最小化副作用
生成一个随机数,通过网络通信或控制机器人都是副作用的示例。
如果软件可能会影响外部世界,则毫无意义。但是不必要的副作用可能会引起问题并更好地避免(see the previous post)。
这篇文章的广告:
- 面向python,示例
- 无意推动功能编程请参见
- 为务实的重构发展视觉思维
- 许多精彩帖子和讨论的链接
我们正在努力?
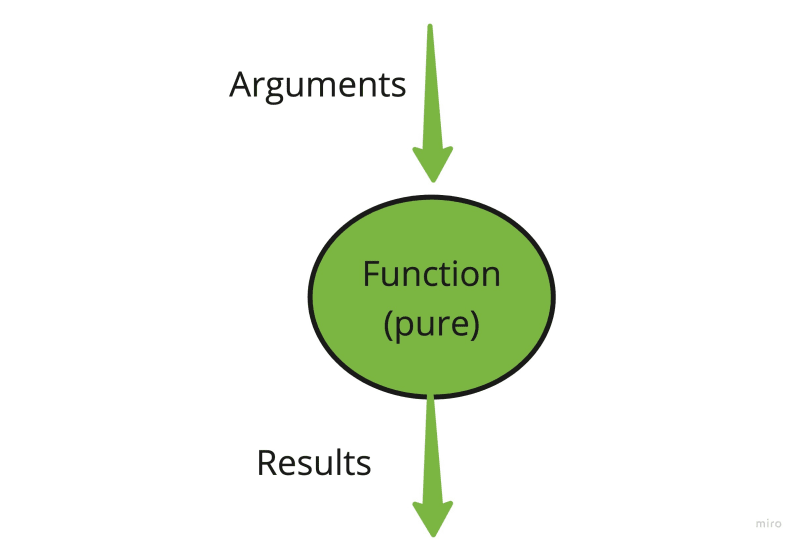
好("pure")功能应
- 不会在其范围之外发生任何变化(避免对系统施加副作用)
- 为相同的输入产生相同的输出(避免依靠系统的副作用)
人们debate是否应称为“副作用”。我发现至少在Python中识别和区分“输入”与“输出”副作用很重要。因此,在absence of a good terminology中,我将传入的副作用称为 side crignts 和外部外部副作用 似乎是65百分比是visual thinkers,所以这里有一些大多数图片:
| 脏功能 | 示例 |
|---|---|
 |
 |
