
如何使用IKOMIA API在自定义数据集上训练Yolov7对象检测
使用IKOMIA API,我们可以使用只有几行代码训练自定义的Yolov7型号。要开始,您需要在虚拟环境中安装API。
How to install a virtual environment
pip install ikomia
在本教程中,我们将使用Roboflow的空中机场数据集。您可以通过以下以下链接下载此数据集:Dataset Download Link。
使用IKOMIA API使用几行代码运行火车Yolov7算法
您还可以直接收取我们准备的开源notebook。
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils import ik
# Initialize the workflow
wf = Workflow()
# Add the dataset loader to load your custom data and annotations
dataset = wf.add_task(ik.dataset_yolo(
dataset_folder="path/to/aerial/dataset/train",
class_file="path/to/aerial/dataset/train/_darknet.labels")
)
# Add the Yolov7 training algorithm
yolo = wf.add_task(ik.train_yolo_v7(
batch_size="4",
epochs="10",
output_folder="path/to/output/folder"),
auto_connect=True
)
# Launch your training on your data
wf.run()
使用NVIDIA GEFORCE RTX 3060笔记本电脑GPU,大约在14分钟内完成了10个时期的训练过程,
什么是yolov7?
是什么使YOLO流行以进行对象检测?
Yolo代表您只看一次;这是一个流行的实时对象检测算法的家族。原始的Yolo对象检测器是2016年的第一个released in。它是由Joseph Redmon,Ali Farhadi和Santosh Divvala创建的。发布时,该体系结构比其他对象探测器快得多,并且成为实时计算机视觉应用程序的最先进。
高平均平均精度(地图)
Yolo(您只看一次)由于多个关键因素而在对象检测领域中广受欢迎。使其非常适合实时应用。此外,Yolo比其他实时系统达到平均平均精度(MAP),进一步增强了其吸引力。
高检测精度
Yolo受欢迎的另一个原因是其高检测准确性。它的表现优于其他具有最小背景错误的最先进模型,使其对对象检测任务可靠。
Yolo还展示了良好的概括能力,尤其是在其较新版本中。它对新域具有更好的概括,使其适用于需要快速稳固的对象检测的应用。例如,比较不同版本的Yolo的研究表明,对于automatic detection of melanoma disease等特定任务的平均平均精度有所提高。
。开源算法
此外,Yolo的开源天性为其成功做出了贡献。社区的持续改进和贡献有助于随着时间的流逝改进了模型。
Yolo的速度,准确性,概括和开源性质的出色结合已将其定位为技术界对象检测的主要选择。它在实时计算机视觉领域的影响不可低估。
YOLO架构
Yolo建筑与GoogleNet共享相似之处,具有卷积层,最大隔层和完全连接的层。
).](https://res.cloudinary.com/practicaldev/image/fetch/s--toFb3X3o--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2614/0%2AP2UBhFj_oTtoVup-.png)
该体系结构遵循一种简化的方法来检测对象检测和工作如下:
-
首先将输入图像大小提高到固定大小,通常为448x448像素。
-
然后将此调整大小的图像通过一系列卷积层,这些卷积层提取并捕获空间信息。
-
YOLO架构采用1x1卷积,然后进行3x3卷积以减少通道的数量并产生立方输出。
-
除最终层以外,整个网络中使用了整流的线性单元(relu)激活函数,该层利用了线性激活函数。
为了提高模型的性能并防止过度拟合,采用了批处理标准化和辍学等技术。批量归一化使每一层的输出归一化,从而使训练过程更加稳定。辍学在训练过程中随机忽略了一部分神经元,这有助于防止网络过于依赖特定功能。
Yolo对象检测如何工作?
在Yolo如何执行对象检测方面,它遵循四步方法:
)](https://res.cloudinary.com/practicaldev/image/fetch/s--ytmJ9tqd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2216/0%2A3PIFIVlYFD0iWfaa.jpg)
-
首先,将图像分为网格单元(SX),负责本地化和预测对象的类别和置信值。
-
接下来,边界框回归用于确定图像中对象的矩形。这些边界框的属性由包含概率得分,坐标和尺寸的向量表示。
-
随后使用工会(iou)的交集来选择基于用户定义的阈值的相关网格单元。
-
最后,应用非最大抑制(NMS)仅保留具有最高概率得分的框,从而滤除潜在的噪声。
Yolov7模型的概述

