在编程语言的领域中,预定义的数据结构是一个常见的包含,尽管在不同语言的名称和实现详细信息方面有所不同。尽管存在这些差异,但这些结构基础的基本原理仍然一致。在本文中,我们踏上了对数据结构的沉浸式探索,并深入研究了他们在各种编程语言中的内部实现。为了帮助理解,我们通过简洁的动画增强了学习体验,对这些基本概念提供了直观的掌握。尽管标题特别提到了“多语言程序员”,但很明显,单语言程序员也可以从本文中获得显着的好处。本文标志着系列的开始,我们将在其中深入探讨了一系列基本主题。该系列将涵盖以下主要主题:
- 线性数据结构
- 非线性数据结构
- 算法
Memory
】– ow ea Physical layer
ââââ€â阿Virtual layer
Eposcus ang''ger abiaooqian3
£ep eplepiaoqics
Algorithms
âââ€ââ阿比亚qian6
£awâe epiaoqian7
£←£out
£法语the AbiaOooqhian9意大利
】eAlgorithm design techniques
Data structures
£outabiaooqian12
âââ€ââ阿比亚奇人13
£hou abiaoqi14
£您a a abiaOOQian15
EPés信息¾¾ABRIAO,16 IN
-
££â} abiaOOQI118在什么是18 login
epésusétipia -piaoqich ag
epése ure'e有anherao,20
epésus - 阿布里亚(21
)
-
Eposcus eus –// abiaoq23
eposcous epse epese''''' - quriqhor
- ââ€ââ½½
epese use thate theeur,explox ates a explox ates a e – e explox a e
EPES EPER ATEâuneoqian27
我们的''''''' -
- '' -
- -
epese epe epia''
££¾¾ -ad ad abiaooqian32
Epese''''' quriqhaiqai - firiqucanu50
epese epese''''
Epi epi ep ate}
epese©ââââââ€ââ€ââ€ââ€â†-
epese epese©â–ââââââââââââ–âââ–ââââââââ– - â–'''''
â©â©â© - - iSleo
EPESE EPESE的Epese Epese'
£yre到Associative collections
Epese epese- epese -
epese epese©âââ€âââ€ââ€我们的''
epese epese epese – am –â€â€â–âââ–âââ–âââ–
epese epese'' - Quriqhi44
££←Abiaoqi45 in
- â–ââ–ââ–ââ–ââ–âââ–ââââââââââââââââââââââââââââââââââââââââââââââââââââââ级 - - â€d a d a d
epese epese©â€ââ€â€â€
- '我们的'''' - quriqhi45
standard library data structures
】 -EP EPIAOQIANQI50→
】 -eld Swift
ââââ€â阿CSharp
âââ‖ Python
''e e e a d od oxianqian54
Non-Linear data structures
Algorithms
假设您有一个数据块的集合,称为| a |,| b |,| c |,| d |,| e |,等等。您的目标是通过使用处理该数据并产生结果的算法来解决问题。无论您选择的特定问题或算法如何,都需要遵循某些步骤:
- 将一些空间(内存)分配给您的数据。
- 在分配的空间中排列您的数据块,并在其中创建逻辑关系(隐式或显式)(指定
Data Structure)。 - 对数据块进行一些操作(
Algorithm):这些操作可能包括:- 阅读数据块
- 写数据块
数据结构和算法是紧密相互交织的概念。当与特定数据结构一起使用时,某些算法表现出更好的效率,相反,某些数据结构提供了有利的布置,从而提高了特定算法的效率。为了有效解决问题,设计有效的算法和适当的数据结构至关重要。设计这些有效的解决方案需要对所涉及的基本面和分析技术有牢固的了解。
记忆
物理层
计算机系统的物理层负责电子或磁形中数据的实际存储和检索。物理层中的内存是分层组织的,具有不同的类型和内存级别。物理层中的内存类型:
- 寄存器
- 缓存内存
- 主内存(随机访问存储器-RAM)
- 次要回忆:( HDD,SSD,...)
物理内存对于虚拟内存系统中的程序是看不见的,作为程序员,您不需要推理它。
内存:虚拟图层
在虚拟层的何处以及如何分配内存?
地点
-
Stack:快速分配。更快的访问速度。- 仅移动整数指针分配/退出内存。
