这篇文章说明了如何从头开始设置新的Elasticsearch群集,并准备将其用于将数据索引,并作为远程群集通信/从远程群集进行通信,并为新群集设置监视。
问题1:基于您的用例所需的配置在Elastic.co上创建一个新的Elasticsearch群集。
从头开始创建一个新的群集:
创建一个具有以下资源的main.tf文件:
a。 ec_deployment-主要集群部署资源
b。 aws_secretsmanager_secret-集群秘密
C。 aws_secretsmanager_secret_version-秘密所需的集群秘密版本
d。 elasticstack_elasticsearch_cluster_settings-要将默认设置添加到集群等群集节点等。
示例:ec_deployment
resource "ec_deployment" "<cluster-name>" {
name = "<cluster-name>"
region = "aws-eu-central-1"
version = var.elasticsearch_version
deployment_template_id = standard/arm-based (decide based on the requirement)
elasticsearch {
autoscale = "false"
topology {
id = "hot_content"
size = "15g" // size of the cluster
zone_count = 3 // number of nodes
}
}
kibana {}
// important to include this in the cluster config to ensure to NOT override any existing remote cluster related config
# ignore changes to remote cluster config
lifecycle{
ignore_changes = [
elasticsearch[0].remote_cluster
]
}
}
在此要注意的几个重要位:
确保区域和ES版本对于您的群集一致。
默认情况下,deployment_template_id应定义为标准aws-storage-optimized-v3,但是如果您正在创建用于内存密集型工作的群集,请考虑将其创建为基于ARM的aws-general-purpose-arm-v6
节点的大小和数量根据需求而变化,因此请从弹性云UI中相应地确定。

始终添加群集部署的重要一点是忽略对远程群集配置的更改。这样可以确保群集之间配置的远程通信不会通过此更新而覆盖。
ignore_changes = [
elasticsearch[0].remote_cluster
]
示例:集群秘密
# Create the AWS Secret Manager secret
resource "aws_secretsmanager_secret" "<cluster-secret-name>" {
name = "/elasticsearch/<cluster-name>/credentials"
description = "Elasticsearch credentials for <cluster-name> cluster"
}
# Create the AWS Secret Manager secret version with JSON value
resource "aws_secretsmanager_secret_version" "<cluster-secret-name>" {
secret_id = aws_secretsmanager_secret.<cluster-secret-name>.id
secret_string = <<JSON
{
"endpoint": "${ec_deployment.<cluster-name>.elasticsearch.0.https_endpoint}",
"username": "${ec_deployment.<cluster-name>.elasticsearch_username}",
"password": "${ec_deployment.<cluster-name>.elasticsearch_password}"
}
JSON
}
示例:cluster_settings
resource "elasticstack_elasticsearch_cluster_settings" "<cluster-settings>" {
elasticsearch_connection {
username = ec_deployment.<cluster-name>.elasticsearch_username
password = ec_deployment.<cluster-name>.elasticsearch_password
endpoints = [ec_deployment.<cluster-name>.elasticsearch.0.https_endpoint]
}
persistent {
setting {
name = "cluster.max_shards_per_node"
value = "2500"
}
setting {
name = "cluster.routing.allocation.cluster_concurrent_rebalance"
value = "30"
}
setting {
name = "cluster.routing.allocation.node_concurrent_recoveries"
value = "30"
}
}
}
三个重要的设置将添加为默认的ð
是有意义的-
max_shards_per_node值将根据群集的大小和需求而有所不同 -
cluster_concurrent_rebalance允许对所有可用节点的碎片正确平衡(20-30是一个很好的价值) -
node_concurrent_recoveries允许对所有可用节点的碎片重新平衡(20-30是一个很好的价值)
上面的步骤将使用定义的配置创建群集。
始终很好地确保并检查我们的更改正在添加/更新/删除,以免谨慎,以免删除/更新某些现有资源。 ð
问题2:将新创建的弹性群集添加到dynamodb群集分配表中的簇池中
现在,新集群已并且可以在Elasticsearch上作为健康部署进行查看,我们可以采取下一个举措将其包括在可用簇列表中,以便能够将其用于我们的ES需求。
示例:

要将其添加到池中,您可以将其分配到定义群集分配的表格,在我们的情况下:ClusterAssignmentTable
要将您的新集群添加到此池中,请使用:
json=$(cat <<EOF
{
"pk": {"S": "POOL"},
"sk": {"S": "CLUSTER#${cluster_name}"},
"cluster": {"S": "${cluster_name}"},
"endpoint": {"S": "${endpoint}"},
"username": {"S": "${username}"},
"password": {"S": "${password}"}
}
EOF
)
echo "===> Storing cluster $cluster_name in table $table_name..."
aws dynamodb put-item \
--table-name $table_name \
--item "${json}"
因此,应在群集分配表中找到新的群集。
问题3:允许其访问与其他现有ES簇进行通信。
在处理多个ES簇时,需要从一个群集到另一个集群查询数据。在当前的实施中,我们已经有进行多ORG查询的用例,这些组织可能属于不同的群集。
用法看起来像:
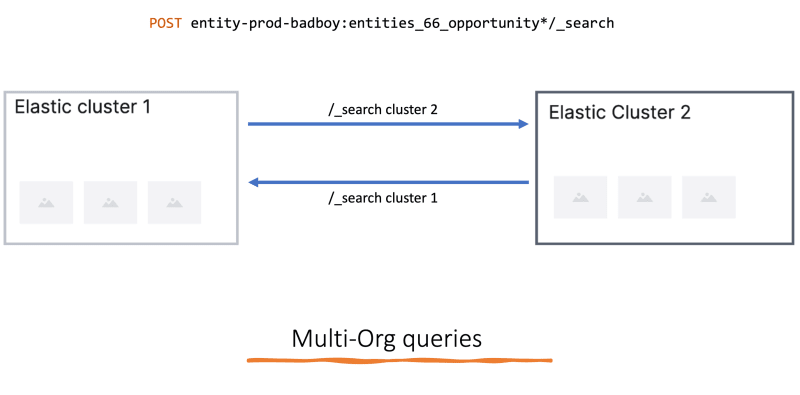
为了允许这一点,我们需要确保每次创建新集群时,它也为远程群集通信设置。
为此,您可以为池中的所有群集做类似的事情:
payload=$(cat <<EOF
{
"persistent": {
"cluster": {
"remote": {
"${remote_cluster}": {
"mode":"proxy",
"server_name": "${remote_server_name}",
"proxy_address": "${remote_proxy_address}",
"skip_unavailable": true
}
}
}
}
}
EOF
)
curl -sS -X PUT "$endpoint/_cluster/settings" \
-u "$username:$password" \
-H 'Content-Type: application/json' \
-d "$payload" | jq
这将确保设置该环境的所有群集,以互相远程通信。
另外,还记得我们还有一个额外的步骤可以忽略远程群集配置的更改吗?这就是为什么!我们不想在更新簇时覆盖任何远程配置更改。
在这一点上,您可以在Elasticsearch,集群分配表上准备好群集,并且还可以与其他群集交谈。
,然后有群集没有做得很好和健康的时间。
使用这些群集(甚至在将来更可能),我们想知道它们每个集团的下落,以更好地管理这些群集。
因此,特定的监视是一个好主意。我们使用datadog做到这一点。 Datadog提供了可用于相同的弹性云集成。

类似上面的东西
希望这会有所帮助!