Read the latest version of this article here
介绍
传统上,大多数聊天机器人都是If-Else块的树。有些人有一层复杂的方法,可以捕获用户意图,以决定应触发哪些功能。但是,该技术永远不够好,无法解决实际的查询。
在GPT-3之后,我们看到了大型语言模型能够提出近人类的答案。
在本教程中,我们将索引文档,在其顶部创建一个由GPT驱动的机器人,最后将其视为API。
上下文 + LLM
这些LLM(例如ChatGpt)未经企业数据培训。它们是通用模型,为聊天和完成句子而创建。
要解决这个问题,您不需要微调这些模型。相反,更好的解决方案是将一些知识与问题一起传递。让我给你一个例子。
我们“最高速度是多少?”到chatgpt:
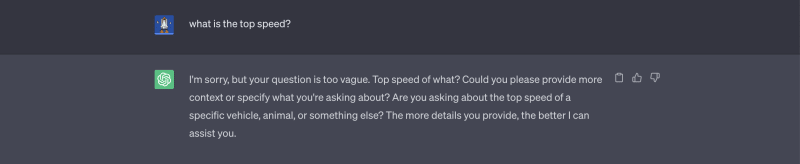

两个答案都是正确的,但是,第二个答案对客户更有用。
这里的下一个挑战是获取知识,并将其与问题一起为LLM设置上下文。为此,我们可以使用猎犬。想象一下,您要了解有关汽车的所有可能信息的数据库。您可以执行词汇搜索并找到可能具有答案的行。然后,将这些行以及客户的问题传递给LLM。
这是完整流程的样子
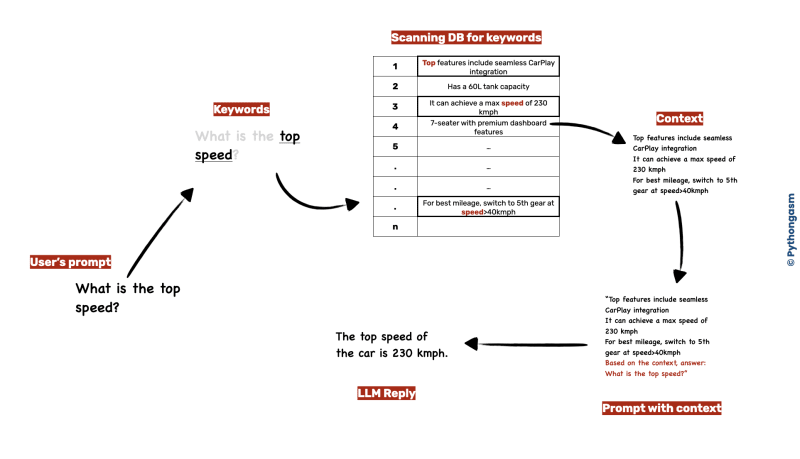
在上面的示例中,我们扫描了DB的单词“ top”和“ speed”,将结果串联在一起。为了获得更好的体验,我们还添加了一些指令(以保持答案简洁),并与客户提出的原始问题一起。将所有内容放在一起,传递给LLM并繁荣 - 我们有答案。
索引
在本练习中,我们将建立一个简单的机器人,回答有关梅赛德斯 - 奔驰A级豪华轿车的问题。
现在,公司没有关于产品信息的原始表。它们以上述文档的形式提供。
因此,第一步是创建数据库或搜索索引。要提取文本,我们将使用pypdf2:
pip install PyPDF2
from PyPDF2 import PdfReader
import csv
SOURCE_FILE = "The Mercedes-Benz A-Class Limousine.pdf"
OUTPUT_CSV = "Mercedes-Benz-A-Class-Limousine.csv"
reader = PdfReader(SOURCE_FILE)
n_pages = len(reader.pages)
header = False # file is empty, so no header row is present
for n in range(n_pages):
page = reader.pages[n]
text = page.extract_text()
with open(OUTPUT_CSV, "a+") as f:
writer = csv.DictWriter(f, fieldnames=["page", "content"])
if not header:
writer.writeheader()
header = True # header row added
writer.writerow({"page": n + 1, "content": text.lower()})
f.close()
| page | 内容 |
|---|---|
| 1 | 新的梅赛德斯 - 奔驰A级豪华轿车。 |
| 2 | *请阅读defleamer2最近的陈列室联系我们实时聊天设计技术... |
这将创建一个CSV文件。要亲吻,我们将使用此CSV文件 + Pandas用作我们自己的Retriever版本的索引。
猎犬
让我们创建一个kude0类,该类将根据客户查询来检索结果。该类将具有以下功能:
- 删除停止字 停止词是像“ a”,“”,“”等的常用词,这些词对搜索没有贡献。负面影响频率更大。例如,如果有人问您“汽车的最佳功能是什么”,那么您将忽略问题中的大多数单词,而只会寻找“功能”一词。
stopwords = [...]
