以自动化的方式与工具(Puppeteer,剧作家)自动提取数据,这是数据科学家,软件开发人员和研究分析师用来收集信息作为竞争性分析的信息,比较电子商务网站上的价格,并构建发送电子邮件通知的应用程序,以监视旅行领域的价格变化。
使用BRIGHT DATA Scraping Browser和GPT(生成的预训练的变压器)来收集有关产品的宝贵见解,无论您是您的产品还是任何其他竞争对手,对于获得可行的见解至关重要反馈;分析的负和阳性。例如,我们将演示用户在Udemy Learning Platform上发布的评论的评论如何有所帮助。
利用这项技术不仅可以为个人服务。品牌或公司可以使用它来了解人们对产品的评价。
您将在本文中学习的所有内容都是出于道德目的。这就是为什么Bright Data被用来将网站变成对任何用户有意义的结构化数据,而不会被阻止或对限制进行评分或使用API(应用程序编程接口)。
让我们开始!
github
在this repo中找到源代码。分叉并克隆它自己进行测试。
请注意,它在一个名为评论的文件夹中包含frontend应用程序,分别显示了Udemy和GPT的评论和建议数据,以及节点服务器, head> head beadless-web--刮擦将刮擦数据保存在JSON(JavaScript对象符号)文件中。
演示
有关客户端应用程序的实际演示,请查看here。
先决条件
在构建或编写代码线之前,请检查以下要求:
- Node.js >=16,因为这将与软件包管理器NPM 一起安装
- 对JavaScript和React的知识
- 像VS Code或任何其他(IDE)集成开发环境这样的代码编辑器
- 对CSS的基本理解
设置明亮的数据刮浏览器
刮擦浏览器与Puppeteer和Playwright兼容,该网站附带了buall构建的动作。
在Bright Data网站上开始,sign up(免费),它带有20美元/gb的“无承诺”计划。