-
Heap:慢速分配。访问速度较慢。- 搜索堆
- 其他线程的同步堆。
- 分配内存。
安排
-
Contiguous:连续内存块中的批量分配。 (更快的访问速度)。 -
Discontiguous:分离的内存块中的动态分配。(访问较慢)。
算法
所有算法的核心是涉及accessing和mutating的基本操作,无论我们如何在内存中排列数据块,以及它们之间的逻辑连接是什么。在此级别,所有算法都可以简化为以下一个或一些操作。
基本操作
-
read- AccessDatabySequence()(向前或向后)
- getIndexingInformation():
getStartIndex(),getEndIndex(),getNextIndex(forIndex),getPreviousIndex(forIndex) - AccessDataAtrandomIndex(:):对于随机访问,时间复杂性应为orde
O(1)。 - AccessDataatFront()
- AccessDataatback()
-
write- insertdataArandomIndex(:) >
- insertdataatfront()
- insertdataatback()
- 删除ataatrandomIndex(:)
- 删除aTaatfront()
- 删除ataatback()
- 更新ataatrandomIndex(:)
- UpdatedAtaatFront()
- UpdatedAtaatback()
例如,Linear search算法使用accessDataBySequence并用指定值比较每个项目以查找答案,而Binary search算法需要accessDataAtRandomIndex操作。
Random Access上的注释:在数据结构的背景下,随机访问是指立即访问特定位置的能力。例如,使用Array,如果您选择一个随机索引,则数组数据结构可以立即为您提供该索引的地址。但是,如果您尝试在LinkedList中访问随机索引,则数据结构将无法立即提供地址。相反,它必须从头开始(从头开始),直到达到所需的索引。因此,LinkedLists被认为具有随机访问操作的O(n)(上限)的时间复杂性。大多数算法都需要O(1)随机访问,并且Java等语言引入了标记接口(没有方法),称为RandomAccess。该接口提醒您某些算法依赖于随机访问。为了确保这些算法与数据结构有效地发挥作用,必须使其与随机访问兼容。 Swift等效是标记协议RandomAccessCollection。
基本算法
基本操作构成了构建算法的基础。相反,某些算法遵循其他算法的基本规则。以输入数据顺序对算法的时间效率的影响。事先分类数据可以极大地简化我们的生活,因为它对许多算法的效率具有重大的积极影响。分类可以通过两种方法来完成。第一种方法涉及利用排序算法来安排未分类的集合。第二种方法涉及利用特定的数据结构,例如二进制搜索树,以促进通过摊销分类数据。
排序算法
所有排序算法需要getIndexingInformation,accessDataAtRandomIndex(:)操作。也必须是可比的(除非用于非及比较算法)。
- 就地排序算法:他们需要
updateDataAtRandomIndex(:)操作。- 泡泡排序
- 选择SOR
- 插入排序
- 堆排序
- 快速排序
- 不是原地排序算法:
- 合并排序
- radix排序(非比较)
- 存储桶排序(非及比较)
搜索算法
- 线性搜索:需要
accessDataBySequence() - 二进制搜索:需要
accessDataAtRandomIndex(:)与O(1)
算法设计技术
- 分裂和征服
- 递归
- 随机算法:输入必须是随机的。
- 动态编程
- 贪婪算法
在下一篇文章中,我将返回算法。
数据结构
每个数据结构都有以下特征:
-
Virtual layer Memory management在虚拟层。 -
Logical connection在数据块之间,无论是implicit还是explicit。- 隐式:在Array中,数据块没有直接的连接,但是隐含地以特定顺序连续地安排在内存中。
- 显式:在LinkedList中,这些块可能不会连续存储在内存中,但是每个节点都有与其他节点的连接信息。
-
Rules用于应用基本操作。 - 提供具有空间/时间复杂性的基本
read和write操作。可以使用以下概念轻松分析基本操作数据结构的空间/时间复杂性:Contiguous Memory data structures和Discontiguous Memory data structures
连续的内存数据结构
- 固定尺寸的初始化。尺寸保持固定。
- 每个块的地址可以通过:
start + k * blocksize来计算。随机访问时间复杂性是O(1) - 批量记忆分配
- 相同尺寸的内存块(相同类型)
- 基本数据结构示例:数组

