随着数据量的不断增长,业务的复杂性逐渐增加,我们在数据处理效率方面面临着巨大的挑战。最典型的表现是数据仓库的性能问题在处理分析任务时越来越突出,并且不时发生一些问题,例如高计算压力,低性能,长时间查询时间甚至找不到结果,由于未能按时完成批处理作业而导致的生产事故。当数据仓库存在性能问题时,它不能很好地服务于业务。
传统数据仓库绩效问题的解决方案
让我们从最常见的解决方案开始 - 群集,即使用分布式技术,并依靠扩展硬件来提高性能。可以肯定的是,将大型任务分开到群集的每个节点,以使节点同时计算比在单个节点上执行此任务更好的性能。即使我们不进行分布式计算,而只是共享一个并发任务,我们也可以降低单个节点的计算压力。解决性能问题的集群的想法简单而粗糙。只要数据仓库支持集群并可以分开任务,就可以通过添加硬件资源来解决性能问题。尽管该解决方案可能无法提高线性性能,但基本上将起作用。
集群的缺点是高成本。在当前的大数据时代,我们不可避免地提及涉及性能提高时群集,并且通常会忽略单个节点的性能是否全面发挥作用,因为我们认为只要添加硬件资源的方法就可以了支持集群。因此,在许多人眼中,该集群可能是一种灵丹妙药。但是,我们应该注意,集群需要更多的硬件资源,成本自然会很高,并且集群的运行和维护也需要投资更多。此外,某些复杂的多步计算任务根本无法利用群集,因为它们可以分开。例如,只能使用一个节点(单个数据库存储过程)执行涉及大数据量的大多数多步批处理作业。尽管集群是一个很好的解决方案,但它不是灵丹妙药。即使我们有足够的钱来建立一个集群,我们也无法解决所有绩效问题。
对于一些耗时的查询任务,我们可以采用预计解决方案,也就是说,使用交易空间的方法,以便时间处理要预先查询的数据。这样,计算复杂性就可以降低到O(1),并且可以大大提高效率。同样,该解决方案可以解决许多性能问题。预处理要计算的数据并提前处理它们可以交换时间,这对于多维分析方案特别有效。
然而,该溶液的缺点在柔韧性上极为差。例如,在多维分析中,尽管从理论上讲可以预先计算所有维度组合(这将满足所有查询要求),但我们在实践中会发现它是不现实的,因为它需要庞大,因此我们必须在整理业务后进行部分预计,这极大地限制了查询范围并降低了灵活性。
实际上,即使执行了完整的预计,它仍然可以解决某些情况,例如非常规的聚合(例如计算中位数和方差),结合聚合(例如计算平均每月销售),例如计算平均每月销售)有条件的度量(例如,计算交易金额大于100美元的订单的总销售),时间段汇总(在自由选择的时间段内进行汇总)。现实世界中的查询要求多样性和高度灵活,预聚类只能解决一部分甚至一小部分要求。为了满足更广泛范围内的各种在线查询要求,需要更有效的计算方法。
更有效的解决方案是优化引擎,它可以使数据仓库在相同的硬件资源下运行速度更快。该解决方案已成为许多供应商的焦点,它们提供了许多工程手段,这些手段在行业中已经众所周知,例如柱状存储,矢量执行,编码压缩和内存利用率(群集也可以视为工程意义) 。通过这些手段,只要数据量在一定范围内,并且可以完全满足某些情况的计算要求,则可以将计算性能提高几次。不幸的是,这些工程工程无法改变计算复杂性,并且在数据量较大的情况下,改进的性能仍然无法满足计算要求,或者复杂性特别高。
。更有效的优化引擎的方法是在算法水平上提高性能(在复杂性水平上提高)。良好的数据仓库优化引擎可以猜测查询语句的真实意图,并采用更有效的算法来执行该语句(而不是根据字面表达的逻辑执行)。算法级别的改进通常使得实现更高的性能是可能的。当前,大多数数据仓库仍然使用SQL作为主要查询语言,并且基于SQL的优化已经做得很好。但是,由于SQL描述能力的局限性,必须采用非常循环的方法来进行复杂的查询任务。一旦SQL语句的复杂性增加了,优化引擎将很难发挥作用(它无法猜测陈述的真正意图,并且必须根据字面上表达的逻辑执行,而是导致未能改善该逻辑表现)。简而言之,优化引擎仅适用于简单查询任务。
让我们举个例子,以下代码是计算topn:
SELECT TOP 10 x FROM T ORDER BY x DESC
大多数数据仓库都会优化任务,而不是进行真实的排序。但是,如果我们想查询小组内topn:
select * from
(select y,*,row_number() over (partition by y order by x desc) rn from T)
where rn<=10
正如我们所看到的,尽管该计算的复杂性并不比上一个计算的复杂性高得多,但优化引擎会变得困惑,无法猜出其真正的意图,因此它必须根据大分进行大规模分类从字面上表达的含义,导致性能低。因此,在某些情况下,我们将提前将数据处理到宽表中,以便我们可以简化查询并将优化引擎投入使用。虽然价格很高,但有时我们必须这样做才能有效地利用优化引擎。
目前,几乎所有数据仓库供应商都在争夺SQL能力。例如,他们竞争提供更全面的SQL支持,提供更强的优化能力并支持更大的群集等等。尽管这些动作可以在很大程度上取悦广泛的SQL用户,但面对复杂的计算情况,上述手段通常效率较低,并且仍然存在性能问题。无论他们在SQL(工程优化)上有多努力,效果都不令人满意,也从根本上解决了性能问题。这种类型的性能问题在实践中很常见,以下是一些示例。
复杂的有序计算:通过转换漏斗分析用户行为时,它涉及多个事件,例如页面浏览,搜索,添加到购物车,下订单和付款。为了计算每个事件后用户流动率,我们需要遵循一个原则,即这些事件在指定的时间窗口内完成,并以指定顺序进行,只有以这种方式,我们才能获得有效的结果。如果在SQL中实现此任务,则将非常困难,并且必须在多个子征服(事件数量)和重复关联的帮助下实施。结果,SQL语句将非常复杂,并且某些数据仓库甚至无法执行此类复杂的语句,即使可以,性能也很低,而且很难优化。
涉及大数据量的多步批处理作业。对于复杂的批处理作业,SQL也无法正常工作。在存储过程中,SQL通常需要使用光标逐步读取数据。由于光标的性能非常低并且无法并行计算,因此最终导致资源消耗率高和计算性能较低。此外,存储过程中的数十个操作步骤需要数千行代码,并且需要反复缓冲计算过程中的中间结果,这进一步降低了性能,从而导致一个现象,即无法按时完成批处理作业。到达有大量数据和许多任务的月/年末的时间。
大数据上的多指数计算。许多行业需要计算指数。例如,在银行贷款业务中,不仅有多个分类维度和多种保证类型的层,而且还有许多其他维度,例如客户类型,贷款方式,货币类型,分支机构,分支机构,日期,客户年龄范围和教育背景。如果我们自由地结合它们,将得出大量的索引。需要根据大量详细数据进行汇总这些索引,并且计算将涉及多种类型的混合操作,例如大桌关联,条件过滤,分组和聚合以及删除和计数。此类计算具有灵活性,数据量且复杂性较大,并且伴随着高并发性,这使得在SQL中很难实现。如果我们采用前计算解决方案,它是不灵活的,而实时计算太慢。
由于很难在SQL中解决这些问题,因此扩展SQL的计算能力成为群集,预估算和优化引擎之后的第四个解决方案。如今,许多数据仓库使用用户定义的功能(UDF)支持以扩展功能,并允许用户根据实际要求编写UDF以满足自己的需求。但是,UDF很难开发,并且要求用户具有高技术技能。更重要的是,UDF仍然无法解决数据仓库的计算性能问题,因为它仍然受数据库的存储限制,从而导致无法根据计算特性设计更有效的数据存储(组织)表单。结果,无法实施许多高性能算法,因此自然无法实现高性能。
因此,为了解决这些问题,我们应该采用基于非SQL的解决方案,让程序员控制数据库之外的执行逻辑,以更好地利用低复杂性算法并充分利用工程手段。<<<<<<<<<<<<<<<<<<<<<<<<<<< /p>
当我们分析时,出现了一些大数据计算引擎。 Spark提供了一个分布式计算框架,并且仍旨在通过大规模集群满足计算能力的需求。由于基于全书操作的设计对外部存储的计算不太友好,并且RDD采用了不可变的机制,因此在每个计算步骤后将复制RDD CPU资源和非常低的性能以及工程手段尚未充分利用。此外,Spark并不丰富计算库,缺乏高性能算法,因此很难实现低复杂算法的目标。此外,Scala非常困难,这使得面对上述复杂的计算问题非常困难。难以编码并且无法实现高性能可能是Spark再次使用SQL的原因之一。
由于传统数据仓库不起作用,而且外部编程(SPARK)很困难且缓慢,还有其他选择吗?