使用明亮数据架构的一些重要好处是:
- 快速
- 灵活
- 成本效益
发现如何利用您的优势。
注册后,转到仪表板,单击代理并刮擦基础架构窗户的左窗格。

接下来,单击添加按钮下拉菜单,然后选择刮擦浏览器。在解决方案名称字段下给代理一个名称,然后单击添加按钮继续。

下一个屏幕将显示主机,用户名和密码用于导航刮擦浏览器的值。
让我们通过安装样板来运行项目。
安装
通常,在本节中,您将学习使用node.js和vite初始化和创建新样板的基础知识。 Node.js中的Web Scraper将处理用于检索和存储Web数据的脚本,而React中的UI(用户界面)将显示服务器和GPT的信息。
在此项目中,创建一个文件夹,该文件夹将同时保存前端代码和后端代码:
.
└── Bright_data
├── headless-web-scraping
└── reviews
node.js
要设置一个节点项目,首先,使用终端中的命令创建一个新目录:
mkdir headless-web-scraping
接下来,更改其目录:
cd headless-web-scraping
初始化项目:
npm init -y
-y标志在没有交互提示的情况下接受所有默认值,这是package.json文件中项目的问题。
package.json将通过安装以下内容包含所有依赖项:
npm install dotenv puppeteer-core
-
dotenv:该库负责将环境变量从.env文件加载到process.env -
puppeteer-core:这是一个没有浏览器本身的自动化库
现在,在根目录中创建index.js文件,然后复制此代码:
index.js
console.log("Hello world!")
在运行此脚本之前,请前往package.json文件,然后以下更新脚本部分:
{
"name": "headless-web-scraping",
...
"scripts": {
"start": "node index.js"
},
...
}
运行脚本:
npm run start
这应该返回:
Hello world!
react
该应用程序的UI文件夹称为评论。在目录中运行此命令评论脚手架一个新的Vite React项目。
npm create vite@latest ./
./表示所有文件和文件夹都应在文件夹中。此外,运行命令将在终端中提示响应。选择 React 和 JavaScript 选项,但是您可以使用您舒适使用的任何其他框架。
设置完成后,请确保按照终端中的说明安装依赖项,并使用命令启动开发服务器:
npm install
npm run dev
打开浏览器以查看UI和服务器在端口5173上运行。
现在是时候包括 tailwind CSS ,一个CSS公用事业领先的框架,其中包含用于构建现代网站的JSX上的类。
查看this guide,并按照在 vite 项目中安装尾风CSS的说明。
在node.js中创建JavaScript Web刮板
返回到您创建的区域上的访问参数选项卡,并复制主机和用户名值。
创建环境变量
环境变量在node.js中至关重要,用于存储敏感数据,例如秘密键和未经授权访问的凭据。
复制并将这些值粘贴到根文件夹中创建的.env文件中:
.env
AUTH="<AUTH>"
HOST="<HOST>"
要加载这些凭据,请使用以下内容更新index.js:
index.js
const puppeteer = require("puppeteer-core");
require("dotenv").config();
const fs = require("fs");
const auth = process.env.AUTH;
const host = process.env.HOST;
async function run() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@${host}`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto(
"https://www.udemy.com/course/nodejs-express-mongodb-bootcamp/"
);
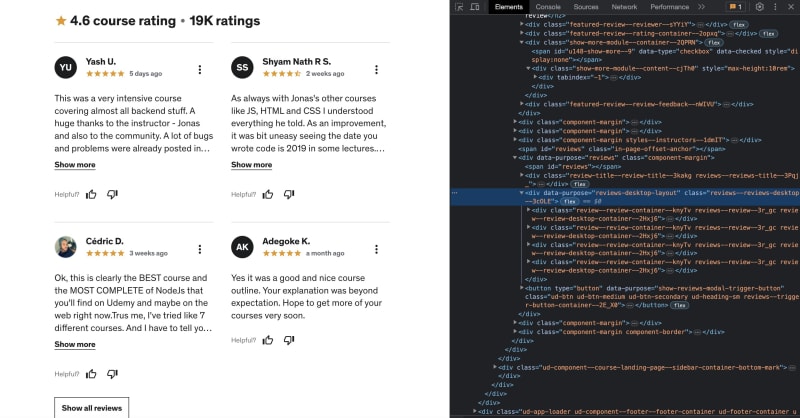
const reviews = await page.evaluate(() =>
Array.from(
document.querySelectorAll(
".reviews--reviews-desktop--3cOLE .review--review-container--knyTv"
),
(e) => ({
reviewerName: e.querySelector(".ud-heading-md").innerText,
reviewerText: e.querySelector(".ud-text-md span").innerText,
id: Math.floor(Math.random() * 100),
})
)
);
const outputFilename = "reviews.json"
fs.writeFile(outputFilename, JSON.stringify(reviews, null, 2), (err) => {
if (err) throw err;
console.log("file saved");
});
} catch (e) {
console.error("run failed", e);
} finally {
await browser?.close();
}
}
if (require.main == module) run();
上面的代码中要注意的一些事情:
- 导入的模块,
puppeteer-core,dotenv和file system - 在
run()功能中,puppeteer.connect()方法负责使用代理服务器(明亮的数据刮浏览器)连接到远程浏览器 -
browserWSEndpoint属性是远程浏览器正在运行的Websocket连接。作为模板文字传递的值是来自Bright Data Web UI仪表板的参数,该参数代表用户名 和 password
上面的代码块中的其他详细信息是标准木偶代码:
- 启动一个新页面
- 将默认导航时间设置为2分钟
- 转到Udemy上的课程页面
- 使用
page.evaluate()方法检查HTML页面,该方法将循环遍历DOM中的元素,以获取审阅者名称和 评论文本
- 使用
Math.floor()方法生成随机id - 使用JSON格式的
fs模块保存结果的输出
运行脚本:
npm run start
输出保存在无头 - web-scraping 文件夹中,如reviews.json,应该看起来像这样:
[
{
"reviewerName": "Yash U.",
"reviewerText": "This was a very intensive course covering almost all backend stuff. A huge thanks to the instructor - Jonas and also to the community. A lot of bugs and problems were already posted in the Q&A section and it helped a lot. Towards the end of the course, there were a few things that were outdated and a lot of people were disappointed in the comments but for me these things helped a lot. You learn to search and find solutions on your own and this is what is required in real world. Hence, despite these issues towards the end, I would absolutely recommend this course to anyone who wants to start learning backend development.",
"id": 11
},
{
"reviewerName": "Shyam Nath R S.",
"reviewerText": "As always with Jonas's other courses like JS, HTML and CSS I understood"
},
...
]
使用GPT
假设您没有帐户。 Sign up并创建一个。
从对象中复制reviewerText之一,然后将其粘贴到chatgpt中。要进行演练,请观看下面的视频。
您应该得到类似的东西:

建议或改进:

在React中创建UI
React是开发人员使用的JavaScript库,用于构建具有可重复使用组件的用户界面。
现在,我们有了评论和建议,请创建UI以显示数据。
在评论项目中,创建一个新文件夹,称为组件在SRC目录中使用以下文件:
.
└── reviews
└── src
└── components
├── Footer.jsx
├── ImproveSuggestion.jsx
├── ReviewImprovementSuggestions.jsx
├── Reviews.jsx
└── Text.jsx
此外,让我们在一个名为 reviews.js的对象中创建一个来自 gpt 的响应的文件:
src/data/reviews.js
.
└── reviews
└── src
└── data
└── reviews.js
在此gist中获取全部数据。
让我们相应地更新项目中的代码:
Footer.jsx
const Footer = () => {
return (
<>
<footer className='mt-auto'>
<div className='mt-5 text-center text-gray-500'>
<address>
Built by
<span className='text-blue-600'>
<a href='https://twitter.com/terieyenike' target='_'>
Teri
</a>
</span>
© 2023
</address>
<div>
<p>
Fork, clone, and star this
<a
href='https://github.com/Terieyenike/'
target='_'
rel='noopener noreferrer'
className='text-blue-600'>
<span> repo</span>
</a>
</p>
</div>
<p className='text-sm'>Bright Data .GPT .React .Tailwind CSS</p>
</div>
</footer>
</>
);
};
export default Footer;
如果您愿意,请更改JSX中的值。
ImproveSuggestion.jsx
const ImproveSuggestion = ({ suggestion }) => {
return (
<div>
<li className='mt-2'>{suggestion}</li>
</div>
);
};
export default ImproveSuggestion;
ReviewImprovementSuggestions.jsx
import ImproveSuggestion from "./ImproveSuggestion";
const ReviewImprovementSuggestions = ({ suggestions }) => {
return (
<div>
<h3 className='text-xl font-bold mt-3'>Improvement Suggestions:</h3>
<ul className='list-disc'>
{suggestions.map((suggestion, index) => (
<ImproveSuggestion key={index} suggestion={suggestion} />
))}
</ul>
</div>
);
};
export default ReviewImprovementSuggestions;
Reviews.jsx
import ReviewImprovementSuggestions from "./ReviewImprovementSuggestions";
const Reviews = ({ reviewerName, reviewText, improvementSuggestions }) => {
return (
<div className='mb-8'>
<h3 className='text-xl font-bold'>
<span>Reviewer name:</span>
</h3>
<p className='mb-3'>{reviewerName}</p>
<h3 className='text-xl font-bold'>
<span>Review:</span>
</h3>
<p>{reviewText}</p>
{improvementSuggestions && (
<ReviewImprovementSuggestions suggestions={improvementSuggestions} />
)}
</div>
);
};
export default Reviews;
Text.jsx
const Text = () => {
return (
<>
<div className='bg-emerald-800 text-slate-50 p-5 mb-10'>
<h1 className='text-2xl font-bold md:text-4xl'>
Using Scraping Browser and GPT for actionable product insights.
</h1>
<p className='text-sm mt-3 md:text-xl'>
Extract reviews from a specific product page{" "}
<span className='font-bold'>Udemy</span> using Bright Data, Scraping
Browser and GPT to analyze them to offer business insights.
</p>
</div>
</>
);
};
export default Text;
上面组件中的某些代码片段是由于道具从一个组件到另一个组件的钻探而导致的。查看React documentation以了解更多信息。
React UI仍将在浏览器中显示默认样板模板。为了显示组件中文件的当前更改,我们使用此代码更新项目的输入点App.jsx:
src/App.jsx
import Reviews from "./components/Reviews";
import Text from "./components/Text";
import Footer from "./components/Footer";
import { reviews } from "./data/reviews";
import "./App.css";
function App() {
return (
<>
<div className='flex flex-col container mx-auto max-w-6xl w-4/5 py-8 min-h-screen'>
<Text />
{reviews.map((review) => (
<Reviews
key={review.id}
reviewerName={review.reviewerName}
reviewText={review.reviewText}
improvementSuggestions={review.improvementSuggestions}
/>
))}
<Footer />
</div>
</>
);
}
export default App;
启动开发服务器将像这样显示项目:

结论
因为它避免了网站禁令并与木偶器这样的库无缝合作,所以明亮的数据刮浏览器是需要提供高质量刮擦数据的开发人员的绝佳选择。
刮擦网络会带来困难,因为访问公司的端点可能会导致阻塞。因此,存在诸如CAPTCHAS和其他技术之类的预防措施来保护用户数据。
在本课程中,您可以深入了解检查网页元素并使用node.js提取必要的数据,以从Udemy收集用户信息并将其存储在JSON文件中。该项目的最后一步是使用GPT提供有见地的信息并在用户界面中显示结果。
最后,使用这些服务和工具可以为品牌,公司或个人提供充分对齐产品以满足客户期望的方法。对于 Udemy 案例研究,GPT提供了改进和使课程适合学习者的方法。鼓励网页以实际产品用户的评论形式允许评论,这将有助于使用GPT技术进行批判性分析。
今天尝试Scraping Browser!