在蓬勃发展的数据复杂性和高维信息的时代,传统数据库通常在有效地处理和从复杂的数据集中提取含义时通常不足。输入矢量数据库,这是一种技术创新,它已成为解决数据范围不断扩展的挑战的解决方案。
了解向量数据库
矢量数据库在各个领域都具有重要的重要性,因为它们具有有效存储,索引和搜索高维数据点的独特能力,通常称为向量。这些数据库旨在处理每个条目在多维空间中表示为向量的数据。向量可以代表广泛的信息,例如数值特征,文本或图像的嵌入,甚至是分子结构等复杂数据。
让我们使用2D网格表示矢量数据库,其中一个轴代表动物的颜色(棕色,黑色,白色),另一个轴表示大小(小,中等,大)。
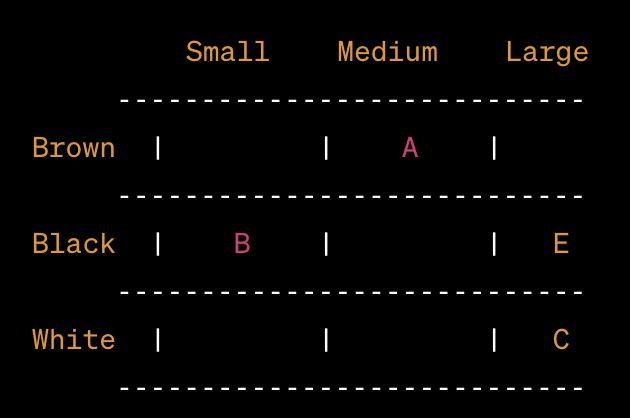
在此表示中:
- 图像A:棕色,中型
- 图像B:黑色,小尺寸
- 图像C:白色,大尺寸
- 图像E:黑色,大尺寸
您可以将每个图像视为基于其颜色和尺寸属性在此网格上绘制的点。该简化的网格捕获了如何以视觉表示向量数据库的本质,即使实际的向量空间可能具有更多的维度并使用复杂的技术进行搜索和检索。
解释诸如i M 5之类的向量数据库
想象您有很多不同类型的水果,例如苹果,橙子,香蕉和葡萄。您喜欢苹果的味道,并希望找到其他类似于苹果的水果。您决定根据它们的糖果或酸味来分组它们,而不是通过其颜色或尺寸对水果进行排序。

因此,您将所有甜美的水果都放在一起,例如苹果,葡萄和成熟的香蕉。您将酸果放在另一组,例如橙子和未成熟的香蕉。现在,当您想找到像苹果一样味道的水果时,您只会看一组甜美的水果,因为它们更有可能具有类似的味道。
但是,如果您正在寻找特定的东西,例如像苹果一样甜但味道像橙色一样甜的水果怎么办?在您的小组中可能很难找到,对吗?那时,您问一个对不同水果了解很多的人,例如水果专家。他们可以建议一种与您独特的口味请求相匹配的水果,因为他们知道许多水果的口味。
在这种情况下,知识渊博的人的行为就像“向量数据库”。他们有很多有关不同水果的信息,可以帮助您找到适合您特殊口味的信息,即使它不是基于颜色或形状等通常的东西。
同样,矢量数据库就像对计算机的有用专家一样。它旨在以一种特殊的方式记住有关食物等事物的许多细节。因此,如果您正在寻找一种与您喜欢的食物相似的食物,或者您正在寻找一种享受风味的食物,那么该矢量数据库可以很快找到适合您的选择。这就像拥有一个了解所有知识的计算机的风味专家,并且可以根据您的渴望提出一个很好的选择,就像那些知识渊博的人一样。
向量数据库如何存储数据?
矢量数据库使用向量嵌入来存储数据。向量数据库中的向量嵌入是指表示对象(例如项目,文档或数据点)作为多维空间中的向量的方式。每个对象都被分配一个向量,该向量捕获该对象的各种特征或特征。这些向量的设计方式使得相似的对象具有在矢量空间中彼此靠近的向量,而不同的对象则具有较远的向量。