调用系统time.time()是外部系统对功能的“输入”副作用。 print语句是功能到外部世界的“输出”副作用。如果一个人从这个红色的“肮脏”功能中删除了所有副作用,我们将获得无副作用的绿色效果:
| 清洁功能 | 示例 |
|---|---|
 |
 |
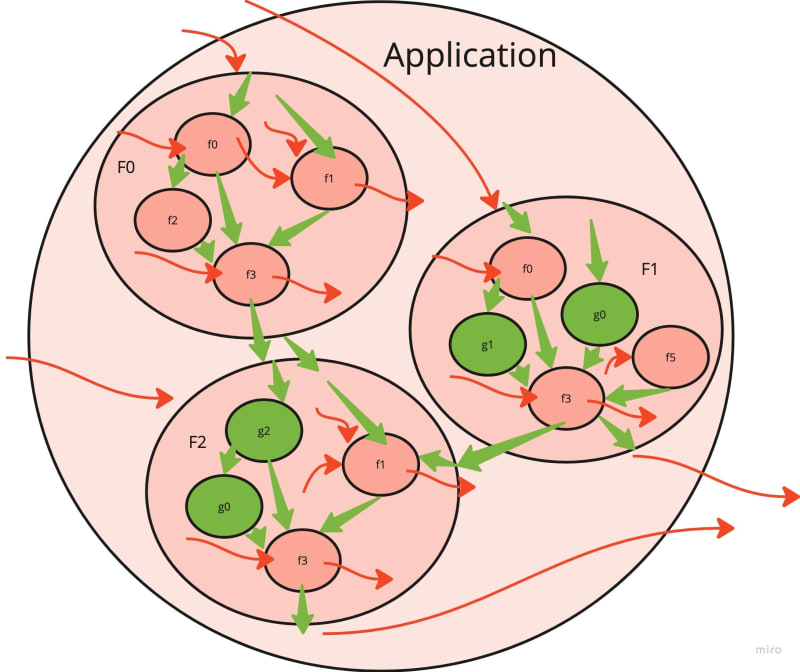
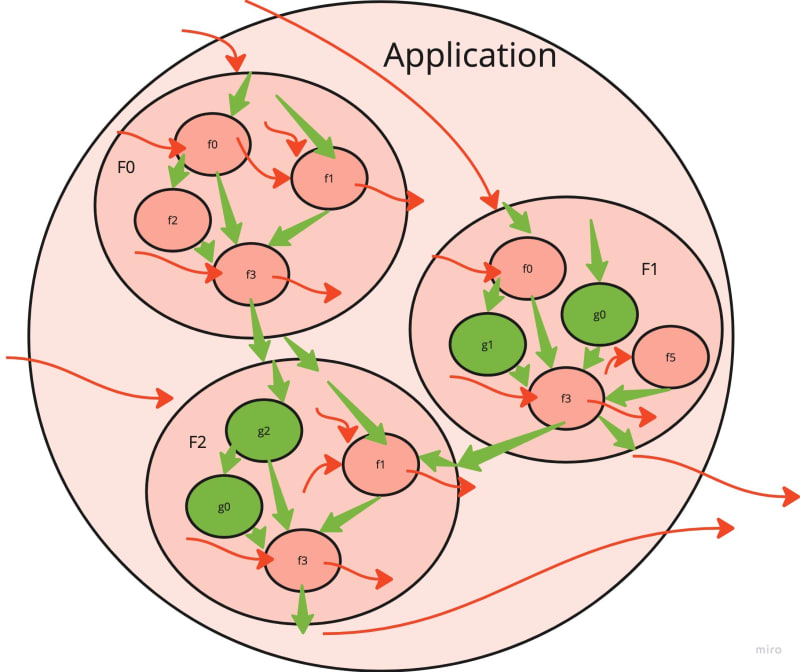
如果您不打扰清理副作用,那么您的软件将看起来像这样:
| 肮脏的应用程序 | 示例 |
|---|---|
 |
 |
有许多肮脏的红色功能,由顶部函数(较大的圆圈)调用。两者都有副作用(副act-arguments和侧陆)。有时,在下面埋葬了一个漂亮的干净绿色功能。
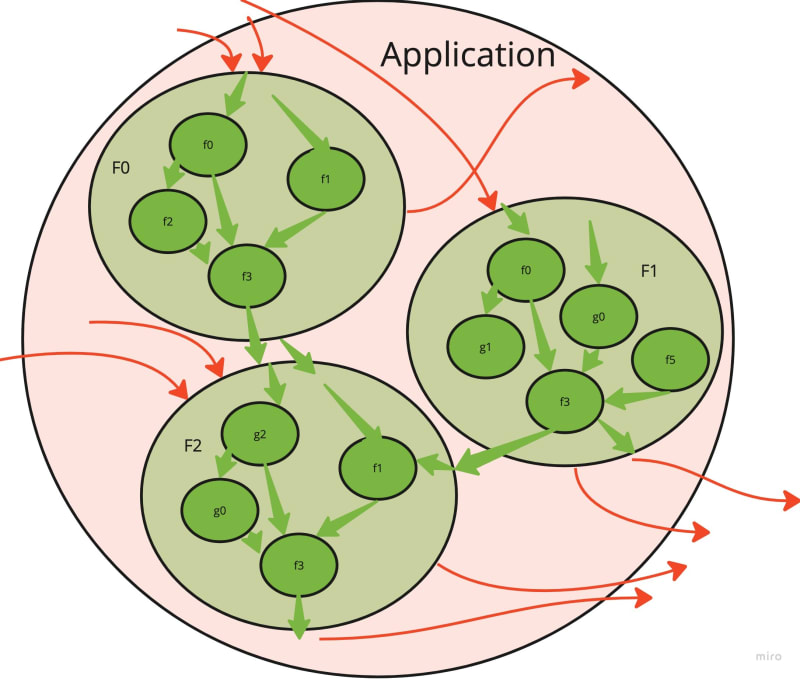
重要的是要了解这里的目标状态是什么。我们不想消除所有副作用。与世界互动的软件确实没有用。我们要努力的是这样的图片:
| 清洁应用 | 示例 |
|---|---|
 |
 |
将所有必要的副作用推向应用程序的边界。但是所有内部核心逻辑都是绿色和干净的!
