让我们假设您有一项任务,需要从数组中删除重复的项目,始终考虑使用最新日期的项目。为了简化对象,对象在Koud0结构中。
输入数组的示例:
[
{ id: 3, date: '2023-01-03T00:00:00.000Z' },
{ id: 3, date: '2023-01-04T00:00:00.000Z' },
{ id: 4, date: '2023-01-02T00:00:00.000Z' },
{ id: 3, date: '2023-01-02T00:00:00.000Z' },
]
预期的结果将是一个带有IDSâgnics
的阵列
[
{ id: 3, date: '2023-01-04T00:00:00.000Z' },
{ id: 4, date: '2023-01-02T00:00:00.000Z' },
]
您是否知道如何以良好的性能进行大规模处理项目?解决问题的想法是什么?
在本文中,我们将以最高格式生成一个随机数据阵列,以测试代码的性能:
const randomInt = (limit) => Math.floor(Math.random() * limit);
const array = Array.from({ length: 100000 }).map((_, idx) => ({
id: randomInt(100),
date: new Date(2023, 0, randomInt(31), 0, 0, 0),
}));
解决此问题的一种常见思维方法是创建一个座右铭,该座右铭是使用Reald和/或For过滤数组项目的座右铭。对于每个数组项目,我们发现如果数组中的ID已经存在,如果它不存在,则添加它,如果我们存在,则检查新项目的更新是更新的
const removeDuplicates = (array) => {
const uniqArray = [];
for (let i = 0; i < array.length; i++) {
const item = array[i];
const index = uniqArray.findIndex((i) => i.id === item.id);
if (index === -1) {
uniqArray .push(item);
continue;
}
if (item.date > uniqArray[index].date) {
uniqArray[index] = item;
}
}
return uniqArray;
}
这种方法以相对简单的方式解决了问题。我们可以检查该功能导致处理最初生成的输入文件的执行时间。
const startTime = new Date();
removeDuplicates(array);
console.log(`Took: ${new Date() - startTime}ms`)
![]()
35毫秒在数组中处理100,000个物品,它的时间不长,并且停止思考。因为是,但是a了骗子的恶作剧。这种方法的问题绝对不是最好的。这是因为我们彼此之间有2个循环,不同数据的数量越大,这次敢于表演的悲伤母亲就越痛苦。
如果我们查看数据库,则只有100个不同的ID。这意味着在最坏的情况下,第二个循环仅进行100次迭代。这也意味着存在越多的ID,延迟时间越长。拥有1,000个不同的ID,需要170毫秒,而10,000个ID需要1379ms,是的,超过一秒钟。
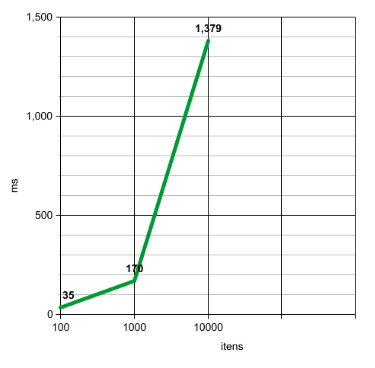
执行时间的增长是指数的。但是如何改进该算法。
让我们看看Chatgpt的想法:
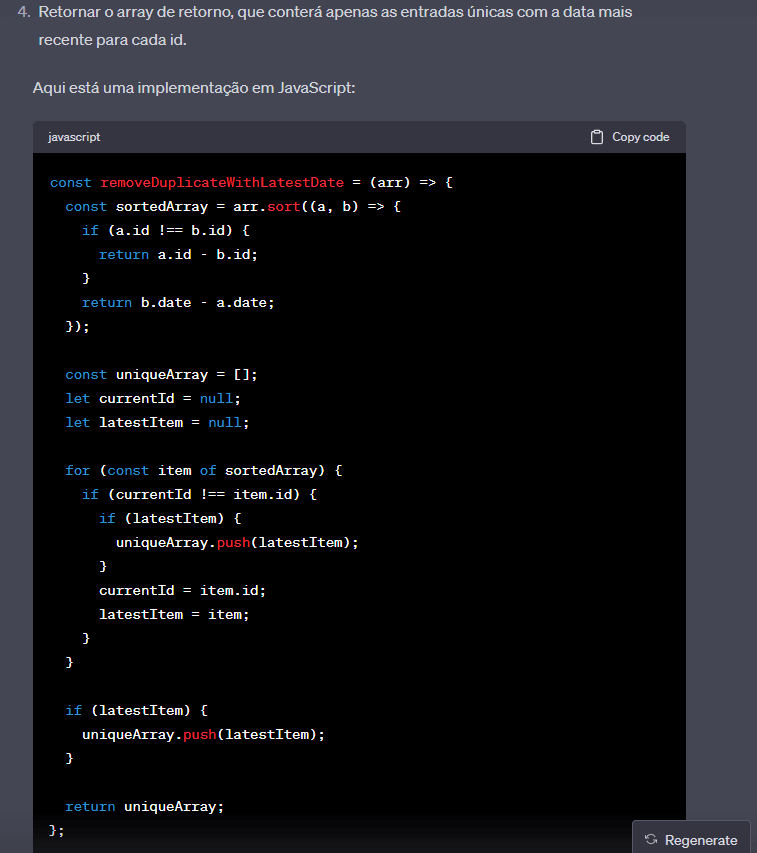
我承认,通过我没想到的这种算法,他正在按照ID订购数组。这样,他可以一次检查一个ID,而无需在所有无序阵列中完成查找和Loopar。因此,为了说明,他首先检查ID 1,比较并意识到哪一个是最新的,并且当他到达ID 2时,存储了最新的ID 1项目,他开始在结尾检查ID 2,依此类推。
让我们开始使用工具比较算法,我将在这里使用该算法。该站点允许您启动数据质量并比较每种方法之间的执行时间。该站点在不同时间执行相同的操作,因此我们将使用的数组的初始数量将稍小,只有10,000至最初的100,000个发明,以最大程度地减少执行时间O。
我将比较只有10个ID的情况。这意味着几乎所有数据量都由重复的项目组成,并且ID范围从1到9,000,例如,随机生成的随机pro ID没有人可以确保只有1,000只复制,但我们保证很可能有很多ID。
不进一步的ADO,我们比较了两种方法的性能:
Cenãrio只有10个ID:

