没有人可以否认 chatgpt 将大型语言模型(LLMS)带入了公众关注的焦点。虽然LLM并不完美,但是当您考虑一下时,提出各种各样的问题并在几秒钟内获得答案的能力是令人震惊的。 ðÖ
唯一剩下的就是以某种方式将其连接到您自己的数据,并为LLM提供了新的上下文,以从中获得答案。这是文本嵌入,向量数据库和语义搜索进来的地方。但是,根据您的用例,实现了整个堆栈为AI搜索或问答(Q&A)的界面类型的接口可能是一个挑战。
随着最新的更新, vrite open-source technical content management platform我现在正在研究内置搜索 和Q&A功能可以找到回答与您的内容有关的所有问题。两者都可以通过新的命令调色板和外部通过API进行。 -
这可以用来轻松为您的博客构建一种新的搜索体验,或在产品文档中为用户问题提供答案。
为您提供一个有趣的例子,我们将经历一个从 dev.to api 中导入内容的过程使用VRITE API在您自己的网站上实现语义搜索。
配置
让我们开始进入Vrite。您可以使用the hosted version(vrite在beta中免费)或来自the source code的自主vrite(带有更好的自我托管支持coming soon)
要将您的Dev.to Content Collection导入Vrite,最好在专用的工作区中这样做。在VRITE中,您可以使用工作区分开不同的项目或团队。要创建一个新的,从侧边栏中转到 workspace 部分。

从这里开始,您可以在不同的工作区之间创建和切换。为您的Dev.to Blog创建一个并切换到它。
准备好工作空间,您必须在vrite和dev.to中创建一个新的 api代币
要在vrite中获得一个,请转到 settings side面板 api 段 - 单击 新的API Token 。从这里,您必须配置新令牌的详细信息和权限。请确保选择 Write 对两个内容部分的权限和内容组 ,因为这是导入内容的必要条件。
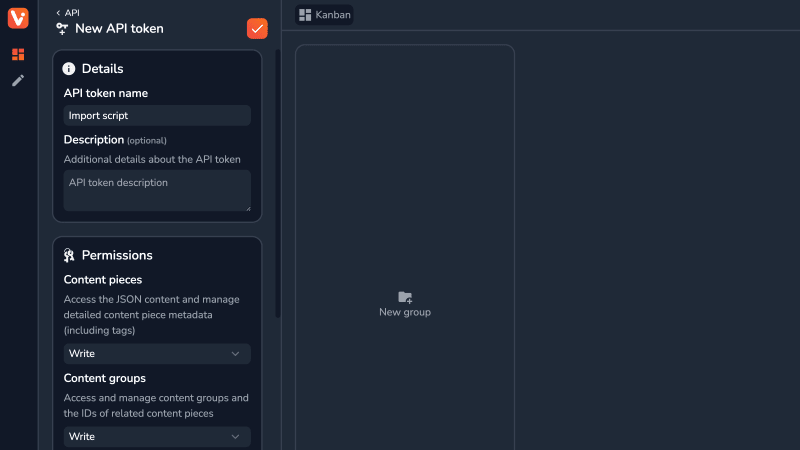
创建它后,将令牌存储在安全的地方 - 您将无法再次看到它。
要从dev.to获取API键,转到Settings → Extensions dev community api keys 节提供了描述,然后单击生成API键。

您可以随时看到您的API键,尽管您仍然应该确保其安全。
从dev.to导入内容
准备好API令牌,现在该准备一个导入脚本了。
使用node.js(v18或更新)和NPM安装,初始化一个新项目,安装Vrite SDK,然后创建主import.mjs文件。
npm init -y
npm install @vrite/sdk
touch import.mjs
在import.mjs中,让我们首先创建一个函数来从dev.to.to.
获取您的文章
const VRITE_API_TOKEN = "...";
const DEV_API_KEY = "...";
const getDevArticles = async (perPage = 1000) => {
const response = await fetch(
`https://dev.to/api/articles/me/published?per_page=${perPage}`,
{
headers: {
accept: "application/vnd.forem.api-v1+json",
"api-key": DEV_API_KEY,
},
}
);
const data = await response.json();
return data.reverse();
};
v18,Node.js提供了类似于Web浏览器的fetch() API,这使得处理网络请求变得更加容易。将其与适当的URL和标题一起向User's published articles端点提出请求。
dev.to api实现分页,最大值为1000,因此单个请求应该足以为大多数(如果不是全部)用户检索所有文章。
要实际将内容导入Vrite,让我们创建一个单独的函数。
import { createClient } from "@vrite/sdk";
import { gfmInputTransformer } from "@vrite/sdk/transformers";
// ...