不连续的内存数据结构
- 这种布置是一种特殊的图形(我们可以使用它表示图形)。
- 每个块包含下一个块的地址。
- 随机访问操作的时间复杂性是
O(n) - 动态内存分配
- 内存块大小可能是不同的(不同类型)。
- 基本数据结构示例:linkedlist

CM和DCM的组合
- 一个连续的记忆阵列,可指示对象的连续记忆或不连续的内存集合。
- 随机访问操作的时间复杂性是
O(1)(通过指针数组),但是在非连续内存中访问对象的开销很小。 - 地址(指针)数组的批量内存分配,对象的动态内存分配。
- 对象可以具有不同的内存大小(不同类型)。
- 基本数据结构示例:大多数编程语言中的引用对象数组。

线性数据结构
通过使用上述概念的一个或组合,可以实现基本数据结构,从而成为更复杂的数据结构的基础。此外,可以通过利用与这些基本概念相关的复杂性和成本来容易分析空间和时间复杂性以及内存成本。
大批
在编程语言中,数组是内置类型。指针数组(或参考类型的数组)的作用为Combination of CM and DCM。对于原始类型(或值类型,例如int,enum,c#,swift,...)的行为就像Contiguous Memory data structures。
-
Basic operations时间复杂性:与Contiguous Memory data structures相同 -
Good:-
accessAtRandomIndex,insertAtBack,removeAtBack操作。 - 散装内存分配(快速)。
- 连续内存。快速访问。
- 如果与原始类型(值类型)一起使用,则无动态内存分配成本。
-
-
Not good:-
insertAtFront,insertAtMiddle,removeAtFront,removeAtMiddle操作。 - 固定尺寸。
-
- 编程语言实施:

Dynamicararay
类似于数组,但可以在运行时生长。指针(或参考类型的动态图案)的动态阵列就像Combination of CM and DCM一样。对于原始类型(或值类型,例如int,enum,c#,swift,...)的行为就像Contiguous Memory data structures。调整大小的步骤:
- 将新数组分配给新尺寸
- 将旧数组值复制到新数组
- 删除旧数组
-
Basic operations时间复杂性:与Contiguous Memory data structures相同 -
Good:
-
-
accessAtRandomIndex,insertAtBack,removeAtBack操作。 - 散装内存分配(快速)。
- 如果与原始类型(值类型)一起使用,则无动态内存分配成本。
-
Not good:
-
-
insertAtFront,insertAtMiddle,removeAtFront,removeAtMiddle操作。 - 当容量满足时,新的内存分配和复制成本。
- 根据增长策略有未使用的内存分配。例如,在Swift编程语言中,每次阵列容量都满,它都会使数组的容量增加一倍。
- 编程语言实现:
- CPP: Vector.
- Swift :contiguousarray和array是动态的。当容量满足时,尺寸会加倍。
- python :list是其他对象的动态指针。这种行为总是像Combination of CM and DCM。 UserList是一个包装类别,可让您通过从用户列表继承并实现某些方法来创建自己的列表式对象。它提供了一种创建类似自定义列表类的类的方便方法,而无需直接划分内置列表类。
- java :ArrayList和Vector是动态的,区别在于向量是线程安全。
-
c#:ArrayList和List是动态阵列。不同之处在于,
ArrayList是非生成的,可以存储任何元素,而List<T>是提供类型安全集合的通用类。 -
javascript :当涉及JavaScript时,情况有些不同。 Array是动态的,您可以向其添加多种类型。由于数组是一个对象,并且JavaScript中的对象是Hashtables,因此您也可以使用索引字符串访问数组!根据值的类型,JavaScript数组的行为不同。
- 在V8 Engine中,当数组仅包含单个原始类型(例如整数,float,...)时,它将由该类型的C ++数组来支持,而行为就像Contiguous Memory data structures。 。
- 当数组包含多种原始类型时,数组将由较大一个的C ++数组进行支持,而行为与上述相同。
- 如果数组仅包含对象或数字和对象的混合物,则它将由一系列指针支持(原始类型将在对象内部装箱)。行为就像Combination of CM and DCM。
- 当您有一个sparse array(为什么?)时,如果它不太备用,它仍然会被数组的支持,而空数组索引被一个孔值代替。如果阵列非常稀疏,它将不再由内存中的数组支持。取而代之的是,它将由词典/hashtable支持(通常将键存储为索引的字符串表示,而值是元素本身)。
铃声
环缓冲区是使用数组实现的专业数据结构。这是一个静态大小的缓冲区,读写操作通过两个不同的指针进行,以圆形的方式迭代阵列。