将矢量嵌入方式视为描述对象重要方面的特殊代码。想象一下,您有不同的动物,您想以类似动物具有相似代码的方式代表它们。例如,猫和狗的代码可能非常接近,因为它们具有共同的特征,例如四足和毛皮。另一方面,鱼类和鸟类等动物的代码将进一步分开,以反映它们的差异。
在向量数据库中,这些嵌入用于存储和组织对象。当您想找到与给定查询类似的对象时,数据库会查看嵌入式并计算查询的嵌入与其他对象的嵌入之间的距离。这有助于数据库快速识别与查询最相似的对象。
例如,在音乐流应用程序中,歌曲可以用嵌入捕获节奏,流派和所使用的乐器等音乐功能的嵌入方式表示为向量。当您搜索类似于您喜欢的曲目的歌曲时,该应用程序的矢量数据库将比较嵌入方式以查找与您的偏好密切相匹配的歌曲。
向量嵌入是一种将复杂的对象变成捕获其特征的数值向量的方法,并且向量数据库使用这些嵌入来根据其在矢量空间中的位置有效地搜索和检索相似或相关的对象。
向量数据库如何工作?
 图像学分 :KDnuggets
图像学分 :KDnuggets
用户查询:
- 您将问题或请求输入chatgpt应用程序。
嵌入创建:
- 应用程序将您的输入转换为称为向量嵌入的紧凑数值形式。
- 这种嵌入将查询的本质捕获在数学表示中。
数据库比较:
- 将向量嵌入与矢量数据库中存储的其他嵌入。
- 相似性措施有助于根据内容确定最相关的嵌入。
输出生成:
- 数据库生成的响应由嵌入式组成,与查询的含义紧密匹配。
用户响应:
- 包含链接到已确定嵌入的相关信息的响应已发送给您。
后续查询:
- 当您进行后续查询时,嵌入模型会生成新的嵌入。
- 这些新的嵌入方式用于在数据库中找到类似的嵌入,并将其连接回原始内容。
向量数据库如何知道哪些向量相似?
vector数据库使用各种数学技术确定向量之间的相似性,其中最常见的方法之一是余弦相似性。
当您在Google上搜索“世界上最好的板球运动员”时,它显示了顶级玩家列表时,涉及几个步骤,其中余弦相似性是主要的。
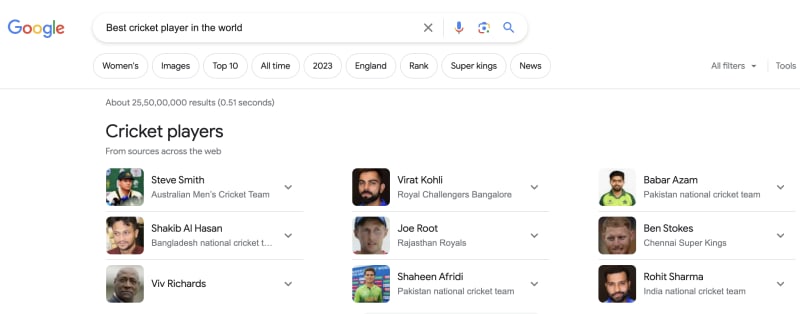
使用余弦相似性将搜索查询的向量表示与数据库中所有播放器配置文件的向量表示。向量越相似,余弦相似性得分就越高。
注意:嗯,这只是为了一个例子。重要的是要注意,诸如Google之类的搜索引擎使用超越简单向量相似性的复杂算法。他们考虑了各种因素,例如用户的位置,搜索历史记录,来源的权威等,以提供最相关和个性化的搜索结果。
向量数据库功能
向量数据库的重要性在于其功能和应用:
- 有效的相似性搜索:
向量数据库在执行相似性搜索方面表现出色,您可以在其中检索与给定查询向量最相似的向量。这在各种应用中至关重要,例如推荐系统(查找类似的产品或内容),图像和视频检索,面部识别和信息检索。
- 高维数据:
传统的关系数据库由于“维度的诅咒”而与高维数据进行了努力,其中数据点之间的距离随着维数的数量的增加而变得不那么有意义。矢量数据库旨在更有效地处理高维数据,使其适用于自然语言处理,计算机视觉和基因组学等应用。
- 机器学习和AI:
向量数据库通常用于存储机器学习模型生成的嵌入。这些嵌入捕获数据的基本特征,可用于各种任务,例如聚类,分类和异常检测。
- 实时应用程序:
许多矢量数据库已针对实时或近实时查询进行了优化,使其适用于需要快速响应的应用程序,例如电子商务,欺诈检测和监视IoT传感器数据的推荐系统。
- 个性化和用户分析:
向量数据库通过允许系统理解和预测用户偏好来启用个性化的体验。这对于流媒体服务,社交媒体和在线市场等平台至关重要。
- 空间和地理数据:
向量数据库可以有效地处理地理数据,例如点,线和多边形。这对于诸如地理信息系统(GIS),基于位置的服务和导航应用程序等应用程序至关重要。
- 医疗保健和生命科学:
在基因组学和分子生物学中,媒介数据库用于存储和分析遗传序列,蛋白质结构和其他分子数据。这有助于药物发现,疾病诊断和个性化医学。
- 数据融合和集成:
向量数据库可以集成来自各种来源和类型的数据,从而实现更全面的分析和见解。这在数据来自多种模式(例如结合文本,图像和数值数据)的情况下很有价值。
- 多语言搜索:
矢量数据库可用于通过将文本文档表示为公共空间中的向量来创建强大的多语言搜索引擎,从而实现跨语言相似性搜索。
- 图数据:
向量数据库可以有效地表示和处理图数据,这对于社交网络分析,建议系统和欺诈检测至关重要。
矢量数据库在当今数据格局中的关键作用
矢量数据库的需求很高,因为它们在应对现代应用中高维数据爆炸带来的挑战中的重要作用。
随着行业越来越多地采用机器学习,人工智能和数据分析等技术,有效存储,搜索和分析复杂数据表示的需求已变得至关重要。向量数据库使企业能够利用相似性搜索,个性化建议和内容检索的力量,推动增强的用户体验并改善决策。
应用程序从电子商务和内容平台到医疗保健和自动驾驶汽车,对矢量数据库的需求源于其处理多种数据类型并实时提供准确结果的能力。随着数据继续增长,矢量数据库提供的可扩展性,速度和准确性将它们定位为提取有意义的见解并解锁各个领域的新机会的关键工具。
SINGLESTORE作为向量数据库:
利用SingleStoreDB的强大矢量数据库功能,该功能是无缝量身定制的,可为AI驱动的应用程序,聊天机器人,图像识别系统等。借助您可以使用SinglestoredB,为您的向量密集型工作负载维护专用矢量数据库的必要性已过时。

