在本文中,您将学习如何使用Python,Faunadb,Openai和Twilio建立健身和饮食聊天机器人。聊天机器人将能够通过WhatsApp与您通信,并根据您的对话历史记录提供响应。您将浏览代码,并了解该过程中涉及的关键组件和库。
先决条件
开始之前,请确保您有以下内容:
- Python 3.x安装在您的机器上
- FaunaDB帐户和API键
-
OpenAI API key访问
gpt-3.5-turbo型号 - Twilio account SID,Auth Token和电话号码
- Ngrok:它使我们能够将本地烧瓶服务器公开到Internet。
设置FAUNA数据库
要开始使用Fauna,您的第一步是在官方网站上建立帐户。这可以通过提供您的电子邮件地址或通过以下链接:Fauna来实现。为了有效与聊天机器人进行有效的通信,有必要利用FAUNA数据库存储和检索用户消息。
创建数据库

使用Fauna创建帐户后,您将创建一个数据库来存储Users和Messages。在这里,您将被要求提供数据库名称,然后将其命名为MyChatBot,并且该区域将被设置为Classic,并且您已经创建了数据库。然后,您应该在下面提供这样的屏幕:

创建您的收藏
接下来,您将创建2个集合,这基本上是SQL世界中的Tables,但在我们的上下文中有所不同。
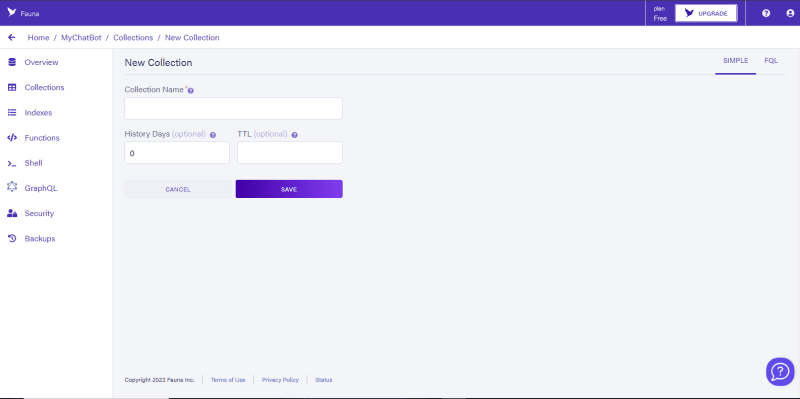
要创建您的集合,请单击主页上的Create Collection按钮,并给它一个名称,但是由于您将创建两个集合将命名为Users和Messages。 “用户”集合用于从WhatsApp中存储用户的用户名,而Messages集合用于将用户的聊天历史记录与机器人存储。您将被要求使用历史记录Days和TTL。历史日用于定义动物区系的数量,应保留该特定集合中任何数据的历史记录,而TTL则是该集合中数据的到期日期。例如,如果将TTL设置为7,则该集合中存储的任何数据将在上次修改日期后的7天自动删除,但是对于本教程,您将不需要它,因此将其不受欢迎。创建两个集合后,您应该看到这一点:
创建索引
想知道什么是索引是什么?嗯,索引只是一种基于特定字段或标准组织浏览集合中数据中数据的方法,从而可以更快,有针对性地检索信息。要创建索引,您将导航到索引选项卡,您应该看到类似的内容:

要创建索引,您首先需要Select a Collection,然后指定Terms,这是仅允许索引浏览的特定数据。但是为此,您将创建两个索引,即users_by_username,它将在Users集合下用于注册用户和users_message_by_username,这将通过其用户名来过滤用户的消息。 users_by_username和users_messages_by_username的Terms设置为data.username将设置为data.username,然后单击SAVE继续。
获取我们的数据库密钥
继续构建聊天机器人之前,您需要创建一个API键,该键可以使您的应用程序轻松与数据库通信。要创建一个API键,您需要导航到FAUNA侧边栏上的“安全性”选项卡(在屏幕的左侧)。

