欢迎回到golang Saga的第三部分:编码器的旅程再次回到。可视化器,使用GO作为我选择的编程语言。在第二个part中,我们深入研究了数据探险,探索了CDO中可用的数据格式和过滤器。现在,是时候深入研究可视化了。在本章中,我将重点介绍使用Tel Aviv的CDO数据在GO中创建图形,跨越1939年至2023年。我们将探索各种技术以有效说明气候变化模式。
作为快速提醒,在上一篇文章中,我们选择了以下图表来说明气候变化模式:
-
散点图,说明了这些年平均最低和最高温度如何变化。
-
热图可视化年平均温度。
-
温度异常图显示了整个年份的平均温度变化,并将其与所选基线进行比较。
-
使用彩色条纹代表每年平均温度的气候变化条纹。
让我们继续这次编码冒险,并通过Go探索可视化的世界!本文中使用的所有代码都可以在此repository中找到。
主角发现数据世界并不完美的一章
在进行可视化过程之前,让我们重新访问我们为特拉维夫下载的数据。作为快速提醒,CSV看起来像这样:
此外,我在此CSV文件中复制了来自另一个站的数据示例:
正如我们从第二篇文章中回忆起的那样,我们要求从四个不同站点进行每日温度记录。但是,即使从那些行中,我们也可以观察到缺少某些数据,这是由TAVG,TMAX和TMIN列中的空值表示的。这增加了数据集中可能有更多丢失值的可能性。

为了更好地了解丢失的数据,我们的下一步是创建一个可视化整体情况的图。我认为,每个站的分组条形图,其中TAVG,TMAX和TMIN的空值总和是值,将是为此目的的合适选择。
为了在本文中构建图,我将使用Gonum/Plot库,该库提供了一系列用于生成不同类型的图表和图形的工具。虽然我是Gonum/Plot的新手,但我认为它有可能随着时间的流逝有效地展示温度趋势和模式。
您可以在终端中使用以下命令获取gonum/plot:
go get gonum.org/v1/plot/...
作为快速提醒,在上一篇文章中,我创建了一个带有GO内核的Jupyter笔记本,我在其中阅读了CSV文件并将数据存储在缓存中。现在,我可以在此笔记本的其他单元格中使用缓存的CSV_RECORD变量,该变量可以更轻松地进行数据操作和可视化,而无需每次都重新加载数据。
现在,我的下一个任务是计算CSV文件中的空TAVG,TMAX和TMIN值的数量。在制定代码时,我有机会探索和理解GO中的map数据类型。让我们仔细研究下面的代码:
您可以看到,我定义了一个名为StationData的数据结构,该数据结构代表有关气象站的信息,包括其名称以及TAVG(平均温度),TMAX(最高温度)和TMIN的缺失值数量(最小)温度)数据。
然后,我创建了一个称为count_missing_data的函数,该函数采用代表天气记录的二维字符串(数据)。在此功能内部,我使用地图(stity图)存储了每个唯一站名称的stationdata对象。
接下来,我在CSV数据中的每个记录中循环并提取了站名称。然后,我计算了每个记录中TAVG,TMAX和TMIN的缺失值数,并更新了StationData对象中的相应字段。
结果,我在高速缓存中有stations_counts变量,显示每个天气站缺少TAVG,TMAX和TMIN值的数量:
[{ISE00100468 3521 198 201} {IS000002011 3560 45 45} {ISE00105694 6478 96 375} {ISM00040180 0 2202 4735}]
现在,使用此地图,我们准备为每个电台创建一个组条图表,以找出哪个电台最适合每种类型的值。我在gonum/plot上找到了一个有用的tutorial,所以我要使用plotter.newbarchart出于我的目的。
在上面的代码中,我设置了三个组,groupa,groupb和groupc,分别存储每个站缺失的TAVG,TMAX和TMIN值的计数。然后,我为三组数据创建了三个带有不同颜色的条形图,Barsa,Barsb和Barsc。我将这三个条形图添加到图p。
代码的最后一部分负责将图作为png图像呈现,并直接在jupyter笔记本中显示。它使用gonum/plot的writerto方法来生成图像,然后使用gonbui.displaypng函数显示图像。