与常规矢量数据库方法分歧,SinglestoredB通过将矢量数据与不同的数据类型一起使用,通过将矢量数据包含在关系表中,采用了一种新颖的方法。这种创新的合并使您能够毫不费力地访问与矢量数据有关的其他属性,同时利用了SQL的广泛查询能力。
SinglestoredB已通过可扩展的框架进行了精心构建,从而确保了对您迅速发展的数据要求的不变支持。告别限制,并接受与您的数据要求同时增长的解决方案。
与SQL匹配的示例
我们在此表中加了16,784,377行:
create table people(
id bigint not null primary key,
filename varchar(255),
vector blob
);
每行代表名人的一个图像,并包含一个唯一的ID号,图像存储的文件名和一个128元素的浮点矢量代表面部的含义。该向量是使用FaceNet获得的,FaceNet是一种预先训练的神经网络,用于从面部图像创建向量嵌入。
不用担心,您不需要了解AI即对象。
现在,我们使用:
查询此表
select vector
into @v
from people
where filename = "Emma_Thompson/Emma_Thompson_0001.jpg";
select filename, dot_product(vector, @v) as score
from people where score > 0.1
order by score desc
limit 5;
第一个查询获取图像emma_thompson_0001.jpg的查询向量@V。第二个查询找到了最接近的五个最接近的比赛:

emma_thompson_0001.jpg是自身的完美匹配,因此得分接近1。但有趣的是,下一个最接近的匹配是emma_thompson_0002.jpg。这是查询图像和最接近的匹配:

此外,我们获得的搜索速度确实令人难以置信。第二张查询仅在16 VCPU机器上花费了0.005秒。它处理了所有16m的向量。这是每秒超过33亿个向量匹配的速率。
在原始文章中了解了有关此实验的更多信息。
Image Matching in SQL With SingleStoreDB
现在,是时候让您与Singlestore一起玩了。
Sign up to SigleStore & claim your $600 worth of free usage.
向量数据库的重要性源于它们处理复杂,高维数据的能力,同时提供有效的查询和检索机制。随着数据的复杂性和数量的持续增长,矢量数据库在各个行业的广泛应用中变得越来越重要。
注释和免责声明:我在撰写本文的某些部分时掌握了Chatgpt的帮助。