-
Basic operations时间复杂性:与Array相同,具有以下改进:-
insertAtFront是O(1) -
removeAtFront是O(1)
-
-
Good:-
accessAtRandomIndex,insert操作。 - 散装内存分配(快速)。
- 如果与原始类型(值类型)一起使用,则无动态内存分配成本。
- 当它是固定尺寸时,我们可以将其映射到虚拟内存层存储页面以使其超快。
-
-
Not good:- 固定尺寸。
- 如果写入频率超过读取频率,则写操作可能会失败。
- 编程语言实施:
LinkedList

-
Basic operations时间复杂性:与Discontiguous Memory data structures相同,有一个改进。-
insertAtBack()变为O(1),因为我们跟踪尾巴。 -
removeAtBack()保持O(n),因为我们必须从头到索引n-1迭代才能删除n。
-
-
Good:-
insertAtFront,removeAtFront,insertAtBack操作。
-
-
Not good:-
accessAtRandomIndex,removeAtBack,insertAtMiddle,removeAtMiddle操作。 - 动态内存分配(慢)。
-
- 编程语言实施:
- CPP: forward_list.
- Swift :没有内置的LinkedList实施。可以找到实现here。
- python :LinkedList没有内置实施。可以找到实现here。
- Java: LinkedList is DoubleLinkedList.
- c#:LinkedList是DoubleLinkedList。
- javaScript :没有用于LinkedList的内置实现。可以找到实现here。

DoubleLinkedList

-
Basic operations时间复杂性:与Discontiguous Memory data structures相同,有两个改进:-
insertAtBack()变为O(1)。 -
removeAtBack()变为O(1)。现在我们可以从N访问N-1,我们可以从N-1中删除N-1的指针。
-
-
Good:-
insertAtFront,removeAtFront,insertAtBack,removeAtBack操作。
-
-
Not good:-
accessAtRandomIndex,insertAtMiddle操作。 - 动态内存分配(慢)。
- 高额外存储的高架用于前向和背部参考。
-
- 编程语言实施:
- cpp :list是双重的linkedlist。
- Swift :没有DoubleLinkedList的内置实现。可以找到实现here。
- python :没有内置的DoubleLinkedList实施。可以找到实现here。
- Java :LinkedList是DoubleLinkedList。
- c#:LinkedList是DoubleLinkedList。
- JavaScript :没有用于DoubleLinkedList的内置实现。可以找到实现here。

圆形链接清单
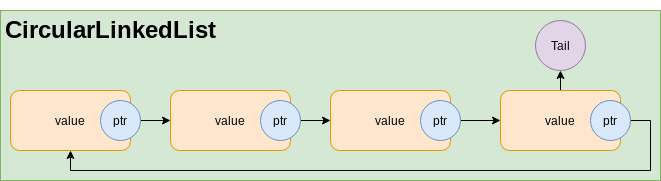
-
Basic operations时间复杂性:与LinkedList相同,具有更多功能。- 我们可以遍历先前的节点
- 我们可以在循环中穿越。
Circulard Loubselinkedlist

