相同的级别上进行扩展。
开箱即用,无服务器应用程序仅有效:
- 如果您的工作量很低
- 如果尖峰流量在配额内部
如果您不像我这样的上述情况,那么您进入了由多个出色建议制成的雷区:
- 将全部转换为异步
- 请求配额增加
- 请勿使用无服务器,以供以后听到,请返回无服务器
多年来,我学到了一些技巧have a look at this series,我坚信几乎所有这些都可以以无服务器的方式重写,并以某种妥协来考虑。
为了使其更简单,我假设对我的应用程序的请求有两种类型:
- 获取
- 帖子
我想讨论获取请求的同步,并提出一个简化过程的体系结构。该体系结构仅具有一个端点,例如API网关和LAMBDA功能。但是,我想指出的是,这种方法的可扩展性受Lambda函数使用的爆发配额和下游服务的限制。
想象一下,我需要为每个请求检索内容,这可能由平均大小超过100kb的多个项目组成。有各种可用于存储数据的服务,但是就我个人而言,我选择了S3来保留该大小的JSON文件。
进行简单的测试,我注意到AWS SDK投掷错误:

就我而言,这是S3 SLOW DOWN错误,但类似的其他服务也适用于DynamoDB table being throttled。
保护下游服务的一种好习惯是开始缓存并使用一定程度的陈旧数据。

我邀请您阅读AWS Serverless Hero Yan Cui的旧文章。
我将CloudFront放在API网关的前面,并将缓存到期时间设置为3分钟,这适合我的用例以保持数据新鲜度。
我的流量可以总结如下:
-
在DynamoDB中检查基于GET参数加载的文件。
-
并行加载n文件,并根据参数给出的逻辑进行一些转换。
-
将数据返回到客户端。
流程很简单,现在,由于Cloudfront,我可以实现10,000 RPS,但表演并不是很好:

此外,CDN缓存3分钟后可能会达到S3限制的风险。
每个S3存储桶可以支持最多3,500个PUT/COPY/POST/DELETE的请求率和每秒5,500 GET/HEAD请求。如果超过这些限制,您将收到放缓错误。
我确定有一种方法可以解决它,但它会增加复杂性,并且可能不值得。
结论
要解决这个问题,我的下一篇文章将探索Lambda中的高速缓存模式。这种方法应导致立即的性能增益。我发现缓存数据可以大大提高性能。尽管如此,由于亚马逊API Gateway Cache,Elasticache或Dax之间选择的复杂性,我仍然犹豫使用簇。众多选项,包括实例类型,副本数量,区域和VPC的数量,可能是压倒性的,并且很耗时。