从上面的图中,我们可以看到iSM00040180站具有TAVG值的最佳数据可用性(红色栏几乎是看不见的),但对于TMAX和TMIN值不佳。另一方面,其他电台显示了相反的模式,具有更好的TMAX(绿色条)和TMIN(蓝色条)的数据,但TAVG的数据较少。
那时,我只专注于检查数据集中的空值。但是,可能还有其他挑战,例如完全缺少数据的日子。
为了全面了解情况,我决定创建一个从1940年到2022年的横桌。此表显示了左侧的年份,并指示了现有的TAVG,TMAX和TMIN值相对于相比的百分比每年的总天数(LEAP年366天)。
在下面的此代码中,我创建了一个名为StentyeArdata的数据结构,以存储现有的TAVG,TMAX和TMIN值的计数,以及每年和电台组合的总天数。然后,我计算了这些数字,并将它们存储在站点绘图中,该地图由站和年度组织。
接下来,我从站点映射中提取了所有独特的年份和站点,以创建横台的标题。我对电台和数年进行了分类,以确保表格中的订单一致,并将结果写入输出。CSV文件。
您可以从下面的结果表中看到,我们的分析表明,近年来整个范围内的IS000002011和ISE00100468电台缺少数据。这表明在此期间,这些电台可能已经停止进行测量。
我们可以得出结论,来自ISM00040180站的数据适合基于平均温度创建可视化。另一方面,ISE00105694站的数据可用作与最高和最低温度有关的可视化源。
一般而言,将来,我们需要考虑到并非所有数据都可以使用,并且我们可能需要找到填充丢失值的方法。但是,就目前而言,我们将保持原样。

主角变得沮丧的章节
最后,让我们玩得开心!我们在缓存中的CSV_RECORDS变量中有数据,让我们安装所有GO模块以进行可视化:
go get gonum.org/v1/plot
go get gonum.org/v1/plot/plotter
go get gonum.org/v1/plot/vg
go get gonum.org/v1/plot/plotutil
散点图
对于散点图,该图说明了多年来最低和最高温度如何变化,我们需要计算所选电台ISE00105694的平均最低和平均温度。我要从tutorial使用plotter.newscatter绘制图形。
在下面的代码中,我创建了每年的夏季地图,其中每个密钥代表一年,相应的值是一个温max构造,该结构包含当年的总tmax和Tmin值,以及记录的温度计数。然后在年度夏季地图上迭代,我通过将TMAX和TMIN值除以当年记录的温度计数来计算平均TMAX和TMIN温度。
每年,我将SctateData中I-Thata Point的X坐标设置为计算出的TMAXAVG,并将Y坐标设置为计算出的Tminavg。然后plotter.newscatter()使用此数据创建散点图。
让我们看下面的散点图。坦白说,它看起来并不令人印象深刻。

说实话,在GO语言中查找可视化图的信息非常具有挑战性,并且可用于gongpt的数据涉及gonum.org/v1/plot模块已过时,这使得创建视觉上吸引人的图表很难。但是,当我偶然发现一个彩色散点图的example时,运气就在我这边。
让我们看新代码。在此代码中,我指定了散点图中各个点的样式和颜色。函数sc.glyphstylefunc将索引i作为输入并返回draw.glyphstyle,以定义该索引处的点的外观。
为了确定点的颜色,代码根据散点图中的点(z)和最小值(maxz)z值计算归一化值d。然后,它使用此归一化值将颜色colormap中定义的颜色之间进行插值。
新图表看起来好多了,我们可以根据点的颜色观察到多年来的变暖趋势。

热图
我无法在图模块中找到热图功能,所以我向chatgtp寻求帮助。

您没有帮助,chatgpt。
,但后来我找到了这个article,然后按照提供的示例,设法创建了自己的热图。
那么什么是热图?平均温度的热图是一种图形表示,它使用颜色来显示地理区域或特定网格的平均温度值。较温暖的颜色(例如红色或橙色)通常代表较高的平均温度,而较冷的颜色(如蓝色或绿色)代表较低的平均温度。
要创建图形,我们首先需要每天获得平均温度,然后相应地调整颜色。
下面的代码定义了一个称为plottable的自定义结构,该结构保存了创建热图所需的数据。 WeatherData结构代表特定站的天气数据,包括温度测量(TAVG,TMAX和TMIN)和其他信息。
我从CSV_RECORDS变量中读取数据并过滤以获取ISM00040180站的温度数据。数据集变量是一个二维GO切片,可在不同年份(列)(列)中每天(行)的平均温度数据(行)。然后,我只找到非空的岁月(列)并使用Moreland.smoothbluered()函数来为热图创建调色板。
正如我之前在数据分析期间提到的,由于CSV数据集中存在空或缺失值,因此结果具有空线。将来,我们可能需要决定是忽略这些差距还是实施技术来填写缺失的数据,例如使用最近的邻居方法。尽管有空线,该图清楚地显示了多年来夏季从底部到顶部的红色漏斗的扩展。该观察结果表明随着时间的流逝趋势。