)](https://res.cloudinary.com/practicaldev/image/fetch/s--cuRO3hXR--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2000/0%2AS9d2tHHY0egJkD_n.png)
与其前任相比,Yolov7引入了几种有助于提高性能的建筑改革。这些包括:
建筑改革:
-
基于串联模型的模型缩放范围允许该模型满足不同的推理速度的需求。
-
e-Elan(扩展有效的层聚合网络),该网络允许模型学习更多多样化的功能以更好地学习。
可训练的释放犬(BOF)提高模型的准确性,而无需提高培训成本:
-
计划的重新参数化卷积。
-
粗糙的辅助机构和铅损失的罚款。
Yolo V7与其前身相比,分辨率有了显着改善。它以608 x 608像素的较高图像分辨率运行,超过了Yolo V3中使用的416 x 416分辨率。通过采用这种较高的分辨率,Yolo V7能够更有效地检测较小的物体,从而提高其整体准确性。
与Yolov6相比,这些增强能力导致可可数据集的平均精度(AP)提高13.7%。
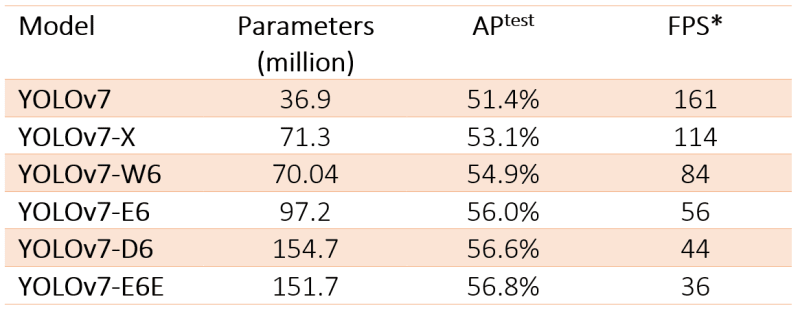
参数和FPS
Yolov7模型具有六个版本,具有不同的参数和FPS(每秒帧)性能。这是详细信息:
逐步:使用IKOMIA API微调预训练的Yolov7模型
使用您下载的航空图像数据集,您可以使用Ikomia API训练自定义Yolo V7型号。
步骤1:导入
from ikomia.dataprocess.workflow
import Workflowfrom ikomia.utils import ik
-
工作流程是创建工作流程的基本对象。它提供了设置输入(例如图像,视频和目录),配置任务参数,获得时间指标的方法,并访问特定的任务输出,例如图形,细分掩码和文本。
-
ikâ是一种自动完成系统,旨在方便易于访问算法和设置。
步骤2:创建工作流程
我们初始化了一个工作流实例。然后可以使用wfâwfâ对象将任务添加到工作流实例,配置其参数并在输入数据上运行它们。
wf = Workflow()
步骤3:添加数据集加载程序
下载的数据集以yolo格式使用,这意味着对于每个文件夹中的每个图像(test,val,train),有一个相应的.txt文件,其中包含所有边界框和与飞机相关的类信息。此外,还有一个_darknet.labels文件,其中包含所有类名称。我们将使用Ikomia API提供的数据集_yolo模块来加载自定义数据和注释。
dataset = wf.add_task(ik.dataset_yolo(
dataset_folder="path/to/aerial/dataset/train",
class_file="path/to//aerial/dataset/train/_darknet.labels")
)
步骤4:添加Yolov7模型并设置参数
我们添加了 train_yolo_v7 训练我们的自定义yolov7型号的任务。我们还指定了一些参数:
yolo = wf.add_task(ik.train_yolo_v7(
batch_size="4",
epochs="10",
output_folder="path/to/output/folder"),
auto_connect=True
)
-
batch_size :在更新模型之前处理的样品数量。
-
时代:通过培训数据集的完整传递数量。
-
train_imgz :训练期间的输入图像大小。
-
test_imgz :在测试过程中输入图像大小。
-
dataset_spilt_ratio :该算法将数据集自动划分为火车和评估集。值为0.9的值表示使用90%的数据进行培训和10%进行评估。
auto_connect = true - 参数可确保DataSet_yolo任务的输出自动连接到Train_yolo_v7任务的输入。
步骤5:将工作流程应用于数据集
最后,我们运行工作流程开始训练过程。
wf.run()
您可以使用Tensorboard或MLFlow等工具来监视培训的进度。
训练完成后, train_yolo_v7 任务将在输出_ folder内的时间戳命名的文件夹中保存最佳模型。您可以在时间戳文件夹的“权重”文件夹中找到最佳的.pt型号。
测试您的微调Yolov7型号
首先,我们可以在预训练的Yolov7模型上运行空中图像:
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils.displayIO import display
from ikomia.utils import ik
# Initialize the workflow
wf = Workflow()
# Add an Object Detection algorithm
yolo = wf.add_task(ik.infer_yolo_v7(thr_conf="0.4"), auto_connect=True)
# Run on your image
wf.run_on(path="/path/to/aerial/dataset/test/airport_246_jpg.rf.3d892810357f48026932d5412fa81574.jpg")
# Inspect your results
display(yolo.get_image_with_graphics())

我们可以观察到推理_yolo_v7默认的预训练模型不会检测任何平面。这是因为该模型已经在可可数据集上进行了培训,该数据集不包含机场航空图像。结果,该模型缺乏对飞机从上面的样子的了解。
要测试我们刚刚训练的模型,我们使用model_weight_fileâ参数指定自定义模型的路径。然后,我们在以前使用的同一图像上运行工作流程。
# Use your custom YOLOv7 model
yolo = wf.add_task(ik.infer_yolo_v7(
model_weight_file="path/to/output_folder/timestamp/weights/best.pt",
thr_conf="0.4"),
auto_connect=True
)

结论
在本综合指南中,我们深入研究了Yolov7预培训模型的过程,在识别特定对象类时授权其获得更高的精度。
IKOMIA API是改变游戏规则的人,简化了计算机视觉工作流程的开发,并通过各种参数可以轻松实验以解锁出色的结果。
为了更深入地了解API的功能,我们建议参考documentation。此外,不要错过机会探索Ikomia HUB上可用的高级算法名册,并与Ikomia STUDIO一起旋转,Ikomia STUDIO是一种用户友好的界面,它反映了API的功能。