-
Basic operations时间复杂性:与DoubleLinkedList相同,具有更多功能。- 我们可以遍历先前的节点
- 我们可以在两个方向上遍历循环。
堆
堆栈是最后一式淘汰(LIFO)数据结构。插入/从其中一端删除的Good的任何数据结构都可以用作堆栈的容器。基于此,可以使用DynamicArray(add/act/emover从背面),LinkedList(Good at add/comment/emove DoubleLinkedList(ad DoubleLinkedList)(add at add at Add/从前后和背面删除)和Deque实现堆栈。每个实现都继承了容器数据结构的Good和Not Good。

通过DynamicArray堆叠
-
Basic operations时间复杂性:与DynamicArray:相同 -
Methods:-
push():阵列容器上的insertAtBack -
pop:阵列容器上的removeAtBack
-
-
Good:-
push()和pop()是O(1)操作。 - 指针的批量记忆分配。
- 如果与原始类型(值类型)一起使用,则无动态内存分配成本。
-
-
Not good:- 当内部数组容量满足时,新的内存分配和复制成本。
- 根据指针阵列的增长策略进行了未使用的内存分配。
- 编程语言实施:

通过LinkedList堆栈
-
Basic operations时间复杂性:与LinkedList相同。我们使用LinkedList的头插入/删除。 -
Methods:-
push():linkedlist容器上的insertAtFront -
pop:linkedlist容器上的removeAtFront
-
-
Good:-
push()和pop()是O(1)操作。
-
-
Not good:-
accessAtRandomIndex是O(n)。 - 动态内存分配(慢)。
-

通过dega堆叠
Deque数据结构可以使用Deque via DoubleLinkedList或Deque via Array实现。由于其行为,Deque可以用作堆栈的容器。堆栈的C ++默认容器是Deque。
队列
队列数据结构是首先。 AddatFront和RemoveAtback或VICE的每个数据结构都可以用作队列数据结构的容器。 DoubleLinkedList(在两端的add/emove at add/emover)可以用作队列数据结构的容器。另外,RingBuffer可用于固定尺寸的队列。由于O(n)用于插入操作,DynamicArray:不是队列数据结构的好容器。我们可以使用Queue via Double Stack (Stack via DynamicArray)摊销这种复杂性。另一种方法是将内容存储在多个较小的数组中,并根据需要在开始或结束时分配其他阵列。通过保持动态数组或包含每个较小数组的指针的链接列表来实现索引。在这种情况下,插入从O(n)降低到O(small_array.length)的成本。这种方法用于deque。

队列通过DoubleLinkedList
-
Basic operations时间复杂性:DoubleLinkedList -
Methods:-
enqueue():doublelinkedlist容器上的insertAtFront。 -
dequeue():doubleLinkedList容器上的removeAtBack。
-
-
Good:-
enqueue()和dequeue()是O(1)操作。
-
-
Not good:-
accessAtRandomIndex操作。 - 向前/向后指针的额外记忆。
- 动态内存分配(慢)。
-
- 编程语言实施:
- cpp :CPP罐中的queue在容器中具有Deque或List(DoubleLinkedList)。默认容器是Deque。
- swift :没有队列的内置实现。可以找到实现here。
- python :没有队列内置实施,但是list可以用作Python的队列。可以找到一个实现here。
- Java :LinkedList和ArrayDeque已实现了队列接口。
- c#:c#中的Queue使用圆形缓冲阵列。
- JavaScript :可以找到实现here。

队列通过Ringbuffer
-
Basic operations时间复杂性:RingBuffer -
Methods:-
enqueue():insertAtRandomIndex在数组容器上。 -
dequeue():阵列容器上的accessAtRandomIndex。
-
-
Good:-
enqueue()和dequeue()是O(1)操作。 - 如果用于原始类型(值类型),则无动态分配。
-
-
Not good:- 固定尺寸,
enqueue()可能会失败。
- 固定尺寸,
- 编程语言实施:
- c#:c#中的Queue使用圆形缓冲阵列。