从上面的讨论中,不能得出结论,要解决数据仓库的性能问题,我们确实需要一个独立于SQL的计算系统(例如SPARK),但是,该系统应该具有易于的特征在编码和运行方面。具体而言,在描述复杂的计算逻辑时,该系统不应该像火花那样复杂,甚至应该比SQL更简单。该系统不应仅依靠计算性能的群集,并且应该提供丰富的高性能算法和工程能力,以充分利用硬件资源并最大程度地提高单个节点的性能。简而言之,该系统不仅应该具有快速描述低复杂性算法的能力,而且还应具有足够的工程意义。此外,如果可以轻松部署,操作和维护系统,那将是理想的。
ESPROC SPL解决方案
ESPROC SPL是一种计算引擎,专门用于处理结构化和半结构化数据,具有相同的功能,具有当前数据仓库的能力。但是,与传统的基于SQL的数据仓库不同,ESPROC不继续采用关系代数,而是设计了一个全新的计算系统,该系统基于SPL(结构化过程语言)语法的开发。与SQL相比,SPL具有许多优势。具体而言,它提供了更多的数据类型和操作,更丰富的计算库以及更强的描述能力;在程序计算的支持下,它使我们能够根据自然思维编写算法,而不必以回旋的方式进行编码,从而使SPL代码短。它具有足够的能力实现前面提到的多步复杂计算,这比SQL和其他硬编码方法更简单。
涉及性能,ESPROC SPL提供了许多高性能算法的“复杂性”,以确保计算性能。我们知道软件不能改变硬件的性能,在相同的硬件条件下实现较高计算性能的唯一方法是设计较低复杂性的算法,以使计算机执行更少的基本操作,这自然会使计算速度更快。但是,设计低复杂性算法还不足,还需要实现它们的能力,并且编码越简单,性能越好。因此,易于编码和快速运行是同一件事。
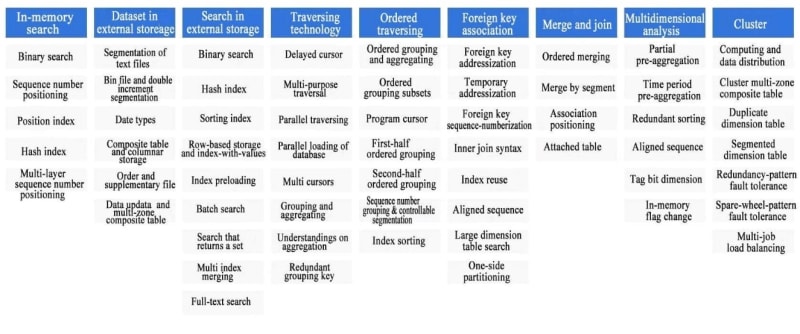
该图显示了SPL提供的高性能算法的一部分,其中许多是Spl的原始发明。
当然,如果没有良好的数据组织(数据存储模式),高性能算法就无法做到。例如,只有当数据存储在顺序时,才能实现有序合并和单方面分区算法。但是,数据库的存储相对封闭,不能在外部干扰,从而导致未根据计算特征设计存储。因此,SPL提供了自己的二进制文件存储,也就是说,将数据存储在数据库外部的文件系统中,以充分利用多个数据存储模式的优势,例如柱状存储,订购,压缩和并行分割,并实现根据计算特征灵活组织数据的目标,并充分利用高性能算法的有效性。
除了高性能算法外,ESPROC还提供了许多工程手段来改善计算性能,例如柱状存储,编码压缩,大型内存和基于向量的计算。如上所述,尽管这些工程意味着无法改变计算复杂性,但它们通常可以提高性能几次。通过这些手段,加上SPL中构建的许多低复杂性算法,一个或两个数量级的性能提高也成为了常态。
如上所述,如果我们想基于非SQL系统实现高性能,我们必须控制执行逻辑,采用低复杂性算法并充分利用各种工程手段。与SQL不同,SPL的理论系统为我们带来了强大的描述能力和更简单的编码方法,而无需以回旋的方式进行编码,并允许我们直接使用其丰富的高性能算法库和相应的存储机制,从而实现在采用低复杂性算法的同时,充分利用工程优化的目的,以及简单地编码和快速运行的效果。
例如,顶部被认为是SPL中的普通聚合操作。无论是计算完整集还是分组子集的顶部,SPL的处理方法都是相同的,也无需进行大量排序。通过这种方式,实现了使用低复杂性算法的目的,以及高性能。
再次以上述转换渠道为例,以感受SQL和SPL之间的区别。
SQL代码:
with e1 as (
select uid,1 as step1,min(etime) as t1
from event
where etime>= to_date('2021-01-10') and etime<to_date('2021-01-25')
and eventtype='eventtype1' and …
group by 1),
e2 as (
select uid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from event as e2
inner join e1 on e2.uid = e1.uid
where e2.etime>= to_date('2021-01-10') and e2.etime<to_date('2021-01-25')
and e2.etime > t1 and e2.etime < t1 + 7