这就是所谓的"Functional core, imperative shell"。关于这个想法,我至少有十几个帖子。挖掘出来后,this one似乎很干净并且有漂亮的图片。但也请参见此summary post和discussion。
从可重复使用的实用程序功能开始
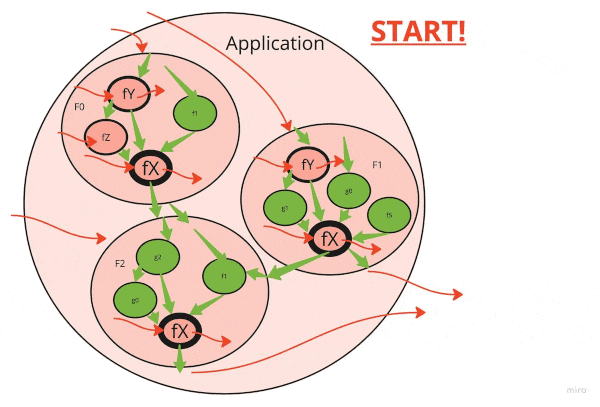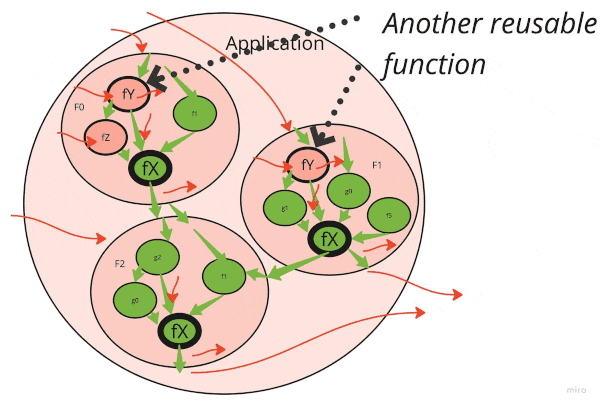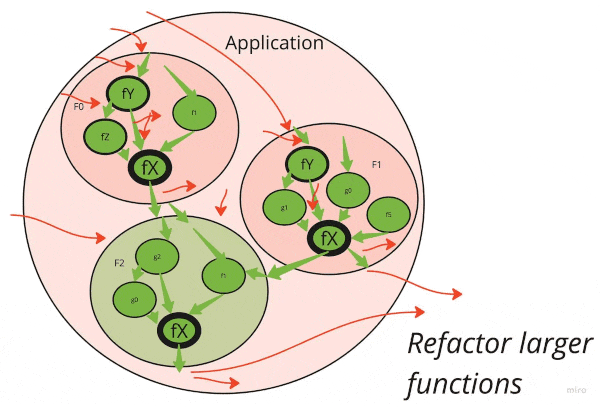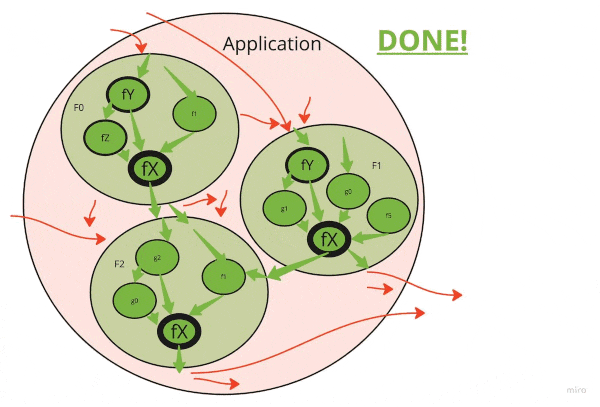
弄清楚正确的重构顺序可以大大加快清理的速度。
请注意,堆栈下的肮脏功能会感染所有称呼它的功能。如果有十层深处的呼叫和底部有一个小实用程序是脏的,则整个十层堆栈都被宠坏了。
第一件事是清理经常重复使用的基本功能和类。
因此,这是一个很好的重构顺序:
- 确定呼叫堆栈中最低的高度重复使用的肮脏功能
- 清理它们(见下文)
- 继续前进,直到用完简单的功能
- 将升级升级到呼叫堆栈
- 查找呼叫堆栈中最低的重复使用的肮脏功能
- ...
- 努力争取“功能核心,命令壳”理想!