队列通过双堆
如果我们将DynamicArray用作队列的容器,则dequeue()时间复杂度为O(n)(添加项目以开始阵列是O(n)操作)。但是我们可以使用两个堆栈将这种复杂性摊销给O(1)。 enqueue()的左堆和dequeue()的右图。每次左堆为空时,都会将右列内容复制到左堆。此操作保证了队列的首先出局。
-
Basic operations时间复杂性:类似于Stack via DynamicArray。 -
Methods:-
enqueue():左数组容器上的insertAtBack(构造堆栈)。 -
dequeue():右数组容器上的removeAtBack(Dequeue堆栈)。
-
-
Good:-
enqueue()和dequeue()是O(1)操作。 - 如果用于原始类型(值类型),则无动态分配。
-
-
Not good:- 当容量满足时,新的内存分配和复制成本。
- 根据增长策略有未使用的记忆分配。

Deque作为尾巴
Deque (Double-Ended Queue)可以用作队列。
和
Deque(双端队列)是enqueue()和dequeue()的一种队列。插入/从两端删除的每个数据结构都可以用作Deque数据结构的容器。该要求的唯一完整数据结构是DoubleLinkedList。 Array不是直接实施Deque数据结构的良好数据结构。但是,我们可以使用一些技巧将Array用作Deque数据结构的容器。参见Deque via Array。

Deque通过DoubleLinkedList
通过DoubleLinkedList实施Deque很简单,因为此数据结构具有O(1)用于插入/removeatfront和insertatback/removeatBack操作。
-
Methods:-
pushBack():DoubleLinkedList容器的插入式插件。 -
pushFront():DoubleLinkedList容器的插入额叶。 -
popBack():DoubleLinkedList容器的重新维置。 -
popFront():DoubleLinkedList容器的拆卸前面。
-
-
Good:- 轻松实施
-
Not Good:- 随机访问操作。
- 动态内存分配(慢)。
- 向前和背部引用的额外存储的高架。
- 编程语言实施:
- python :deque在内部使用DoubleLinkedList。

道路和阵列
队列数据结构的情况下,Array不能直接用作Deque数据结构的容器,因为插入时间/removeatFront操作不是阵列的O(1)。我们可以使用以下技术之一将Array用作容器:
- 使用特殊的RingBuffer。
- 使用阵列和从下面阵列的中心分配Deque内容,并在到达两端时调整基础数组的大小。
- 将内容存储在多个较小的数组中,根据需要在开始或结束时分配其他阵列。索引是通过将装有指针的动态阵列保留到每个较小数组的情况下来实现的。在这种情况下,取消了步骤2中调整数组大小的成本,但不同的小数组并未在内存中分配。
-
Good:- 随机访问操作
-
Not Good- 更复杂的实施
- 填充时需要调整数组的需求
- 编程语言实施:

优先地
优先级与具有一个差异的Queue相同。 dequeue操作不适合已插入的第一项。取而代之的是,根据优先级标准选择了Dequeue项目,并且该项目可能位于集合的正面,中间或末端。在其中一端插入时Good的任何数据结构都可以用作优先级的容器。由于发现要脱水的项目包括一个搜索阶段,因此线性数据结构作为优先级的容器,Dequeue操作的时间复杂性为O(n)。如果将堆数据结构作为容器,则由于堆的内部结构,时间复杂性降低至O(log(n))。