const importToVrite = async (numberOfArticles) => {
const articles = await getDevArticles(numberOfArticles);
const client = createClient({
token: VRITE_API_TOKEN,
});
const { id: contentGroupId } = await client.contentGroups.create({
name: "My Dev.to Articles",
});
for await (const article of articles) {
const {
title,
body_markdown,
published_at,
cover_image,
canonical_url,
url,
} = article;
const { content } = gfmInputTransformer(body_markdown);
try {
await client.contentPieces.create({
contentGroupId,
title,
cover_image,
canonicalLink: canonical_url || url,
content,
coverUrl: cover_image,
date: published_at,
members: [],
tags: [],
});
console.log(`Imported article: "${title}"`);
} catch (error) {
console.error(`Could not import article: "${title}"`, error);
}
}
};
node.js的新版本中的.mjs扩展名允许使用ESM import语法的框使用,我们用来导入vrite sdk和gfmInputTransformer。
vrite SDK提供了一些内置输入和输出变压器。这些是功能,具有标准化的签名,可处理从VRITE和VRITE中的内容。在这种情况下,gfmInputTransformer本质上是GitHub Flavored Markdown解析器,在引擎盖下使用Marked.js。
在importToVrite()函数中,我们首先使用以前讨论的机制从DEV中检索文章,并初始化VRITE API客户端。从那里开始,我们创建了一个新的内容组,用于使用for await对进口文章的内容进行循环,从而从中创建新的内容。
创建的作品包括转换后的内容和一些来自Dev.to的额外的元数据,以轻松识别单个零件。
这样,您所要做的就是将importToVrite()函数与您的最新开发仪数进行调用,以导入并观看它!这是整个脚本:
import { createClient } from "@vrite/sdk";
import { gfmInputTransformer } from "@vrite/sdk/transformers";
const VRITE_API_TOKEN = "...";
const DEV_API_KEY = "...";
const getDevArticles = async (perPage = 1000) => {
const response = await fetch(
`https://dev.to/api/articles/me/published?per_page=${perPage}`,
{
headers: {
accept: "application/vnd.forem.api-v1+json",
"api-key": DEV_API_KEY,
},
}
);
const data = await response.json();
return data.reverse();
};
const importToVrite = async (numberOfArticles) => {
const articles = await getDevArticles(numberOfArticles);