and eventtype='eventtype2' and …
group by 1),
e3 as (
select uid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from event as e3
inner join e2 on e3.uid = e2.uid
where e3.etime>= to_date('2021-01-10') and e3.etime<to_date('2021-01-25')
and e3.etime > t2 and e3.etime < t1 + 7
and eventtype='eventtype3' and …
group by 1)
select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from
e1
left join e2 on e1.uid = e2.uid
left join e3 on e2.uid = e3.uid
SPL代码:
A
1 =["etype1","etype2","etype3"]
2 =file("event.ctx").open()
3 =A2.cursor(id,etime,etype;etime>=date("2021-01-10") && etime<date("2021-01-25") && A1.contain(etype) && …)
4 =A3.group(uid).(~.sort(etime))
5 =A4.new(~.select@1(etype==A1(1)):first,~:all).select(first)
6 =A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null))))
7 =A6.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3)
我们可以看到,在有序计算的支持下,SPL代码较短,因为SPL允许我们根据自然思维逐步编码(过程计算)。此外,此代码可以处理涉及任意数量步骤的漏斗分析(此示例中的3个步骤)。当步骤数增加时,我们只需要修改参数。因此,SPL显然比SQL更有利,SQL需要为每个额外步骤添加一个子查询,这受益于SPL的简单编码。
在性能方面,SPL仍然具有明显的优势。这个示例实际上是一个简化的真实情况。在实际情况下,SQL代码几乎具有200行。用户在 3分钟之后没有得到结果在雪花的中型服务器上运行(相当于4*8 = 32核),而用户的结果少于 10秒 >在12核和1.7G低端服务器上执行SPL代码时。这受益于SPL的高性能算法和相应的工程手段。
使用这些机制,ESPROC SPL可以充分利用硬件资源,并最大程度地提高单个节点的性能。结果,ESPROC SPL不仅可以有效地解决一个单个节点的许多原始性能问题,而且即使最初需要用群集求解的许多计算也可以通过单个节点(可能更快)解决,从而实现了计算效果仅使用一个节点来群集。当然,一个节点在计算能力方面受到限制。为了解决此问题,SPL还提供了分布式技术,当单个节点在任何情况下都无法满足计算要求时,我们可以通过群集扩展计算能力,这是SPL的高性能计算理念:首先提高单个节点的性能到极端,然后当一个节点的计算能力不足。
时转向群集。可以肯定的是,任何技术都有缺点,SPL并不例外。 SQL已经开发了数十年,许多数据库已经具有强大的优化引擎。对于适合在SQL中实施的简单操作,优化引擎可以优化普通程序员编写的慢速语句并实现更好的性能。从这个意义上讲,程序员的要求相对较低。某些方案(例如多维分析)已经优化了多年,并且某些SQL发动机已经能够很好地实施此类情况并实现极端性能。相比之下, SPL在自动优化方面几乎没有。,几乎完全取决于程序员写低复杂性代码以实现高性能。在这种情况下,程序员需要接受一些培训,以便在开始使用SPL之前熟悉SPL的理念和图书馆功能。尽管与SQL相比,这是额外的一步,但通常值得,因为它使我们能够通过数量级来提高性能,并将成本降低几次。
SPL源代码:https://github.com/SPLWare/esProc
来源:https://blog.scudata.com/the-performance-problems-of-data-warehouse-and-solutions/