上一篇文章 - Using AI to Simplify Clinical Documents Storage, Retrieval and Search
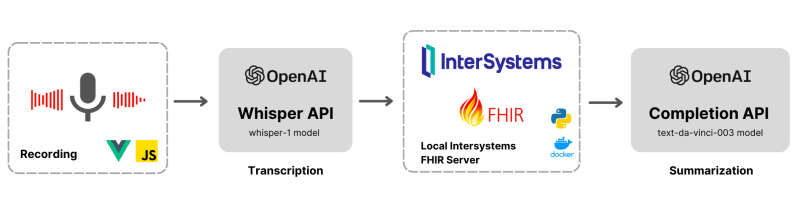
这篇文章探讨了OpenAI高级语言模型通过AI驱动的转录和总结彻底改变医疗保健的潜力。我们将深入研究利用Openai的尖端API将录音转换为书面成绩单,并采用自然语言处理算法来提取关键见解以产生简洁的摘要。
。虽然诸如亚马逊医学转录和MedVoice之类的现有解决方案提供了类似的功能,但本文的重点将是使用Intersystems in Intersystems fhir中实施这些强大功能。
在vue.js上录制音频
vue.js应用程序上的语音录音机如果完全本地,并使用JavaScript中的Mediarecorder接口编写。这样做是为了使应用程序轻巧,还可以完全控制录制选项。以下是要开始和停止录制音频输入的摘要。
// Start recording method that stores audio stream as chunks
async startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: true,
});
this.mediaRecorder = new MediaRecorder(stream);
this.mediaRecorder.start();
this.mediaRecorder.ondataavailable = (event) => {
this.chunks.push(event.data);
};
this.isRecording = true;
} catch (error) {
console.error("Error starting recording:", error);
}
}
// Stop recording method that creates a blob after stop (and calls the transcription method)
stopRecording() {
if (this.mediaRecorder) {
this.isLoading = true;
this.mediaRecorder.stop();
this.mediaRecorder.onstop = async () => {
const blob = new Blob(this.chunks, {
type: "audio/webm;codecs=opus",
});
await this.sendAudioToWhisper(
new File([blob], `file${Date.now()}.m4a`)
);
this.getSummary(this.transcription);
};
}
}转录组件
使用OpenAI的耳语模型对音频数据进行转录涉及几个基本组件。以下代码段演示了转录过程中涉及的步骤。
const apiKey = process.env.OPENAI_API_KEY;
const formData = new FormData();
formData.append("file", blob);
formData.append("model", "whisper-1");
formData.append("response_format", "json");
formData.append("temperature", "0");
formData.append("language", "en");
try {
const response = await fetch(
"https://api.openai.com/v1/audio/transcriptions",
{
method: "POST",
headers: {
Accept: "application/json",
Authorization: `Bearer ${apiKey}`,
},
body: formData,
redirect: "follow",
}
);
const data = await response.json();
if (data.text) {
this.transcription = data.text;
}
} catch (error) {
console.error("Error sending audio to Whisper API:", error);
}
return this.transcription;-
api键 -
OPENAI_API_KEYâ是访问OpenAi API的必需身份验证令牌。 -
形式数据 - 要转录的音频文件附加到
FormData对象。还包括其他参数,例如所选模型whisper-1,响应格式(json),温度(`), and language (en`)。 -
API请求 - 使用指定的标头和包含表单数据的主体向OpenAI API端点
https://api.openai.com/v1/audio/transcriptions发送邮政请求。 -
响应处理 - 捕获API的响应,并从
data对象中提取转录的文本。转录可以分配给可变的this.transcription,以进行进一步处理或使用。
摘要组件
以下代码段展示了使用OpenAI的text-davinci-003模型中的文本摘要过程中涉及的核心组件。
response = openai.Completion.create(
model="text-davinci-003",