温度异常图
对于此图,我们应该从定义和计算基线开始。我选择了1951年的1980年作为基准时期,因为互联网表示,在我的情况下,这是最常见的选择。为了计算基线周期的平均温度,我们需要在选定的时间段内将每年的温度加起来,并将总数除以年数。该平均值将用作比较随后几年温度的参考点。
要绘制图形,我们将通过从当年的实际温度中减去基线(平均温度)来计算每年的温度异常。正异常表示基线以上的温度,而负异常表示基线以下的温度。
在以下代码中,我通过CSV记录进行了迭代,过滤和解析了1951年至1980年之间ISM00040180站的TAVG温度数据。在此过程中,我计算了TAVG值的总和,并计算了有效记录的数量基线期。通过将基准除以基线,我获得了基线值。
然后,随后,我通过减去基线值从1980年开始计算数据切片中每个TAVG值的温度异常。最后,我使用plotutil.addlinepoints函数创建和可视化图。
结果在视觉上比我预期的要少。尽管我做出了努力,但我无法找到一种方法来删除或调整这些要点,这对图表的美学产生了负面影响。结果,它看起来并不像我希望的那样干净和光滑。但是,即使有这些问题,人们仍然可以观察到多年来温度升高的总体趋势。

气候变化条纹
该图由代表每年平均温度数据的彩色条纹组成。每条条纹对应于特定年份,颜色强度显示了那一年的温暖或凉爽。较温暖的年份被描绘出较温暖的颜色,例如红色,而凉爽的年份则以蓝色等凉爽的颜色显示。
我从是否有可能做的问题开始。

因此,气候变化条纹对我来说似乎是彩色条形图,我问是否有可能创建它,答案是否:

至此,我对GO的图形功能有限和产生基本图所需的广泛代码感到非常沮丧。因此,我决定放弃尝试在GO中创建此特定图表的决定。虽然您可以在repository中找到负责计算图形数据的代码,但我无法成功地使用GO的功能生成图。

主角色致电Python寻求帮助的章节
简单地说,我必须承认我在Go中创建的图并不是很好。似乎GO并不是制作漂亮可视化的最佳工具。因此,让我们寻找另一个可以更有效,精美处理可视化任务的超级英雄。
下面提到的所有代码,以及您在我的仓库中可以找到此jupyter file中的更多代码。
在本章中,我们需要安装Python和一些库:
pip install pandas
pip install seaborn
pip install matplotlib
pip install numpy
首先,我们将CSV读入大熊猫dataframe:
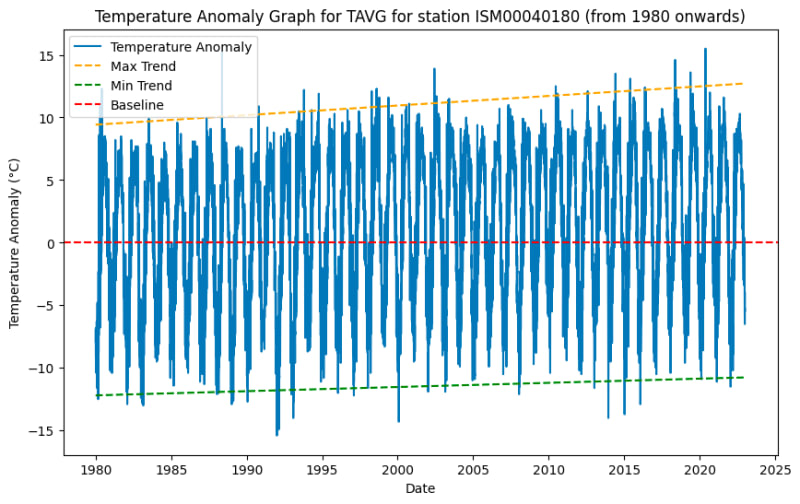
让我们重新访问异常图,因为我觉得我没有证明该图显示了任何趋势。
在下面的代码中,我通过平均1951年期间的TAVG值来复制相同的过程来计算基线,然后通过从数据切片中的每个TAVG值中减去基线值来计算温度异常。此外,我还包括两条线,可以在视觉上表示异常的趋势,从而使我们能够更好地观察多年来的温度变化。
现在,使用黄色和绿色线,我们可以清楚地观察到温度异常的变暖趋势。与基线周期相比,这些线有助于我们更好地可视化温度的任何变化。
好吧,是时候征服气候变化条纹的时间了。
在此代码中,对数据进行过滤以关注ISM00040180气象站。随后,我按年将数据分组,并每年创建一个包含TAVG值的列表。通过计算年平均温度并将其标准化为[0,1]范围,我将平均温度映射到颜色。该代码每年都会绘制条纹,从而产生气候变化条纹的效果,其中每个条纹的颜色代表该特定年份的归一化温度。
结果,我们终于在视觉上醒目和美丽的图表中看到了明显的变暖趋势。该图表显示了1998年以后的红色显着增加,强调了多年来的明显变暖趋势。