return [word for word in words if word not in stopwords]
- 过滤顶行 一旦我们使用匹配的关键字提取所有行,我们将优先考虑那些关键字频率较高的人。考虑到LLM的令牌极限,这也变得重要。
df = pd.read_csv('Mercedes-Benz-A-Class-Limousine.csv')
# add a column frequency which will contain the sum of frequencies of keywords words
df["freq"] = sum([df['content'].str.count(k) for k in keywords])
# sort the dataframe by frequency of keywords
rows_sorted = df.sort_values(by="freq", ascending=False)
- 检索 实际检索功能将负责根据客户查询为我们提供上下文。
query = "top speed"
# select all rows where the content column contains the words "top" or "speed"
df = df.loc[df['content'].str.contains("top|speed")]
return f"{''.join(top_rows['content'])}"
请注意,这是回猎犬的非常基本的实现。标准做法是使用ChromaDB或Azure Cognitive Search之类的东西进行索引和检索。
另外,您可以获取停止单词的完整列表this GitHub gist。
让我们把所有内容都放入班级:
import pandas as pd
class Retriever:
def __init__(self, source, searchable_column):
self.source = source
self.searchable_column = searchable_column
self.index = pd.read_csv(source)
@property
def _stopwords(self):
return [
"a",
"an",
"the",
"i",
"my",
"this",
"that",
"is",
"it",
"to",
"of",
"do",
"does",
"with",
"and",
"can",
"will",
]
def remove_stopwords(self, query):
words = query.split(" ")
return [word for word in words if word not in self._stopwords]
def _top_rows(self, df, keywords):
df = df.copy()
df["freq"] = sum([df[self.searchable_column].str.count(k) for k in keywords])
rows_sorted = df.sort_values(by="freq", ascending=False)
return rows_sorted.head(5)
def retrieve(self, query):
keywords = self.remove_stopwords(query.lower())
query_as_str_no_sw = "|".join(keywords)
df = self.index
df = df.loc[df[self.searchable_column].str.contains(query_as_str_no_sw)]
top_rows = self._top_rows(df, keywords)
return f"Context: {''.join(top_rows['content'])}"
现在,我们可以轻松实例化此类:
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
LLM
下一步是将此上下文传递给LLM。我们将使用SOTA GPT-3.5-Turbo模型。为此,您需要一个OpenAI API键,您可以获得here。
这是示例OpenAI API请求:
OAI_BASE_URL = "https://api.openai.com/v1/chat/completions"
API_KEY = "sky0urKey"
CONTENT_SYSTEM = "You're a salesman at Mercedes, based on the query, create a concise answer."
def llm_reply(prompt: str) -> str:
data = {
"messages": [
{"role": "system", "content": CONTENT_SYSTEM},
{"role": "user", "content": prompt},
],
"model": "gpt-3.5-turbo",
}
response = requests.post(
OAI_BASE_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json=data,
).json()
reply = response["choices"][0]["message"]["content"]
return reply
>>> llm_reply("hello")
"Hello! How can I assist you today?"
messages是字典列表。每个词典都有两个键和内容。 “系统”角色为机器人设定了角色,并且像指令一样工作。我们将通过角色“用户”传递消息。
让我们问一下关于A类豪华轿车的第一个问题:
query = "What is the size of alloy wheels?"
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
reply = llm_reply(f"{context}\nquery:{query}")
>>> reply
"The size of the alloy wheels is 43.2 cm (17 inches)."
恭喜!您成功地从PDF文件创建了一个由GPT驱动的机器人。
FastAPI应用程序
让我们使用FastApi作为端点来公开我们的功能。
我们还安装了一个静态目录,并渲染模板将此API与UI集成。
requirements.txt
fastapi==0.78.0
pandas==1.5.3
pydantic==1.9.1
requests==2.27.1
uvicorn==0.17.6
bot.py
import pandas as pd
import requests
OAI_BASE_URL = "https://api.openai.com/v1/chat/completions"
API_KEY = "sky0urKey"
CONTENT_SYSTEM = "You're a salesman at Mercedes, based on the query, create a concise answer."
class Retriever:
...
def llm_reply(prompt: str) -> str:
...
main.py
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
from fastapi.staticfiles import StaticFiles
from bot import Retriever, llm_reply
from pydantic import BaseModel
class ChatModel(BaseModel):
query: str
templates = Jinja2Templates(directory="./")
app = FastAPI()
app.mount(
"/static",
StaticFiles(directory="./", html=True),
name="static",
)
@app.get("/")
def root(request: Request):
return templates.TemplateResponse("index.html", context={"request": request})
@app.post("/chat")
def chat(cm: ChatModel):
query = cm.query
r = Retriever(
source="Mercedes-Benz-A-Class-Limousine.csv", searchable_column="content"
)
context = r.retrieve(query)
prompt = context + "\n" + "Query:" + query
return llm_reply(prompt=prompt)
我们将使用Uvicorn运行该应用程序:
uvicorn main:app --port 8080 --reload
您可以转到localhost:8080/docs并从Swagger UI发送示例请求,也可以发送卷曲请求:
curl -X 'POST' \
'http://127.0.0.1:8080/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "What is the size of alloy wheel?"
}'
现在,API已经实时,您可以将其连接到前端。对于本教程,我使用了这个美丽的design on codepen(信用:Abadu)。
演示
链接到完整的源代码在下面附有。
挑战和下一步
-
retriever :正如我们所讨论的,猎犬的改进范围。对于例如,您可以实现拼写检查的函数,或将整个内容与某些基于云的服务(例如Azure认知服务)集成。
-
环围栏:改进提示/系统指令,以便将机器人限制为仅回答与梅赛德斯相关的问题,并礼貌地拒绝其他问题。
-
聊天历史记录:当前机器人不会发送历史消息。另外,它无法识别后续问题。例如,在问“我可以连接iPhone吗?”之后,我应该能够问“其他设备”(后续问题)。因此,您应该确定后续问题,并发送聊天历史记录。