PriortityQueue通过Dynamicaray
-
Methods:-
enqueue():阵列容器上的insertAtBack -
dequeue():迭代,然后在数组容器上进行removeAtMiddle。时间复杂性是O(n)。
-
-
Good:-
enqueue()是O(1)操作。 - 如果用于原始类型(值类型),则无动态分配。
-
-
Not good:-
dequeue()操作是O(n)。 - 当容量满足时,新的内存分配和复制成本。
- 根据增长策略有未使用的记忆分配。
-
- 编程语言实施:
- cpp :默认情况下,priority_queue将Deque用作容器。也可以使用向量。
优先级通过LinkedList
-
Methods:-
enqueue():linkedlist容器上的insertAtFront。 -
dequeue():迭代,然后在linkedlist容器上进行removeAtMiddle。时间复杂性是O(n)。
-
-
Good:-
enqueue()是O(1)操作。
-
-
Not good:-
dequeue()操作是O(n)。 - 动态内存分配(慢)。
-
优先道路和
Deque数据结构可以使用Deque via DoubleLinkedList或Deque via Array实现,并且Priorityqueue可以将其用作容器。
优先级通过BinaryHeap
-
Methods:-
enqueue():binaryheap容器上的insert。 -
dequeue():二进制容器上的delete。
-
-
Good:-
dequeue()是O(log(n))操作。
-
-
Not good:-
enqueue是O(log(n))操作。在PriorityQueue via DynamicArray和PriorityQueue via LinkedList中,此操作是O(1)。
-
- 编程语言实施:
- Java :PriorityQueue使用二进制堆作为内部数据结构。
- c#:PriorityQueue使用二进制堆作为内部数据结构。
协会收藏
关联集合是一种抽象数据类型,该数据类型存储(键,值)对的集合,确保每个可能的密钥最多出现在集合中。但是,对于这些类型的数据结构没有标准化的命名约定,导致不同编程语言的术语变化,这可能会引起混乱。协会集合的一些替代名称包括关联数组,地图,符号表或字典。参见here。
无序示意图或标签
其他名称是可掩盖的。标签背后的主要思想是使用哈希功能将键映射到数组中的特定存储桶或插槽。每个桶可以存储一个或多个键值对。哈希功能有时会为不同的密钥生成相同的索引,从而导致碰撞。为了有效地处理碰撞,可以使用各种策略来处理碰撞:
- 阵列中的每个存储桶都是键值对的链接清单。
- Open addressing
- 调整数组的大小。
对于大多数数据结构,线性搜索是O(n)或O(log(n))操作。 Hashtable是一种具有摊销O(1)时间复杂性的数据结构。散布的阵列长度是质数。

-
Good:-
O(1)用于搜索操作。
-
-
Not Good:- 收集没有订单。无随机访问。
- 如果用于碰撞处理的LinkedList:搜索最差的案例可以是
O(n)(所有节点碰撞)。平均案例不是O(1)。
- 编程语言实施:
- CPP :unordered_map是使用Hashtable创建的无序集合。另一个版本是unordered_multimap,它允许重复键。在unordered_map版本中,键是唯一的。
- Swift :Dictionary是使用Hashtable创建的无序集合。钥匙是唯一的。
- Python :dict是使用Hashtable创建的无序地图。另外,Counter是一个特定于值计数的字典(关键是您在字典中放置的项目,而值是计数器。在每个插入物上,如果存在值,则将1添加到计数中)。 UserDict是一个包装类类,可让您通过从用户界继承并实现某些方法来创建自己的字典式对象。它提供了一种方便的方式来创建类似自定义字典的类别,而无需直接将内置的dict类分类。 mappingproxy对象提供仅读取对原始字典数据的访问。
- java :HashTable是无序的,螺纹安全的。 HashMap是使用Hashtable创建的无序地图。
-
c#:Dictionary是使用Hashtable创建的无序地图。 ListDictionary使用阵列(用于键)和LinkedList(用于值)的组合。操作都是
O(n),必须用于小型收藏(少于10个项目)。 - JavaScript :Map是一张无序的地图。
通过Hashtable和LinkedList进行订购映射
键值对的集合。虽然保留了插入的顺序,但未对集合进行排序。

