问题
考虑具有以下模式的Employees表:
| 列名 | 类型 |
|---|---|
| 雇员 | int |
| 名称 | varchar |
| reports_to | int |
| 年龄 | int |
employee_id是该表的主要键。该表包含有关员工和他们报告的经理ID的信息。一些员工不向任何人报告(reports_to是无效的)。对于这个问题,经理被定义为至少有另一名员工向他们报告的员工。任务是编写一个SQL查询,以报告所有经理人的ID和名称,直接向他们报告的员工人数以及报告的平均年龄四舍五入到最近的整数。
解释
考虑以下Employees表:
| 员工_id | 名称 | reports_to | 年龄 |
|---|---|---|---|
| 9 | hercy | null | 43 |
| 6 | 爱丽丝 | 9 | 41 |
| 4 | 鲍勃 | 9 | 36 |
| 2 | 温斯顿 | null | 37 |
预期的输出将是:
| 员工_id | 名称 | reports_count | 平均_age |
|---|---|---|---|
| 9 | hercy | 2 | 39 |
在这里,赫西有两个人直接向他报告爱丽丝和鲍勃。他们的平均年龄为(41+36)/2 = 38.5,将其四舍五入到最近的整数后。
解决方案
我们将讨论解决此问题的四种不同的SQL方法,解释了它们的主要差异,优势,劣势和基础结构。
源代码1:加入和组
此代码使用JOIN操作根据它们之间的相关列组合两个或多个表的行。
SELECT
m.employee_id,
m.name,
COUNT(e.reports_to) [reports_count],
ROUND(AVG(e.age * 1.0), 0) [average_age]
FROM Employees e JOIN Employees m ON e.reports_to = m.employee_id
GROUP BY
m.employee_id,
m.name
ORDER BY m.employee_id
小组按子句组小组employee_id和name来自m别名(经理),计算报告计数和平均年龄。 ROUND功能用于将平均年龄圆成最接近的整数。然后由employee_id订购结果。
此查询运行时为1559ms,在LeetCode上击败了其他提交的33.60%。

源代码2:子查询,加入和组
此代码在执行加入操作之前先利用子查询来首先隔离所需的列,从而有可能提高性能。
SELECT
m.employee_id,
m.name,
COUNT(e.reports_to) [reports_count],
ROUND(AVG(e.age * 1.0), 0) [average_age]
FROM (
SELECT
reports_to,
age
FROM Employees
) e JOIN (
SELECT
employee_id,
name
FROM Employees
) m ON e.reports_to = m.employee_id
GROUP BY
m.employee_id,
m.name
ORDER BY m.employee_id
通过将reports_to和age分开,在子查德e中,以及子查询m中的employee_id和name,联接操作可能更快。此查询的运行时间为1446ms,超过了Leetcode上其他提交的46.6%。

源代码3:子查询,加入,组和计算平均
此代码还使用子征服来进行联接操作,但是通过明确计算总和除以计数,它以不同的方式计算平均值。
SELECT
m.employee_id,
m.name,
COUNT(e.reports_to) [reports_count],
ROUND(SUM(e.age) * 1.0 / COUNT(e.reports_to), 0) [average_age]
FROM (
SELECT
reports_to,
age
FROM Employees
) e JOIN (
SELECT
employee_id,
name
FROM Employees
) m ON e.reports_to = m.employee_id
GROUP BY
m.employee_id,
m.name
ORDER BY m.employee_id
通过手动计算平均值(年龄总和除以计数),将舍入到最近的整数可以更精确。此查询运行时为1122ms,在Leetcode上击败了93.38%的其他提交。
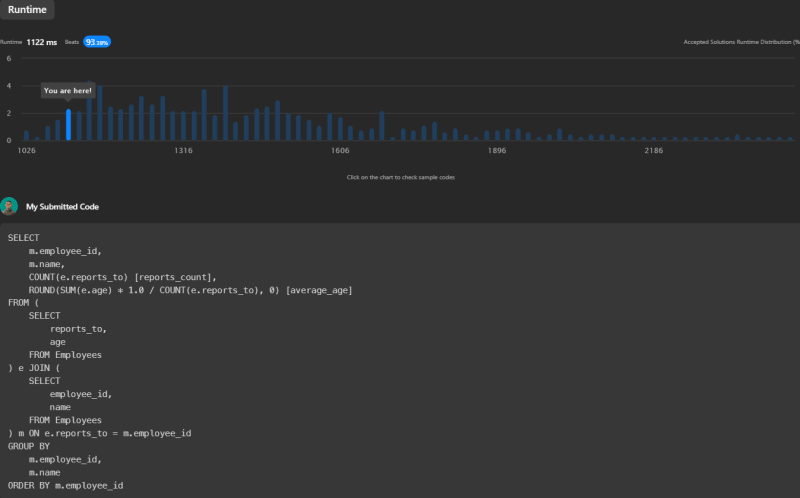
源代码4:加入,组和计算平均
此代码类似于源代码3,但它不使用子查询,恢复到更直接的加入操作。
SELECT
m.employee_id,
m.name,
COUNT(e.reports_to) [reports_count],
ROUND(SUM(e.age) * 1.0 / COUNT(e.reports_to), 0) [average_age]
FROM Employees e JOIN Employees m ON e.reports_to = m.employee_id
GROUP BY
m.employee_id,
m.name
ORDER BY m.employee_id
此解决方案结合了来自源代码1的直接加入方法和来自源代码3的显式平均计算。此查询运行时为1207ms,超过了LeetCode上其他提交的79.18%。

结论
从这些解决方案中,我们了解到SQL构建体的选择和表达计算的方式可以显着影响性能。有趣的是,使用子征服并不总是会带来更好的性能,这强调SQL优化可能是一个复杂的主题。表现最佳的解决方案是源代码3,其次是源代码4,源代码2,然后是源代码1。但是,重要的是要注意,leetcode的性能并不能完全代表现实世界数据库的性能,因为许多其他因素都来了发挥作用,包括索引,数据库设计和数据分发。
您可以在LeetCode上找到原始问题。
有关更有见地的解决方案和与技术相关的内容,请随时在Beacons page上与我联系。