完全删除一些副作用
您可以在不影响任何外部世界的情况下重写您的功能吗?那将是最好的选择!有时被忽略,但第一步是删除不必要的东西。这是一些常见的例子。
通常,人们认为他们的伐木陈述将永远对他人有所帮助:
def inverse(x):
print("A message that I feel everyone"
"would benefit from!")
return -x
实际上,这些日志可能仅对您和本周有所帮助。一个好的经验法则是在合并到主线之前从分支中删除大多数印刷品和日志。最有可能的是,您甚至不会注意到缺乏日志消息。
另一个典型的情况是无缘无故地初始化外部资源。在机器学习中,我经常看到创建用于保存结果的文件夹的算法
def algorithm_1(x):
os.mkdir("folder_with_results")
return -x
创建文件夹不是算法的工作。相反,应将其移至应用程序初始化逻辑中。
有时人们会忘记在重构或调试后删除以前有用的副作用。
def algorithm(argument):
set_theano_flags(current_time=time.time()) # Init something used 5 years ago
result = (... complicated logic based on argument)
return result
总而言之,可以完全消除副作用的良好比例。
简单的重构流
使功能纯净的最简单的重构配方是什么?这是侧面参数和结果派上用场的地方:
- 将侧面划分向上移动功能主体。然后将其转换为常规参数。
- 向下移动功能主体。然后返回侧面效果以及其他结果。
一些视觉效果适合您:

让我们看看我遇到的现实示例。以下功能执行一些随机图像增强。研究人员有时想调试中间的随机掩模并将其转储到临时文件中。

此功能具有2个侧面题:它从全局随机发电机读取随机掩码和切口。
它有4个侧重:
- 更改全局随机发电机状态2次
- 写一个临时调试文件
- 打印出调试文件名
此功能很难测试,并且始终通过污染/tmp和Console给您带来麻烦。
首先,让我们向上移动并向下移动。可以跳过此步骤,但我发现它在更令人费解和长时间的功能中非常有用。我们从全局状态创建一个随机发电机,然后将调试输出降低:

最后,让我们合并“侧面”和“常规”论点和结果。我们获得了干净的图像增强逻辑:

我们正在携带一个随机发电机并返回调试蒙版。高级功能可以自由选择是否通过种子rng进行可重复性或为了方便起见。如果仍然需要,它还将决定如何保存调试口罩。
短路副作用
副作用体积的生长非线性增长。当一个开发人员添加侧面参数或结果时,它鼓励其他人使用类似的侧渠道。
当功能读取Globals(Envvars,Files)时,它强迫其他功能写入Globals(Envvars,Files)以影响其行为。
在另一侧,您删除的次数越多,其余的处理就越容易。将所有副作用从自下而上的功能移到上层功能后,通常会发现您可以完全“短路”。这是一个视觉:

让我们看一个真实但更长的例子。这是研究代码中经常遇到的模式,用于使用文件系统来传递参数:
- 创建默认配置文件 - >
- 修改配置文件 - >
- 从配置文件读取
下面是我遇到的实际代码的摘录:
def dump_default_config(path):
default_config = {'hidden_size': 128, 'learning_coeff': 0.01}
with open(path, 'wb') as f:
pickle.dump(default_config, f)
def run_network(network_config_path, image):
with open(network_config_path, 'rb') as f:
config = pickle.load(f)
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config_path = 'my_config.pkl'
dump_default_config(config_path)
# update the learning coefficient in the config file
with open(config_path, 'rb') as f:
config = pickle.load(f)
config['learning_coeff'] = 1e-4 # better learning coefficient
with open(config_path, 'wb') as f:
pickle.dump(config)
return run_network(config_path, image)
正如我们讨论的那样,让我们提出侧面争论,并将结果提高到堆栈中。首先,向上移动默认配置的保存,其次,向上移动配置加载。
def create_default_config():
return {'hidden_size': 128, 'learning_coeff': 0.01}
def run_network(config, image):
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config_path = 'my_config.pkl'
default_config = create_default_config()
with open(config_path, 'wb') as f:
pickle.dump(default_config, f)
# update learning coefficient in the config file
with open(config_path, 'rb') as f:
config = pickle.load(f)
config['learning_coeff'] = 1e-4 # better learning coefficient
