问题
考虑具有以下模式的表Followers:
| 列名 | 类型 |
|---|---|
| 用户_id | int |
| follower_id | int |
(user_id, follower_id)是该表的主要键。该表包含一个社交媒体应用程序中的用户和追随者的ID,在该应用程序关注用户的情况下。任务是编写一个SQL查询,该查询将为每个用户返回关注者的数量。结果表应由user_id按升序订购。
解释
考虑以下Followers表:
| user_id | follower_id |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
对于此输入,预期的输出为:
| user_id | 关注者_count |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
在这里,每一行都代表一个不同的user_id,并且每个用户的追随者计数。
解决方案
我们将讨论解决这个问题的两种不同的方法,突出它们的优势和劣势,并解释其潜在的结构。
使用组
这种方法直接使用group by Crause的组直接计算每个user_id的follower_id。
SELECT
user_id,
COUNT(follower_id) [followers_count]
FROM Followers
GROUP BY user_id
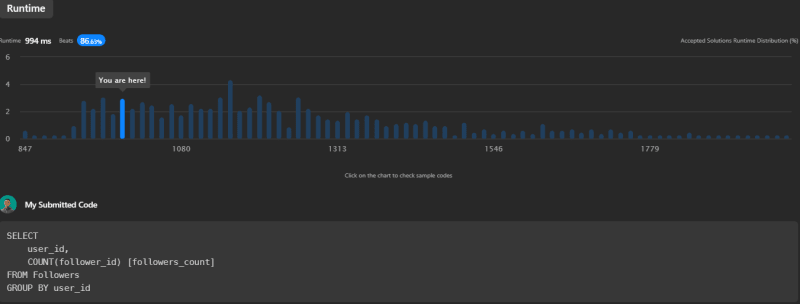
此查询相当简单且易于理解。它通过按user_id对数据进行分组,然后计算每个组中的关注者。这种方法的优点在于它的简单性和直接性。但是,在大型数据集中,按子句的组可能会很慢。此查询运行时为994ms,超过了Leetcode上其他提交的86.63%。
使用count()与分区
这种方法使用窗口函数计算每个user_id的follower_id。
SELECT DISTINCT
user_id,
COUNT(follower_id) OVER(PARTITION BY user_id) [followers_count]
FROM Followers
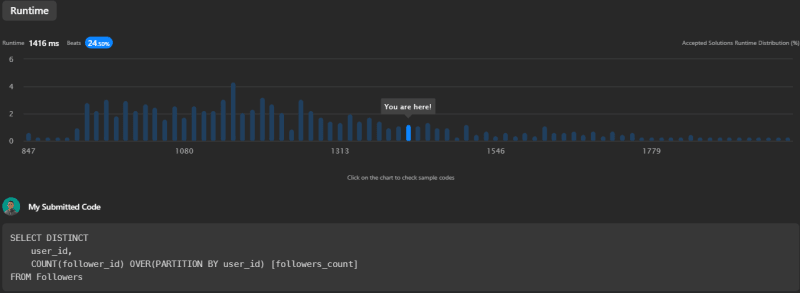
此查询虽然与第一个相似,但它利用窗口功能的功率实现相同的结果。子句的分区基本上创建了一个具有相同user_id的行的“窗口”,然后在此窗口上运行计数函数。这种方法有时可以通过方法对小组的性能进行改进,尤其是在处理较大的数据集时。但是,在这种情况下,性能略低,运行时间为1416ms,比Leetcode上的其他提交的24.50%。
结论
这两种方法都解决了问题,但是它们的性能会根据数据集的大小和分布而有所不同。虽然第一个使用Group By子句的解决方案在LeetCode上表现更好,但在具有较大数据集和良好调整数据库的真实情况下,使用窗口函数的第二种方法可能会更好。此示例有助于说明理解不同方法以及何时有利的重要性。 leetcode和现实世界应用程序的性能可能并不完美,但是使用各种技术练习有助于我们更好地为不同的方案做准备。
您可以在LeetCode中找到原始问题。
有关更有见地的解决方案和与技术相关的内容,请随时在Beacons page上与我联系。