prompt="Summarize the following text and give title and summary in json format. \
Sample output - {\"title\": \"some-title\", \"summary\": \"some-summary\"}.\
Input - "
+ text,
temperature=1,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=1
)
return response["choices"][0]["text"].replace('\n', '')-
模型选择 -
model参数设置为text-davinci-003,表明使用OpenAI的文本完成模型进行摘要。 - 提示 - 提供给模型的提示指定所需的结果,即汇总输入文本并以JSON格式返回标题和摘要。输入文本与提示进行处理。有趣的是,我们如何通过Openai处理响应转换。仅在接收端的验证就足够了,我们将来几乎不需要转换器。
-
生成参数 - 诸如
temperature,max_tokens,top_p,frequency_penalty和presence_penalty等参数将控制生成的摘要的行为和质量。 -
API请求和响应处理 -
openai.Completion.create()方法被调用以提出API请求。捕获响应,并从响应对象中提取生成的摘要文本。在返回最终结果之前,在摘要文本中删除了任何newline字符(\n)。
FHIR中的文档参考
在使用OpenAI Technologies实施医生对话转录和汇总的背景下,一个重要的考虑是在FHIR标准中存储临床笔记。 FHIR提供了一种结构化和标准化的方法,用于在不同的医疗保健系统和应用中交换医疗保健信息,包括临床笔记。 FHIR中的Document Reference资源是存储临床注释和相关文档的专用部分。
将转录和摘要功能集成到医生的对话工作流程中时,可以在FHIR文档资源中将结果记录和摘要作为临床注释存储。这可以轻松访问,检索和共享医疗保健提供者和其他授权实体之间的生成见解。
{
"resourceType": "Bundle",
"id": "1a3a6eac-182e-11ee-9901-0242ac170002",
"type": "searchset",
"timestamp": "2023-07-01T16:34:36Z",
"total": 1,
"link": [
{
"relation": "self"&,
"url": "http://localhost:52773/fhir/r4/Patient/1/DocumentReference"
}
],
"entry": [
{
"fullUrl": "http://localhost:52773/fhir/r4/DocumentReference/1921",
"resource": {
"resourceType": "DocumentReference",
"author": [
{
"reference": "Practitioner/3"
}
],
"subject": {
"reference": "Patient/1"
},
"status": "current",
"content": [
{
"attachment": {
"contentType": "application/json",
"data": ""
}
}
],
"id": "1921",
"meta": {
"lastUpdated": "2023-07-01T16:34:33Z",
"versionId": "1"
}
},
"search": {
"mode": "match"
}
}
]
}试试看
- 克隆项目 - 从以下github链接中克隆项目存储库:https://github.com/ikram-shah/iris-fhir-transcribe-summarize-export。
- 本地设置 - 按照提供的说明在计算机上本地设置该项目。让我们知道您是否在设置过程中遇到任何问题。
- 选择患者 - 从项目中提供的样本列表中选择患者。该患者将与医生对话进行转录和摘要有关。
- 交互页面 - 一旦选择患者,请导航到项目中的“交互”页面。在此页面上,找到并单击“记笔记”选项,以启动医生对话的转录过程。
- 视图和编辑转录 - 转录过程完成后,将提供一个选项以查看生成的转录。您还可以编辑与转录相关的标题和摘要,以获得更好的组织和清晰度。
- 保存到FHIR文档参考 - 最终确定标题和摘要后,保存更改将自动将其存储在FHIR文档参考中。这样可以确保捕获相关的临床笔记并与各自患者的记录相关联。当前,该项目不能保存整个转录文本。但是,可以修改它以包括完整转录的存储。
演示
在此处观看整个应用程序的演示-https://youtu.be/3Th6bR4rw0w
未来发展方向
扩大AI驱动的转录和摘要在远程医疗通信中的应用具有巨大潜力。将这些功能与Zoom,Teams和Google Meet等流行的会议平台相结合可以简化远程医生互动。远程医疗会议的自动转录和汇总提供了诸如准确的文档和增强分析之类的好处。但是,数据隐私仍然是一个至关重要的挑战。为了解决这个问题,在将数据传输到外部服务器之前实施量度过滤或匿名的个人身份信息(PII)是必不可少的。
未来的方向包括探索用于本地处理的设备AI模型,改进了对多语言交流的支持以及隐私保护技术的进步。
如果您觉得此实现有用,请考虑在2023年的voting for this app。