我在十年的大部分时间里一直沉迷于创建工作流引擎。从一组较小机器大军中构建“大型”机器的想法似乎从来没有变老。
在其核心上,工作流引擎负责在一组机器上执行一系列任务(通常称为“作业”,“管道”或“工作流”)(通常称为“工人”或节点)尽快,尽可能地有效。
构建工作流引擎带来了许多有趣的挑战。这是一个简短且高度不重的列表:
-
您用什么来作者工作流?您使用通用编程语言吗?诸如JSON或YAML之类的配置类型语言,还是您自己的DSL(特定域语言)?
-
我们如何确定哪些任务是到哪些工人,以至于忙碌的工人在其他人闲置时不会超负荷?
-
我们如何应对响应计算需求波动的缩放或降低能力的要求?
-
我们如何处理间歇性的任务失败?
-
我们如何处理工人崩溃?
-
我们如何处理一个与可用容量相比要执行更多任务的情况?
让我们在路上放一些橡胶
我第一次需要在为视频流启动工作时实际构建工作流引擎。当时,该公司将其所有视频处理需求外包给另一家公司。
现有过程缓慢,昂贵且易碎。该公司定期获得新内容(电影,预告片,奖金视频材料,封闭的字幕等),我们需要一种方法来快速处理此内容,以便在服务上供应客户享受。
此外,现有过程非常严格,并且任何更改(例如,引入新的音频技术)花费了几个月或根本不可能。我建议建立一个概念验证,这将使我们能够将工作带入内部,幸运的是,我的经理们对这个想法持开放态度。
在这一点上,您可能会问自己为什么要在那里有一百万个开源和商业选择时要成为一个?
是的,那里有many options。在决定自己建造一个之前,我们先看了很多数字。但是至少在当时(大致2014年),许多现有选项不是为分布式环境而设计的,而是为数据处理用例而设计,似乎被放弃了,或者只是对我们的口味进行了过多的设计。
工作流引擎的初始迭代使我们能够开始处理“低风险”内容,例如预告片,并且随着我们对新系统的信心,我们逐渐逐渐逐步消除旧过程。
后来,当一位同事留给另一家需要类似系统的媒体公司时,他问我是否想从头开始再做一次。自然,我同意了。我们的2.0在精神上相似,但是从旧设计中学到的许多经验教训都是在新设计中固定的。
认识托克
在为高度专业的用例构建了两个专有的工作流程引擎后,我有痒来看看其他公司(可能具有较大用例的公司)是否也可以从类似的系统中受益。所以我决定构建它的开源版本。
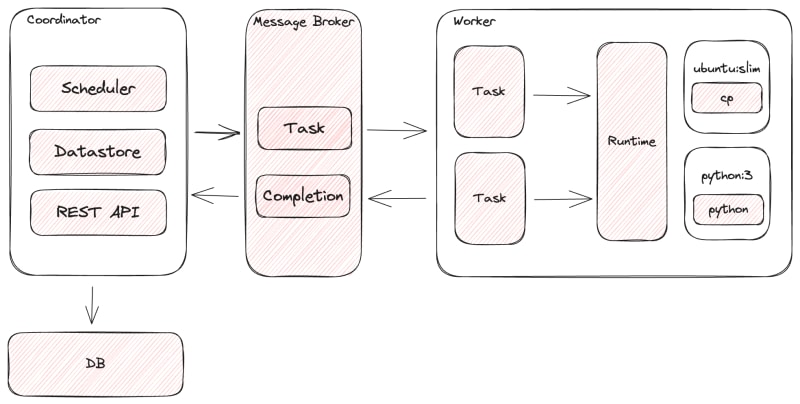
tork是一种基于golang的实现,其精神与其封闭源的前辈非常相似。它可以在笔记本电脑上以“独立”模式运行,也可以根据您的需要部署到大量机器上。
tork的主要组成部分是:
-
协调员:负责管理工作和任务的生命周期,将任务路由到合适的工人以及处理任务执行错误。
-
工作:根据协调员的说明负责执行任务。工人是无状态的,因此很容易添加和删除它们作为对容量变化的需求。
-
经纪人:协调员和工人节点之间的通信手段。
-
datastore :保持任务和工作状态。
-
Runtime :通过运行时执行任务,该运行时将任务转化为实际可执行文件。目前,由于其无处不在和大量图像库,仅支持Docker,但有计划在将来增加对Podman和Wasm的支持。
如果您有兴趣检查一下,可以在GitHub上找到该项目:
- Backend: https://github.com/runabol/tork
- Web UI: https://github.com/runabol/tork-web