接下来,您将单击将导航到下面的页面的NEW KEY按钮:
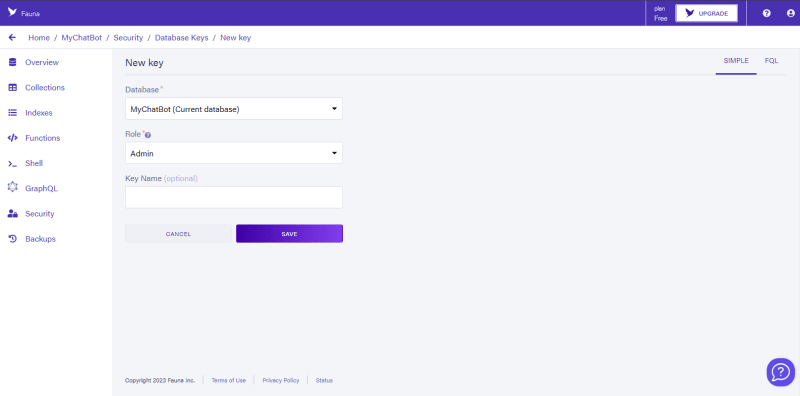
在这里,您的关键角色将设置为Server而不是Admin,并将您的密钥名称设置为可选的数据库名称,然后单击SAVE,您将被导航到显示您的数据库键并表示要成为的页面立即复制。您应该看到这样的东西:

获得API KEY后,将其存储在 .env 文件中。
配置Twilio
为了演示该过程,您将通过使用Twilio Sandbox进行WhatsApp来设置Twilio帐户以使用WhatsApp。要访问Twilio控制台中的WhatsApp沙盒,请导航到位于左侧栏上的消息部分(如果看不到它,请单击Explore产品以揭示产品列表,可以在其中找到消息传递)。之后,扩展“尝试出来”下拉菜单,然后从可用选择中选择“发送WhatsApp消息”。随后,您将获得以下显示:

扫描QR码后,您将立即在WhatsApp上收到“加入疾病见”消息。只需发送消息,就这样,您将连接到WhatsApp帐户。
设置环境
首先,在编码环境中创建一个 app.py 文件,然后必须安装必要的库。您需要安装faunadb,OpenAI,python-dotenv,twilio和flask库。您可以使用以下命令安装它们:
pip install telebot faunadb openai python-dotenv twilio flask
安装了库后,您可以进行代码实现。
导入库
让我们从您的python脚本中导入所需的库:
import telebot
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
import openai
from dotenv import load_dotenv
from twilio.rest import Client
import os
from flask import Flask, request
from twilio.twiml.messaging_response import MessagingResponse
您需要将faunadb导入集成Faunadb,openai,用于利用OpenAi的gpt-3.5-turbo型号,dotenv,用于加载环境变量的twilio,用于发送和接收WhatsApp消息的twilio,os,os,用于访问环境变量的flask,用于创建flask用于创建Web Server和kude40,并twiml响应。
初始化烧瓶应用程序和Faunadb客户端
让我们初始化烧瓶应用程序并创建一个faunadb客户端:
app = Flask(__name__)
def prompt(username, question):
load_dotenv()
client = FaunaClient(secret=os.getenv('FAUNA_SECRET_KEY'))
# ...
您使用Flask(__name__)构造函数创建烧瓶应用程序。在prompt函数中,您可以使用load_dotenv()加载环境变量,并使用提供的秘密密钥创建FaunAdb客户端。
在Faunadb中存储用户消息
在prompt函数中,您使用faunadb客户端将用户消息存储在faunadb中:
data = {
"username": username,
"message": {
"role": "user",
"content": question
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": data
}
)
)
您创建一个包含username和用户的question的字典data。然后,您使用client.query方法在“消息”集合中创建一个新文档,存储data字典。
从Faunadb检索用户消息
您通过基于username查询数据库来从FAUNADB检索用户消息:
index_name = "users_message_by_username"
username = username
result = client.query(
q.map_(
lambda ref: q.get(ref),
q.paginate(q.match(q.index(index_name), username))
)
)
messages = []
for document in result['data']:
message = document['data']['message']
messages.append(message)
您指定了从Faunadb查询的索引的index_name。然后,您使用q.paginate和q.match检索与给定的username相关的所有文档。您可以循环浏览结果并提取message内容,将其存储在messages列表中。
设置OpenAI API
让我们设置OpenAi API并定义助手的角色:
openai.api_key = os.getenv('OPENAI_API_KEY')
system_message = {"role":"system", "content" : "You are a dietitian, food nutritionist, and fitness consultant, you provide expert guidance and advice to individuals facing dietary challenges or seeking direction on their food choices and exercise routines. You offer personalized recommendations and solutions to those who are unsure about the right foods to eat or the appropriate exercises to engage in. If user says hello or any greeting introduce yourself."}
prompt_with_persona = [system_message] + [
{"role": "user", "content": message["content"]} if message["role"] == "user"
else {"role": "assistant", "content": message["content"]} for message in messages
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=prompt_with_persona
)
generated_reply = response["choices"][0]["message"]["content"]
您使用 .env 文件的os.getenv('OPENAI_API_KEY')设置OpenAI API键,如前所述。然后,您定义一个代表助手角色的system_message。您可以通过将system_message与用户和助理消息组合到messages列表中来构建对话提示。
之后,您使用openai.ChatCompletion.create()对OpenAI聊天COTCOMPLETION API进行了API调用,将对话提示符作为messages参数。 API响应包含模型的生成回复,您将其提取并存储在generated_reply变量中。
存储助手的答复在Faunadb
您使用Faunadb客户端将助手的答复存储在Faunadb中:
newdata = {
"username": username,
"message": {
"role": "assistant",
"content": generated_reply
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": newdata
}
)
)
您创建了一个新的字典newdata,其中包含username和助手的generated_reply。然后,您使用client.query方法在“消息”集合中创建一个新文档,存储newdata字典。
处理WhatsApp消息
现在,让我们实现处理WhatsApp消息的路线:
@app.route('/whatsapp', methods=["POST", "GET"])
def chat():
load_dotenv()
twilio_phone_number = os.getenv('TWILIO_PHONE_NUMBER')
sender_phone_number = request.values.get('From', '')
username = request.values.get('ProfileName')
question = request.values.get('Body')
account_sid = os.getenv('TWILIO_ACCOUNT_SID')
auth_token = os.getenv('TWILIO_AUTH_TOKEN')
Twilioclient = Client(account_sid, auth_token)
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
reply = None
user_exists = client.query(
q.exists(q.match(q.index("users_by_username"), username)))
if user_exists:
reply = prompt(username, question)
answer = Twilioclient.messages.create(
body=reply,
from_=twilio_phone_number,
to=sender_phone_number
)
else:
client.query(
q.create(
q.collection("Users"),
{
"data": {
"username": username
}
}
)
)
reply = prompt(username, question)
answer = Twilioclient.messages.create(
body=reply,
from_=twilio_phone_number,
to=sender_phone_number
)
return str(answer.sid)
在/whatsapp路线内,我们加载了环境变量,从传入请求中检索必要的数据,并创建Twilio和Faunadb客户端。我们使用q.exists和q.match检查了用户是否存在于Faunadb中。如果用户存在,我们将调用prompt函数以生成答复,并使用Twilio的messages.create()方法将答复发送回用户。如果用户不存在,我们将在“用户”集合中创建一个新文档,并遵循与上述相同的过程。
运行烧瓶应用程序
最后,让我们运行烧瓶应用程序:
if __name__ == '__main__':
app.run(debug=True)
我们使用if __name__ == '__main__':条件语句来确保仅在直接执行脚本时运行该应用程序,而不是将其导入为模块。为了启用调试模式,debug=True设置为在开发过程中获得更好的错误消息。现在,在您的终端运行python app.py,它将在localhost:5000上运行。您现在可以前往Ngrok并运行ngrok http 5000。
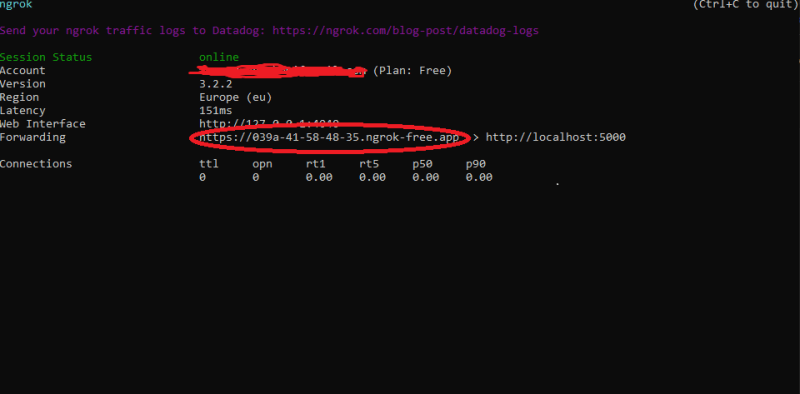
复制循环链接并将其粘贴到您的WhatsApp沙盒中

那里有它,您现在拥有自己的个人WhatsApp健身和饮食机器人


结论
在本文中,您学习了如何使用Python,Faunadb,OpenAI和Twilio构建聊天机器人。我们逐步介绍了代码,从初始化烧瓶应用程序到处理WhatsApp消息,并使用OpenAI的ChatCompleption API生成响应。您可以将此代码用作开发自己的聊天机器人的起点。
快乐的建筑!