const client = createClient({
token: VRITE_API_TOKEN,
});
const { id: contentGroupId } = await client.contentGroups.create({
name: "My Dev.to Articles",
});
for await (const article of articles) {
const {
title,
body_markdown,
published_at,
cover_image,
canonical_url,
url,
} = article;
const { content } = gfmInputTransformer(body_markdown);
try {
await client.contentPieces.create({
contentGroupId,
title,
cover_image,
canonicalLink: canonical_url || url,
content,
coverUrl: cover_image,
date: published_at,
members: [],
tags: [],
});
console.log(`Imported article: "${title}"`);
} catch (error) {
console.error(`Could not import article: "${title}"`, error);
}
}
};
importToVrite(20);
搜索和问答vrite仪表板
现在,在Vrite中的内容中,让S返回仪表板,看看如何使用命令调色板在Vrite中直接搜索。
与Vrite的协作支持相结合时,内置的搜索和命令调色板可以用作内部知识库时作为一个很好的工具。
打开调色板使用⌘K(在macOS上),Ctrl K(在Windows或linux上)或仪表板工具栏中的搜索按钮。

命令调色板有3种模式:
-
搜索默认值,在输入时提供结果;
-
命令可以通过在空搜索中键入
>或单击右下角的命令按钮来启用;可以快速访问当前视图中可用的各种操作;您可以通过在空输入中使用Backspace来返回搜索模式; -
询问/问答可以通过单击右上角中的 ask 按钮来启用;输入您的问题,然后单击
Enter以请求答案;
尝试搜索任何术语,并查看您的各种dev.to博客文章的结果。

vrite索引了您的内容部分的整个部分,该部分由标题和一组标题识别。这允许LLM从内容中提取最语义的含义,从而使矢量搜索可以为您的查询提供更好的搜索结果。因此,构建帖子越好,搜索结果就会越好。
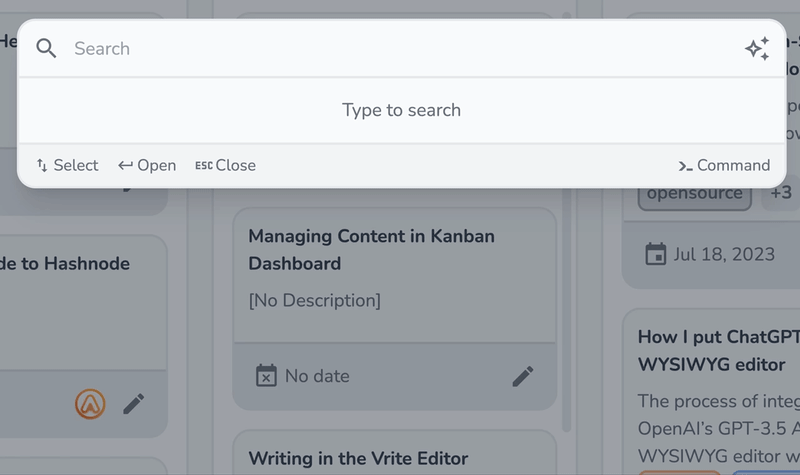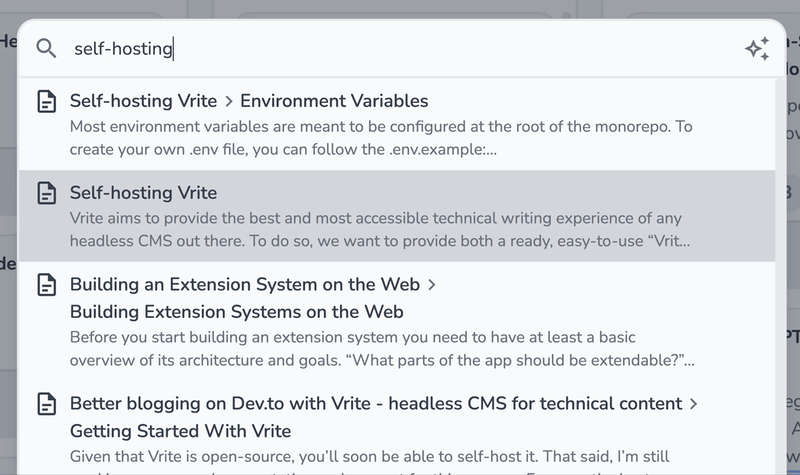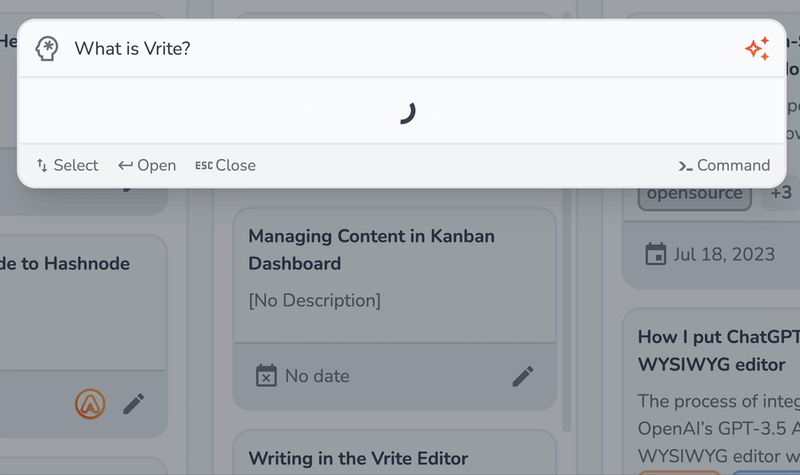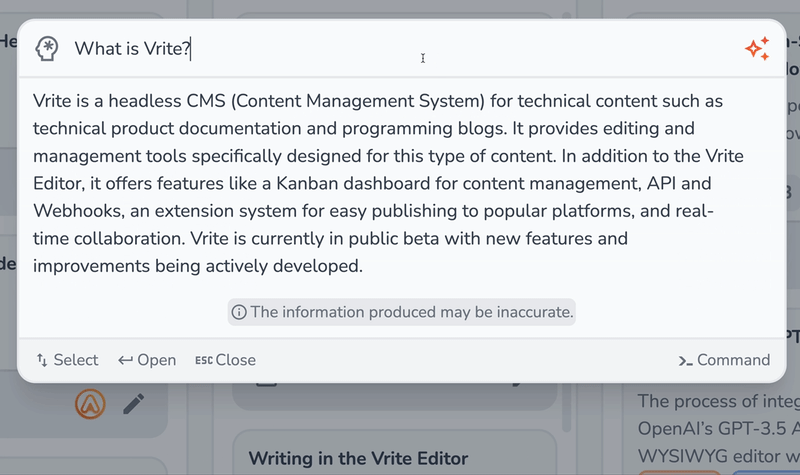
您也可以尝试问答模式,询问您内容中应该有答案的任何问题。提交后,该提示与上下文一起发送,供GPT-3.5生成答案,该答案流回到命令调色板。
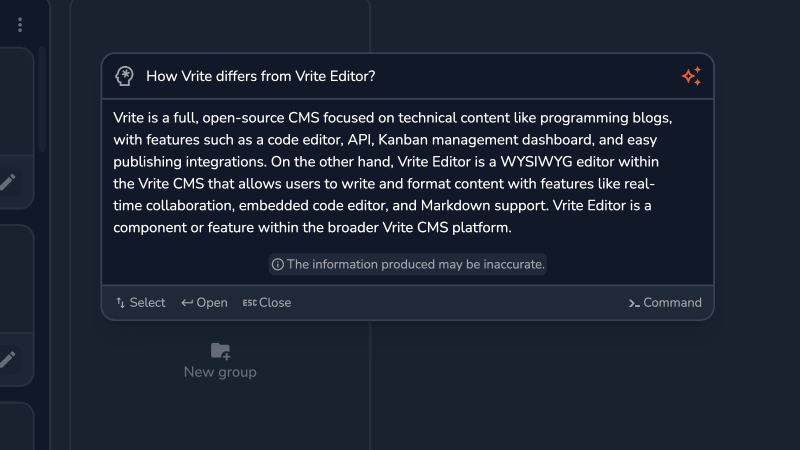
就个人而言,我对问答的表现给我留下了深刻的印象。即使是需要阅读几片的答案,也可以在几秒钟内准确生成。不过,您应该记住,这种情况永远不会是这样。
搜索和问答通过VRITE API
现在,通过Vrite的命令调色板进行搜索是不错的,但是真正的乐趣是在您可以通过 vrite api 。 P>
首先,由于CORS和安全考虑因素,您必须通过自己的后端或无服务器功能进行代理API搜索(尤其是如果您的令牌具有功能强大的权限)。为此,您必须从node.js。
访问vrite api搜索
首先,请确保具有至少 read 访问内容件的API令牌。因此,您可以使用API客户端的search()方法检索结果。
import { createClient } from "@vrite/sdk";
