小型
Brazilian "Rinha de Backend" challenge的第2部分。单击here到第1部分
8月15日,上午7点。
我醒了,吃了很长的早餐,坐在我的办公室,开始解决鬼,该在困扰我之前过夜。 (在这种情况下,我的大脑 +过度思考)
他的一些技巧确实有帮助!
- 修复这两个查询(1,2)业务规则
- Adding more replicas进入nginx和dockercompose
- 微调dockercompose上的resources
- Fixing PINO async logging
- 配置nginx worker connections
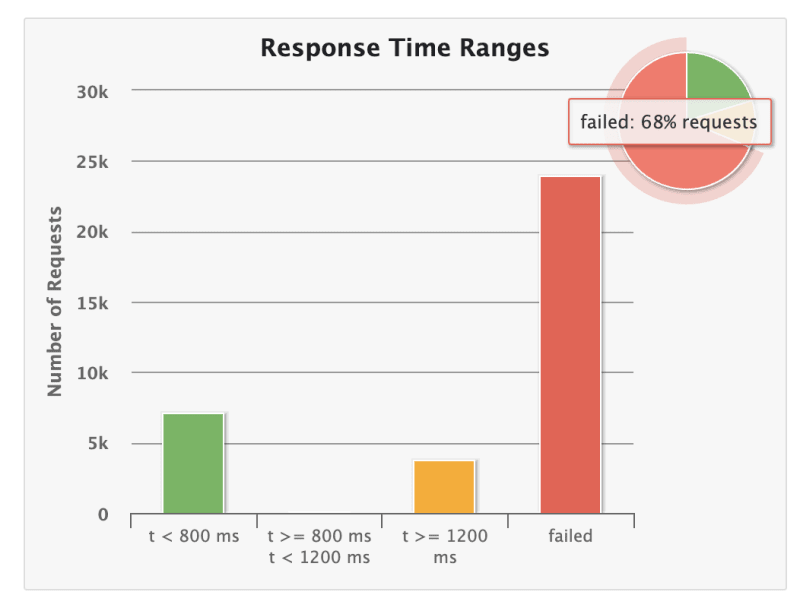
我能够获得一些良好的改进,达到了〜10%的success,这听起来确实比10%好。但是伙计,有些事情真的已经崩溃了。
为什么我的应用程序执行如此糟糕?
很好。我忘记了昨天的发现。 数据库瓶颈。
我要做的第一件事是复制the database query,并针对至少40K患者进行运行。令人惊讶的是,甚至我肯定我已经设置了索引。
但是在解释数据库优化之前,我需要解释我在改进之前的结构。
CREATE TABLE IF NOT EXISTS pessoas (
id SERIAL PRIMARY KEY,
apelido VARCHAR(32) UNIQUE NOT NULL,
nome VARCHAR(100) NOT NULL,
nascimento DATE NOT NULL,
stack VARCHAR(32)[]
);
CREATE INDEX IF NOT EXISTS term_search_index_apelido ON pessoas USING gin(to_tsvector('english', apelido));
CREATE INDEX IF NOT EXISTS term_search_index_nome ON pessoas USING gin(to_tsvector('english', nome));
分析数据库运行查询(等等)的最佳工具是EXPLAIN。
当然,我已经忘记了索引。但是,我将如何为FTS索引数组字段呢?那是一个糟糕的设计选择。阵列不能索引文本,性能对此用例有点不利。
好吧,让我们运送这个responsibility to the client。客户对客户进行序列化和序列化的stack字段became a JSON field。 json字段是文本索引,voilé,我们现在有一个堆栈字段的索引。
再次运行查询:小于20ms。凉爽的。那就是预期的。

毫不奇怪,我达到了success的45%和>1200ms请求的27%。我的数据库降低了CPU的使用和错误,例如过早连接,超时和连接损失仅通过压力测试的中端出现。
从数据库角度来看,我认为据我所知。
现在是缓存的时候了。
我决定使用REDIS,而不是LRU内存缓存,因为我已经分发了应用程序,并且我的目标是拥有至少4-5个复制品,这将使相同的资源不经常在同一POD/Container上要求。
缓存策略
- /people?t
- 缓存了响应。
- post: /people
- 创建后通过ID缓存了整个资源
- 缓存了
apelido字段,因为它在数据库上具有唯一的约束。
- get: /peos /:id
- 在登陆数据库之前检查缓存。
- 关于我设置的验证中间件(middleware.js)
- 检查了REDIS设置中是否已经存在,并且是否已经检查了数据库。如果确实存在,我们更新了缓存,并将响应返回给客户端
这是一个相当简单的redis缓存设置。
(我至少永远不会运送到生产环境)

最终可接受的success率! success的92%是超过1200ms的请求的4%。
但仍然...数据库CPU用法 Too 即使在缓存和连接关闭仍然是一件事情。
回到DB优化
我认为我在顶部的PG connection pool configured上有办法。
,鉴于我们运行了3-4个复制品,这有点合理,每个复制品都在分配小于1 CPU的数据库上具有8个连接。
(我还将应用程序的3 replicas减少了)
使用此小改进,我能够达到success率的100%
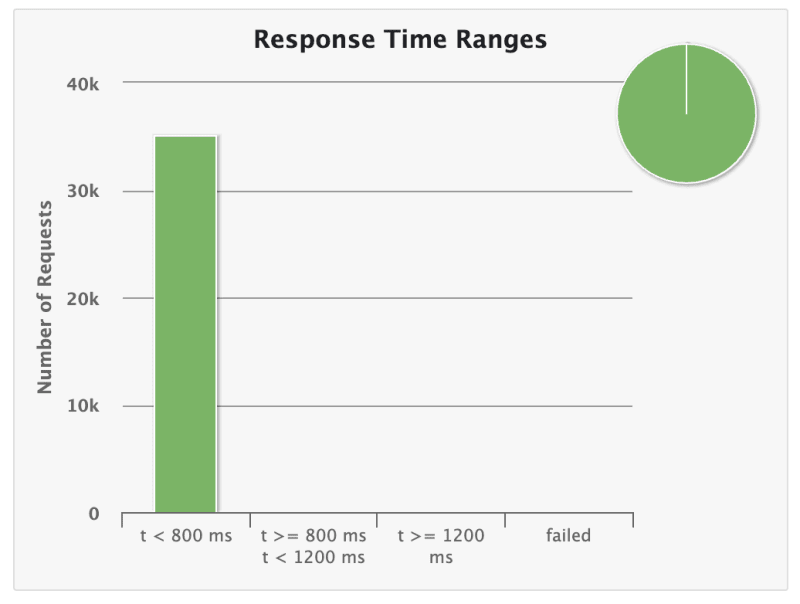

最终,我的同事们拥有相同的基准测试,但不仅如此,我意识到在处理规模时需要认真对待attention to detail。这是一个沙盒实验,我遇到了很多小问题,小的legacy-type代码(1天遗产。我称之为),小的过早优化以及一些顶部的头,试图找出简单的东西。
我已经完成了我对自己的建议。尽管我知道它可以进行更多的优化,但我还是决定踏上竞争。
这是为了下一个谈话...