-
Good:- 保留了插入的顺序。 (与sortedmap不同,键未排序。)
-
accessDataBySequence是可能的。
-
Not Good:- 由于linkedlist。
- 高额外存储的高架用于前向和背部参考。
- 编程语言实施:
- python :OrderedDic是使用双重链接列表和词典的组合实现的。
- Java :LinkedHashMap。在Java中,LinkedHashmap类使用哈希表和双重链接列表的组合作为其内部数据结构,以提供可预测的迭代顺序的哈希地图的功能。
订购示意图通过Hashtable和DynamicArray
键值对的集合。虽然保留了插入的顺序,但未分类该集合。

-
Good:- 保留了插入的顺序。 (与sortedmap不同,键未排序。)
-
accessDataBySequence是可能的。 -
accessDataAtRandomIndex是O(1)。
-
Not Good:- 插入是由于数组而为
O(n)。 - 由于数组而删除是
O(n)。
- 插入是由于数组而为
- 编程语言实施:
- c#:OrderedDictionary使用了标签和arraylist的组合。
通过自我平衡树排序图
由密钥对键值对的集合。
-
Good:- 搜索是
O(log(n)) - 按键已排序。
- 搜索是
-
Not Good:- 随机访问不是
O(1)。 - 适合少量数据。
- 随机访问不是
- 编程语言实施:
- CPP :map使用红黑树进行实现。另一个版本是multimap,允许重复键。在map版本中,键是唯一的。
- swift :Swift使用树数据结构没有内置有序地图。您可以将字典的键对集合进行分类,并迭代该集合。
- python :Swift使用树数据结构没有内置有序地图。
- java :TreeMap使用红黑树作为内部数据结构实施。
-
c#:SortedDictionary是使用称为“红黑树”的自平衡二进制搜索树在内部实现的。 SortedList使用两个单独的数组。一个用于键,第二个用于值。由于按键的数组进行排序,当插入新项目时,可以通过二进制搜索找到索引。插入的时间复杂性是
O(n)。二进制搜索是O(log(n))和项目重新排序为O(n)。 - JavaScript :可以找到实现here。
放
UndrodeDSet
几乎完全像UnorderedMap or HashTable,其区别是节点只有一个键且不存在值。在Java中,它是使用Hashtable实现的,并且节点的值设置为固定值。
-
Good:-
O(1)用于搜索操作。
-
-
Not Good:- 收集没有订单。无随机访问。
- 如果用于碰撞处理的LinkedList:搜索最差的案例可以是
O(n)。平均案例不是O(1)。
-
编程语言实现:
- CPP :unordered_set是使用Hashtable创建的无序集合。另一个版本是unordered_multiset,它允许重复键。在unordered_set版本中,键是唯一的。
- Swift :Set是使用Hashtable创建的无序集合。钥匙是唯一的。
- Python :Set是使用Hashtable创建的无序集。 frozenset是一套不变的集合。
- java :HashSet是使用Hashtable创建的无序集。
- c#:HashSet是使用Hashtable创建的无序集。
- JavaScript :Set是无序的集合。
通过Hashtable和LinkedList进行订购
几乎完全像OrderedMap via HashTable and LinkedList,其区别是节点只有一个键且不存在值。在Java中,它是使用Hashtable实现的,并且节点的值设置为固定值。
-
Good:- 保留了插入的顺序。 (与Sortedset不同,键未排序。)
-
Not Good:- 由于linkedlist。
- 编程语言实施:
- Java :LinkedHashSet。在Java中,LinkedHashset类使用哈希表和双重链接列表的组合作为其内部数据结构,以提供具有可预测迭代顺序的哈希集的功能。
通过自我平衡树排序
-
Good:- 搜索是
O(log(n)) - 按键已排序。
- 搜索是
-
Not Good:- 随机访问不是
O(1)。 - 适合少量数据。
- 随机访问不是
- 编程语言实施:
标准库数据结构
C ++

迅速
可以找到here的Swift源代码。

CSHARP
可以找到集合的dotnet源代码here。

Python
可以找到Python内置类型的源代码here。收集模块源代码位于here。

爪哇
Java Collections源代码位于here。

非线性数据结构
即将来临
算法
即将来临