即使在像Matplotlib这样的简单Python模块中,作业也非常好。如果我们使用更复杂的库进行数据可视化,例如Plotly,我们可以实现更先进和交互式的可视化。让我们看看我们第一个散点图图的示例。
首先,我们应该安装plotly库。
pip install plotly
使用以下代码,我们可以使用plotly.express.scatter创建一个专业外观的散点图。这个散点图使我们能够通过将光标悬停在一个点上并获取其TMAX和TMIN的相应值
来与数据进行交互。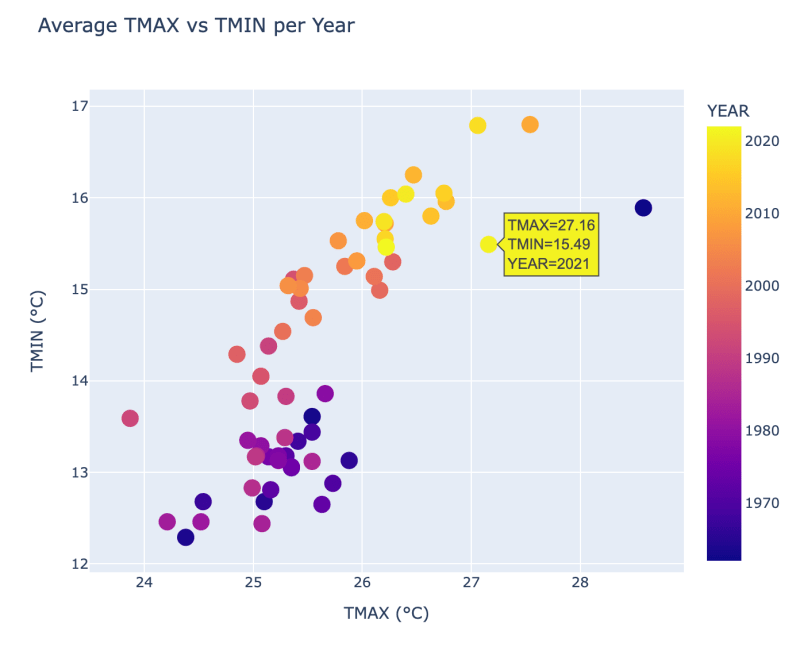
实际上,我什至在GO上找到了repo的repo。将来可能会有所帮助。
主角在隧道末端看到光的章节
考虑到我在使用图形可视化方面遇到的困难,我考虑了以下概念证明的结构(POC)。
-
一个可靠的数据库,用于存储CDO(气候数据在线)来源的历史天气数据。
-
可以使用天气数据构建气候图的直观前端应用程序。
-
可应要求将数据库提供到前端应用程序的API应用程序。
-
一个数据转换和聚合应用程序(ETL),将从CDO API获取数据,对其进行处理和组织,并最终将其加载到数据库中,以轻松访问和检索Frontend App。
对于POC,我将使用Docker容器建立一个本地环境。我们将从托管jupyter的容器开始,并使用Python和Plotly促进气候图的创建。这将作为我们的前端应用程序。
在后端,我们将在GO上开发一个API应用程序,这是另一个将连接到我们选择的数据库的Docker容器。 API将是前端和数据库之间的桥梁,应要求提供天气数据并确保图形生成的平滑数据流。
拼图的最后一部分是必不可少的组成部分 - 数据转换和聚合应用程序(ETL)。该容器在GO中实现,将从“气候数据”(CDO)API中获取数据,对其进行处理和组织,并有效地将其加载到数据库中。此ETL过程将使我们的数据库与最新的天气数据保持最新,以确保我们的可视化始终是最新的。
我仍在数据库上决定,但是我正在考虑使用PostgreSQL。但是,我对建议持开放态度,并希望在评论中听到您的想法。
因此,此设置不仅使我们的系统易于运行,而且还使其可移植 - 它可以在安装Docker的任何机器上运行,而无需担心安装依赖项。
此外,此体系结构具有灵活性和防止。如果我们想用不同的前端(例如React应用程序)替换Jupyter笔记本电脑,我们可以这样做,而不会影响系统的其余部分。同样,如果我们想切换到其他DBMS,我们可以用不同的数据库容器替换我们的容器,更新GO应用程序以与新数据库进行交互,并将其余的系统保持不变。
尽管面临挑战,但我通常对自己在这一旅程中取得的进步感到满意。

结论
总结一下,在本章中,我们面临着挑战,并在可视化气候数据时发现了解决方案。此外,我们概述了概念证明的关键方面(POC)。
随着我们继续与Golang进行冒险时,请继续关注进一步的进步和新的见解。
以前的文章:
The Golang Saga: A Coder’s Journey There and Back Again. Part 1: Leaving the Shire
The Golang Saga: A Coder’s Journey There and Back Again. Part 2: The Data Expedition