我们需要使用AI的搜索引擎
上周,我在工作中遇到了一个奇怪的问题。业务负责人想知道。开发人员从事了多少吉拉斯。
以及他们所做的代码。
这听起来很奇怪。搜索和搜索的活动使我发现了一个常见问题。让我们从故事开始。
如果您想知道最近两周的每张票证,您已经使用了多少张门票,并且您已经使用了多少张代码和提交。这是检查您的生产力的一种非常简单的方法。您将如何继续这样做?
步骤如下:
- 转到您的票务系统(Jira,您跟踪,Trello等),然后通过用户名进行搜索。
- 将搜索范围缩小到过去两个星期。
- 去Github并在过去的两个星期中搜索您的承诺。
- 手动交叉检查哪个提交是jira。
哇,您已经花了120分钟的时间通过两个不同的平台进行搜索。只是为了获得一些生产力指标。最后,您将获得一些链接。如果时间是金钱,那么这就是整个过程的样子:

您想要答案,而不是链接到网页,jiras或github提交。那么,如何解决这个问题?我们已经在所有网站中都有搜索提供商。我们有大型语言模型,Chatgpt介绍了其企业版本。有没有办法将它们都结合在一起?
开源搜索引擎会遇到AI -Swirl Search 🌌
我最近发现了这款开源搜索引擎Swirl Search。它的确做到了我想要的。通过多个平台搜索,然后通过ChatGpt(或任何LLM)生成我想要的数据。
这是一个开源搜索引擎,结合了许多数据源,并通过IT是UI返回一个答案。
现在,当您采用该输出并将其发送到任何大型语言模型时(例如ChatGpt的API)。您会在几秒钟内而不是几分钟内得到想要的答案。因此,llms与多个数据源结合在一起,您可以得到想要的东西。
漩涡成为搜索栏的搜索栏ð。您可以说这是一个搜索栏,可以统治它们。它基本上是一次搜索所有内容。最好的部分是它的开源是Python,并且不需要重新索引。这意味着不需要额外的数据库。
我发现这个想法纯粹是天才,也是我们需要的东西。随着数据和数据库的增长。

所以,让我们深入研究漩涡是关于什么。
什么是漩涡搜索? ð
旋转搜索是建立在Python/Django堆栈上的开源搜索工具。但是,什么使其他搜索工具与众不同?这是可以通过搜索API适应和分发用户查询的任何平台的能力。
这包括搜索引擎,数据库,NOSQL引擎,云服务等。但是漩涡不止于此。一旦检索数据,它就会采用人工智能,特别是大型语言模型(LLMS)来重新排列并提出最相关的结果。这是在无需提取或索引任何数据的情况下完成的,确保了无缝和高效的用户体验。
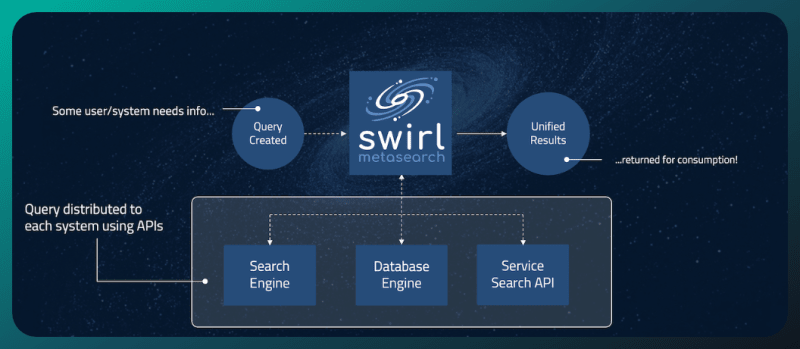
漩涡基于大语言模型的力量。 ð
漩涡的杰出功能之一是通过漩涡的Metapipe使用LLM。大型语言模型席卷了科技界,展示了他们根据培训的信息来理解和生成类似人类文本的能力。通过将LLM集成到其框架中,漩涡可以提供更准确,相关和上下文感知的搜索结果。这是传统搜索方法的重大飞跃,这些方法通常返回大量无关的数据。
下面是使用漩涡的检索增强生成的屏幕截图。在搜索人员或更少的已知数据时,任何LLM都可以生成通用的东西。但是,使用漩涡和多平台搜索您可以找到信息并将其发送到您的语言模型以获得更好的答案和见解。

在搜索Sid Probstein时,Chatgpt首先给出了随机答案。但是,一旦我们查询了通过Outlook Mail发送的播客的笔录,它就会返回一些惊人的答案。想象一下,使用自己的数据进行此操作。
将使您的生产率提高您的生产率。集成功能:与多个平台连接ð
漩涡的强度不仅在于其先进的搜索功能,还取决于其广泛的集成选择。它为Microsoft 365提供OAuth2支持,以确保安全访问数据。此外,漩涡与Atlassian Jira和Confluence,Jetbrains YouTrack,HubSpot等企业服务无缝集成。用户可以通过一个查询搜索多个平台和服务,节省了时间和精力。
以及最近与chatgpt的连接,您可以从搜索中接收输出,并将其发送到chatgpt,以获取带有参考文献的一些惊人答案。而且此功能是我最喜欢的功能。

当前和即将到来的平台可用于使用漩涡
搜索节省时间并从多个数据源获得答案ð
漩涡可以通过多个数据源进行搜索。如果它具有API,则可以通过漩涡搜索。
将Outlook电子邮件,概念,团队聊天等连接在一起。一切都是安全的,没有收集数据。这是拥有开源引擎的最好部分。
通过与生成AI语言模型一起使用旋转搜索,企业,初创企业,个别创建者可以有效地将相关数据提供给ChatGpt,从而使用户可以直接从应用程序数据中直接获得洞察力的答案。
因此,如果您的公司有多个数据源,则您想检索数据并从所有数据中产生洞察力。然后,使用漩涡可以节省时间和金钱。使工作更快地完成。提高生产力ð¥。
检查GitHub上的项目并贡献ð
漩涡中最好的部分是其开源。他们正在寻找贡献者,社区成员和爱好者。我在团队中的经验是积极的。
与即将到来的Hacktoberfest一起,这可能是一个开始的新项目。
如果您想创建一个从多个来源查询多个数据的搜索引擎。然后,让我们深入研究Swirl搜索的未来。查看我们的GitHub存储库。
Give it a Star 🌟和join the Slack。让我们一起塑造数据检索的未来!
 swirlai
/
swirl-search
swirlai
/
swirl-search
然后使用API查询任何内容,然后使用SPACY在不复制任何数据的情况下重新排列统一结果!包括用于Apache Solr,Chatgpt,Elastic Search,OpenSearch,PostgreSQL,Google BigQuery,requestSget,Google PSE,Nlresearch.com,Miro,Miro,Microsoft 365,HubSpot,Atlassian,YouTrack,Github等的零代码配置!
Swirl Metasearch 2.5.1

![]()
![]()

旋转元搜索适应并通过搜索API-搜索引擎,数据库,NOSQL引擎,云/SaaS Services等分发用户查询,并使用AI(Large Language Models)重新排列统一结果没有提取或索引 。它包括OAuth2对Microsoft 365的支持,以及与Atlassian Jira和Confluence,Jetbrains YouTrack,HubSpot等企业服务集成。
使用Galaxy UI,知识工作者可以系统地检查所有配置服务的最佳结果像Google's Programmable Search Engine,Miro和Northern Light Research这样的服务。

建立在Python/Django堆栈上的漩涡旨在使用任何想要解决多silo搜索问题而不移动,重新索引或重新申请敏感信息的人使用。