cenâriocom 9.000 ids:

GPT代码性能在风景中更糟糕的是,在风景中,在无限的场景中,几乎没有重复性的场景中有更多的重复性和更好的场景。
但是,如果有第三种方式怎么办?可能会有可能吗?
好吧,当我们在JavaScript中创建一个对象时,它就像是数据的“词典”一样,直接引用与值链接到值的所有“键”。在这种情况下,我们会利用此属性吗?const removeDuplicatesKeyMap = (array) => {
const keyMap = {};
for (let i = 0; i < array.length; i++) {
const item = array[i];
if (!keyMap[item.id]) {
keyMap[item.id] = item;
continue;
}
if (item.date > keyMap[item.id].date) {
keyMap[item.id] = item;
}
}
return Object.values(keyMap)
}
以上创建一个对象,索引键,例如数组ID和值作为对象对象的反射。所以数组将变成类似的东西:
{
3: { id: 3, date: '2023-01-04T00:00:00.000Z' },
4: { id: 4, date: '2023-01-02T00:00:00.000Z' },
}
每当需要一个数组项目时,我们都可以通过您的索引直接访问它,就好像它是普通属性一样。 keyMap[3]将返回{ id: 3, date: '2023-01-04T00:00:00.000Z' }对象。因此,可以根据每个项目的ID轻松访问所有项目。
好吧,理论看起来不错,让我们在实用中看看:
具有10个不同的ID:
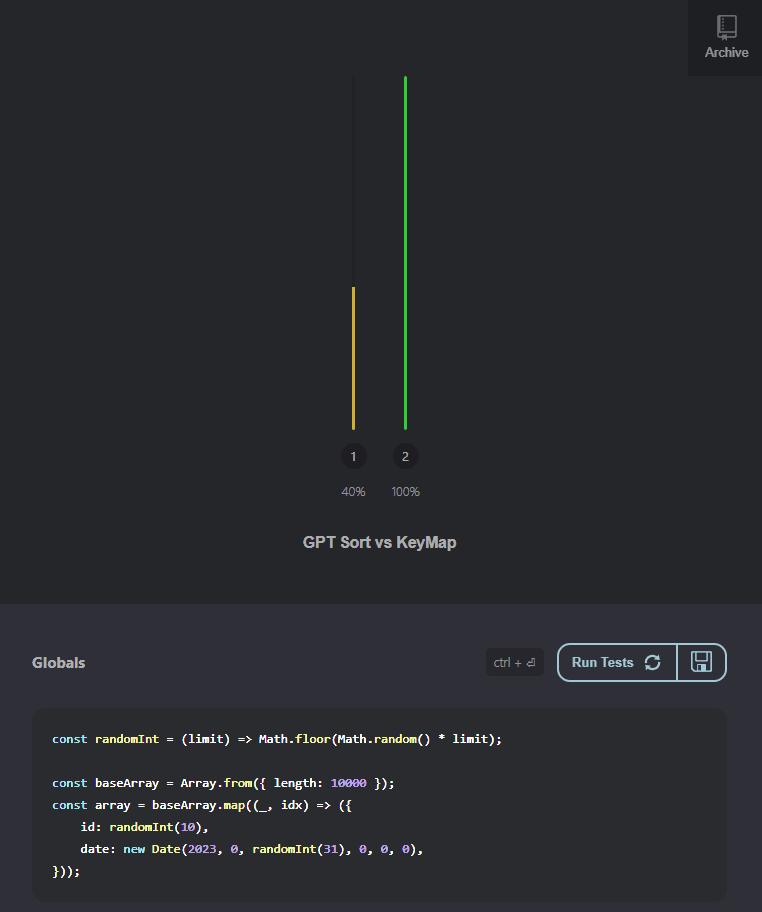
具有9,000个不同的ID:

ð¥boooom - ¥,拿这gpt,今天你已经克服了!!!
(就在今天哈哈哈)
当我发现这种技术时,我发现它非常有趣,我研究了解决这个问题的其他方法,但这是我想到的最好的方法。
必要时也可以将此技术用于in memory join。
记住,还有许多其他方法可以改善应用程序的体系结构,以免一次执行这么多项目。但是我认为,在我的视野中,永远不会太多!
我建议从本文中获取的内容总是试图理解和探索解决相同问题的不同方法。
您知道您知道这种策略吗?您知道解决同样问题的其他策略吗?与我们分享以下ð