const VRITE_API_TOKEN = "...";
const search = async (query) => {
const client = createClient({
token: VRITE_API_TOKEN,
});
const results = await client.search({ query });
console.log(results);
};
search("Dev.to");
搜索结果是一个对象数组,每个对象包含:
-
contentPieceIdi id相关内容件; -
breadcrumb- 标题和通往该部分的标题和标题; -
content; 的纯文本内容
您可以作为JSON数组直接处理或将这些结果直接发送到前端。
问答
问答要困难得多。由于与GPT-3.5的时间相关的缓慢响应需要生成答案,因此/search/ask端点是通过Server Sent Events(SSE)(SSES)实现的,以将答案传输给用户,从而允许他们在重新查看第一个令牌后立即看到第一个令牌。准备就绪。
vrite SDK还没有支持SSE流媒体,因此,就目前而言,您必须自己实施。使用eventsource库或与端点连接并流式传输答案。
const streamAnswer = async (query) => {
try {
const source = new EventSource(
`https://api.vrite.io/search/ask?query=${encodeURIComponent(query)}`,
{
headers: { Authorization: `Bearer ${VRITE_API_TOKEN}` },
}
);
let content = "";
return new Promise((resolve, reject) => {
source.addEventListener("error", (event) => {
if (event.message) {
return reject(event.message);
} else {
source.close();
return resolve(content);
}
});
source.addEventListener("message", (event) => {
content += decodeURIComponent(event.data);
});
});
} catch (error) {
console.log(error);
}
};
streamAnswer("What is Dev.to?").then((answer) => {
console.log(answer);
});
该示例加载了整个答案,然后分解Promise。您可以直接使用此方法,但是每个请求的响应时间将在几秒钟内计数。
为了提供更好的用户体验(UX),您可能希望将来自VRITE API的事件转发到后端到前端,用户将看到答案的第一个令牌看起来更快。此实施将取决于您的后端框架,但是一般的方法是在数据进来时编写text/event-stream响应。在这里,good overview of the general process。
我正在努力在未来几周内更好地记录和支持此过程。
底线
虽然AI搜索本身确实很棒,但有关VRITE的最好部分是搜索只是更大整体的一小部分。有了看板内容管理, wysiwyg 技术内容编辑,Git sync和扩展 。只需拖动 - 我们只刮擦了可能的表面!
现在,Vrite目前正在Beta中,仍然有要解决的错误,并且要添加和充实的新功能。如果您想提供帮助和支持该项目,请leave a star on GitHub并报告您遇到的任何问题或错误。在您的支持下,我希望将VRITE成为首选的开源技术内容平台ð¥
ð¥ Try out Vrite
â¹ï¸ Documentation
ð¬ Join Discord
ð¦ Follow on Twitter
ð¼ Follow on LinkedIn