在当今的数字时代,消息传递平台已成为我们日常沟通不可或缺的一部分。 WhatsApp拥有庞大的用户群和功能强大的功能,为建立智能聊天机器人提供了绝佳的机会,可以提供即时和个性化的帮助。在本文中,我们将探讨如何利用Flask,Twilio WhatsApp,Langcain和ChatGPT models的力量创建一个智能的WhatsApp机器人,在PDF问答中脱颖而出。
。Twilio是一个领先的云通信平台,提供了一系列工具和服务,以将消息传递功能无缝地集成到您的应用程序中。通过将Twilio的消息API与Flask(轻巧且灵活的Python Web框架)相结合,我们可以为WhatsApp Bot开发强大的后端。
要应对处理PDF文件和提取相关信息的挑战,我们将研究语言模型和自然语言处理的领域。 OpenAI's高级语言模型(例如GPT-3.5 Turbo)提供了理解和生成类似人类文本的最先进功能。通过使用Langcain利用OpenAI models的功能,我们可以将机器人转换为知识渊博的助手,可以根据上传PDF文件的内容回答问题。
在本文中,我将逐步指导您,从Twilio的全面出版指南中汲取灵感。您将学习如何设置开发环境,从WhatsApp中处理传入的消息,PROCES PDF文件,生成文档嵌入式以及使用Twilio,Flask和功能强大的语言模型执行提问任务。
在本教程结束时,您将拥有一个功能齐全的WhatsApp机器人,能够为用户提出的问题提供准确而有见地的答案。这为客户支持,信息检索和自动化打开了令人兴奋的可能性,以触手可及的智能对话代理赋予企业和个人。
所以,让我们深入研究烧瓶,Twilio,Openai和Langchain的世界,并踏上了建立一个了不起的WhatsApp机器人的旅程,以彻底改变了我们与PDF的互动方式并获得即时知识的方式。
>先决条件
-
Python:确保您在系统上安装了Python。
-
Twilio Account:为了发送和接收消息,有必要拥有一个Twilio帐户。为此,您将需要一个auth_token,twilio电话号码和account_sid。
-
OpenAI API Key:要使用OpenAI的GPT-3.5型号,您需要一个API键。
-
Ngrok:ngrok是一种工具,使我们能够将本地烧瓶服务器公开到Internet。
安装依赖项
要开始,您需要以下包:
- dotenv库:Alow alow you您加载了应用程序中的环境变量。使用
pip install python-dotenv安装 - Langchain:允许您使用多种工具来构建AI供电的应用程序。使用
pip install langchain安装 - PYPDF2库:您将使用PYPDF2库从PDF文件读取和提取文本。使用
pip install PyPDF2安装 - Twilio Python库:允许您与Python中的Twilio API进行交互。使用
pip install twilio安装 - OpenAI:使您可以访问OpenAI的GPT型号。使用
pip install openai安装
但是,安装此软件包后,可能会提示您安装其他软件包,以便您运行该应用程序。
设置Twilio帐户
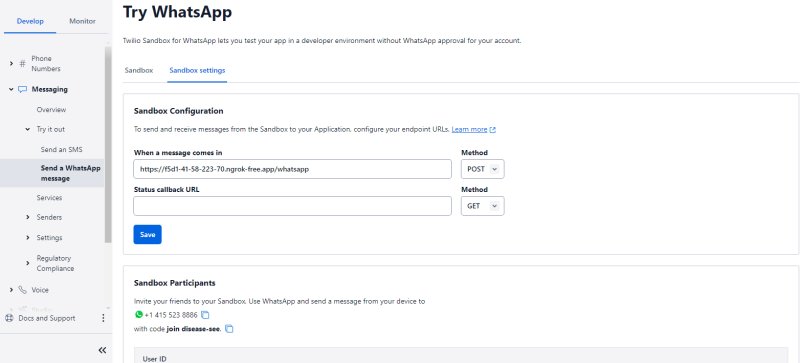
为了说明该过程,您将通过将Twilio Sandbox用于WhatsApp来配置Twilio帐户以利用WhatsApp。通过导航到左侧栏上的消息传递部分,访问Twilio控制台内的WhatsApp沙箱(如果您看不到它,请单击Explore产品以显示产品列表,您可以在其中找到消息传递)。接下来,扩展“尝试”下拉菜单,然后从选项中选择“发送WhatsApp消息”。然后,您将看到这个:

然后,您将继续进行扫描QR码,然后在WhatsApp中看到“加入疾病 - 看到”消息,发送它,就像您连接到WhatsApp。

设置我们的编码环境
然后,我们将进入我们的代码编辑器并创建一个 app.py 文件和a .env 文件。在我们的 .env 文件中,我们将继续进行以下内容:
TWILIO_ACCOUNT_SID = xxxxxxxx
TWILIO_AUTH_TOKEN = xxxxxxxx
TWILIO_PHONE_NUMBER = xxxxxxxx
OPENAI_API_KEY = xxxxxxxx
在先决条件中,您应该命名相应的令牌,现在您将代替xxxxxxxx。
构建机器人
现在,您已将所有令牌添加到您的 .env 文件中并创建了一个 app.py 文件,您将继续并导入所有依赖关系
from flask import Flask, request
import os
from twilio.twiml.messaging_response import MessagingResponse
from twilio.rest import Client
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
import tempfile
from PyPDF2 import PdfReader
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
app = Flask(__name__)
@app.route("/message", methods=["POST", "GET"])
def message():
return "Hello, world"
if __name__ == "__main__":
app.run(debug=True)
因此,以上是pdf q和a bot的裸露骨头,MessagingResponse MessagingResponse在twilio,Client中发送消息以访问我们的twilio帐户,dotenv to访问环境变量,RecursiveCharacterTextSplitter RecursiveCharacterTextSplitter将文本分开,OpenAIEmbeddings,OpenAIEmbeddings,OpenAIEmbeddings要创建Word Embedings,requests从twilio,templfile获取我们的PDF文件,以创建一个临时目录来存储上传的pdf,PdfReader,以便能够从上传的PDF文件中获取读取数据,FAISS以创建一个vector Store,以获取类似文本的矢量商店您在PDF中的问题load_qa_chain创建问答模型。
接下来,在Messages()函数中附加此代码:
load_dotenv()
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
response = None
account_sid = os.getenv('TWILIO_ACCOUNT_SID')
auth_token = os.getenv('TWILIO_AUTH_TOKEN')
client = Client(account_sid, auth_token)
twilio_phone_number = os.getenv('TWILIO_PHONE_NUMBER')
sender_phone_number = request.values.get('From', '')
pdf_url = request.values.get('MediaUrl0')
response = None
此代码用于通过检索环境变量来与Twilio客户端建立连接。还从发送者(特别是PDF URL)中提取重要信息,该信息将在以后将其存储在S3桶中。
。现在您将此变量添加在@app.route的顶部,因为它们将作为稍后将要访问的全局变量。
pdf_exists = False
VectorStore = None
从PDF产生响应
接收PDF
if media_content_type == 'application/pdf':
global pdf_exists, VectorStore
pdf_exists = True
response = requests.get(pdf_url)
with tempfile.NamedTemporaryFile(suffix='.pdf', delete=False) as temp_file:
temp_file.write(response.content)
temp_file_path = temp_file.name
pdf = PdfReader(temp_file_path)
text = ""
for page in pdf.pages:
text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200,
length_function = len
)
chunks = text_splitter.split_text(text=text)
embeddings = OpenAIEmbeddings()
VectorStore = FAISS.from_texts(chunks, embedding=embeddings)
response = "Recieved, You can now ask your Questions"
首先,该代码验证是否已收到PDF文件。如果检测到PDF文件,则将称为“ PDF_EXISTS”的全局变量设置为true。接下来,该代码将请求发送到PDF的URL并检索文件。该文件临时存储在目录中,并读取其内容。然后,代码通过PDF的页面迭代,将文本分为1000个单词的片段,重叠为200个单词。
之后,该代码利用OpenAIEmbeddings函数来生成文本段的嵌入。然后将这些嵌入将其传递到矢量站中。最后,发送了一条通知消息,以指示代码准备回答与PDF有关的问题。
接收文字
elif pdf_exists:
question = request.values.get('Body')
if pdf_exists:
docs = VectorStore.similarity_search(query=question, k=3)
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0.4)
chain = load_qa_chain(llm, chain_type="stuff")
answer = chain.run(input_documents=docs, question=question)
message = client.messages.create(
body=answer,
from_=twilio_phone_number,
to=sender_phone_number
)
return str(message.sid)
else:
response = "No PDF file uploaded."
提供的代码首先检查是否收到文本。如果确实收到了文本,它将进一步检查是否通过检查可变PDF_EXISTS来以前发送了PDF文件。在此之后,该代码利用vectorStore根据所提供的问题搜索类似的文本。然后,它采用GPT-3.5-Turbo模型来根据检索到的信息生成答案。随后将生成的答案发送为消息,并返回消息SID(唯一标识符)。
但是,如果发送文本但没有事先上传PDF文件,则代码发送了一个响应,说明“没有PDF文件上传。”
收到无效格式
else:
print(media_content_type)
response = "The media content type is not application/pdf"
print(media_content_type)
message = client.messages.create(
body=response,
from_=twilio_phone_number,
to=sender_phone_number
)
return str(message.sid)
如果未满足IF和ELIF语句中的条件,则代码将响应一条消息,说“媒体内容类型不是应用程序/PDF。”
运行我们的机器人
现在继续前往您的终端并运行python app.py,我们的应用将在localhost:5000上运行。现在,您可以继续前往NGrok并运行ngrok http 5000,以便您可以发送和接收WhatsApp消息。我们应该看到这样的东西

现在,复制循环的链接,返回到您的Twilio沙盒设置并在那里粘贴
在那里,您现在可以将PDF上传到您的WhatsApp bot并提出问题


结论
总而言之,您已经了解了提供的代码的各个方面。您已经探索了它的功能,如何验证PDF文件,检索和处理其内容,生成嵌入以及使用模型来回答问题。此外,我们考虑了在不满足某些要求时触发特定响应消息的情况。通过理解这些细节,您现在可以更好地了解该法规的整体行为及其在不同情况下的结果。
快乐的建筑!