with open(config_path, 'wb') as f:
pickle.dump(config)
with open(config_path, 'rb') as f:
config = pickle.load(f)
return run_network(config, image)
现在,我们可以短路所有文件系统调用,并到达整洁的无副作用代码。除了要小得多,更简单之外,它的速度也更快:
def create_default_config():
return {'hidden_size': 128, 'learning_coeff': 0.01}
def run_network(config, image):
network = create_network(**config)
prediction = network(image)
return prediction
def network_main(image):
config = create_default_config()
config['learning_coeff'] = 1e-4 # better learning coefficient
return run_network(config, image)
要短路副作用,您应该首先确定相同类型(文件,全球,环境)的输入和输出副作用。然后,您可以将它们全部提起并将其取出。
向开发人员暴露副作用
副作用可能会给您带来麻烦,但是隐藏副作用是最糟糕的。想象一下,您决定使用外部库来制作友好的数学相关应用程序:
from external_library import compute_optimal_solution
def main():
x = input("Enter the number")
value = compute_optimal_solution(x)
print("Optimal value is :", exp(value))
您很乐意部署它只是为了收到有关数据库相关崩溃的用户投诉。您真的很惊讶,因为您只是想提供一些数学实用程序,并且从未打算处理数据库。看着compute_optimal_solution的来源,您可能会发现类似的东西:
def compute_optimal_solution(x):
result = 0
for i in range(1000):
result += i*x - log(i*x) + sin(i*x)
# to understand how people use our function,
# we log the results in the debug database
database_cache = sqlite3.connect(DEFAULT_DB)
cursor = database_cache.cursor()
cursor.execute(f"INSERT INTO MyDB (argument, solution) VALUES ({x}, {result})")
database_cache.commit()
cursor.close()
return result
您尊重开发人员收集调试数据的愿望,但您永远不会预先猜到。如果此功能得到适当命名,它将为您节省很多时间:
compute_optimal_solution_and_cache_solution_in_database(x)
您会很快意识到此功能不适合您的基本数学脚本。
这是一个通用规则,即该函数的名称应描述此函数的作用。副作用也是如此 - 如果您的功能具有副作用,则最好将其命名。使用此命名规则,您会发现最丑陋和最危险的功能的名称最长!
您还可以通过在模块级别上分配清洁和脏代码来暴露副作用。例如,类似图书馆的文件夹应仅具有清洁的无副作用代码。所有副作用都应进入一个类似应用的文件夹(例如scripts,app或runners)。这是另一个nice short post加强这一点。
杂项和先进
上面的点应适用于大多数副作用清理。但是,有许多例外和高级概念不符合这篇文章。这是一些后续行动。
依赖注入?
注入可能产生副作用而不是自己产生的对象是踢罐头的常见方法:
- 传递随机生成器而不是查询
- 通过
Timer而不是time.time() - 通过
logging.Logger而不是print
阅读了许多资源后,this thread可能保持最好。
这是一个很棒的JavaScript post(以及副作用)。在自由解释中,用常规的could be called依赖注入代替侧面题目。应该小心不要过度使用(1,
2)。
返回函子?
您可以返回以后会执行的“懒惰”功能,而不是立即引起副作用。请参阅有关此技术的the post。另外,请参见this post中的“懒惰功能”部分。这是一本有趣的长阅读,但它可能超出了普通Python凡人的需求。
复制输入容器?
修改传入的list或dict也是副作用。
通常,值得复制,修改和返回它。参见讨论here和this post。慢了吗?可能是。但是实际的问题应该是:
您的公司会在(a)执行较慢的代码或(b)副作用引起的错误错误上花费更多的钱吗?没有选择(a)或(b),就没有害怕缓慢但强大的代码的基础。
打印和伐木者?
尽管logging是副作用,但这并不是最糟糕的。至少,大多数开发人员不这样对待它。
如果不进行长时间切线,就很难建议任何具体的事情。您可以采用可配置的logging,将记录器作为依赖项传递给每个函数,返回字符串消息或使用print(例如if you use multiprocessing)。
结论:
一天结束时,请记住是务实的。您不想删除所有副作用,而只想删除不必要的效果。实际上,可以避免许多副作用。因此,您最好使用此帖子中的一些食谱分配一些时间进行重构和处理它们:
- 通过您的代码通行并完全删除一些副作用
- 识别侧面和侧押,并将其与定期论据或结果合并
- 确定重复使用的实用程序并首先清理
- 请注意,某些副作用是由彼此造成的,它们是短路的
- 向开发人员暴露副作用。
谢谢您的阅读!