近年来,很明显,没有实时数据,几乎没有生产系统是完整的。这也可以通过流媒体平台(例如Apache Kafka,Apache Pulsar,Redpanda和RabbitMQ)的兴起来观察。
本教程专注于处理实时电影评分通过 redpanda (一个兼容Kafka兼容的事件流平台)。数据可用于借助 memgraph 和Cypher查询语言来生成电影建议。
先决条件
要遵循本教程,您将需要:
- Docker 和 Docker Compose (包括在Windows和Macos的Docker桌面中)
- Memgraph Lab - 一个可以可视化图形并执行Memgraph中的Cypher查询的应用程序。
- data-streams 存储库的克隆。该项目包含数据流,Redpanda设置和MEMGRAPH。
数据模型
在此示例中,我们将使用通过Redpanda流的减少的MovieLens数据集。
每个JSON消息的结构都将如下:
{
"userId": "112",
"movie": {
"movieId": "4993",
"title": "Lord of the Rings: The Fellowship of the Ring, The (2001)",
"genres": ["Adventure", "Fantasy"]
},
"rating": "5",
"timestamp": "1442535783"
}
那么,我们将如何将此数据存储为图表?
有三种不同类型的节点:Movie,User和Genre。
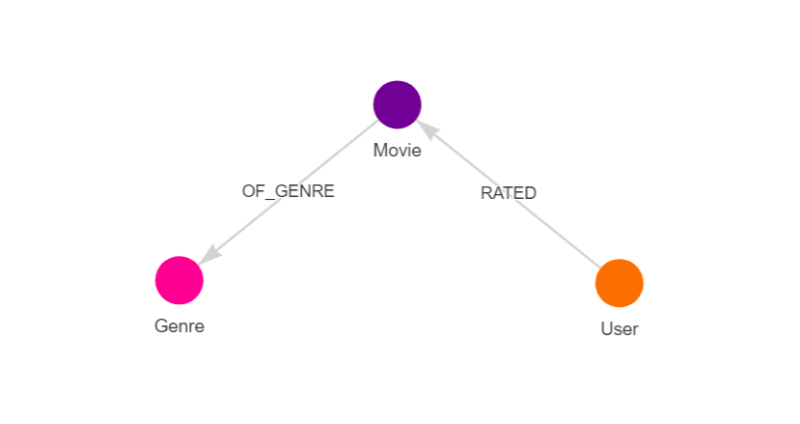
每部电影都可以用OF_GENRE边缘连接到其他类型。用户可以
评分电影,这些评分将以Edge RATED进行建模。此边缘包含属性rating的属性,该属性范围从1.0到5.0,timestamp。
每个Movie具有属性id和title,而每个User都有属性id。 Genre仅包含属性name。

1.开始Redpanda流
我们创建了一个Redpanda主题,您可以为本教程的目的连接到该主题。克隆 data-streams 存储库:
git clone https://github.com/memgraph/data-streams.git
将自己定位在data-streams目录中并运行以下命令
启动Redpanda流:
python start.py --platforms redpanda --dataset movielens
容器启动后,您应该看到在控制台中消耗的消息。
2.启动MEMGRAPH
通常,您将使用Docker独立启动Memgraph,但是这次我们将使用data-streams项目。鉴于我们需要访问在单独的Docker容器中运行的数据流,因此我们需要在同一网络上运行MEMGRAPH。
1。打开一个新终端,并将自己放在您之前克隆的data-streams目录中。
2。用:
构建备忘录图像
docker-compose build memgraph-mage
3。启动容器:
docker-compose up memgraph-mage
Memgraph应该启动并运行。您可以通过打开 memgraph Lab 并连接到空数据库来确保。
3.创建转换模块
在我们可以连接到数据流之前,我们需要告诉MEMGRAPH如何转换传入消息,以便可以正确消耗它们。这将通过一个简单的Python转换模块完成:
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
parameters={
"userId": movie_dict["userId"],
"movieId": movie_dict["movie"]["movieId"],
"title": movie_dict["movie"]["title"],
"genres": movie_dict["movie"]["genres"],
"rating": movie_dict["rating"],
"timestamp": movie_dict["timestamp"]}))
return result_queries
每次收到JSON消息时,我们都需要执行一个绘制到图形对象的电码查询:
MERGE (u:User {id: $userId})
MERGE (m:Movie {id: $movieId, title: $title})
WITH u, m
UNWIND $genres as genre
MERGE (m)-[:OF_GENRE]->(:Genre {name: genre})
CREATE (u)-[:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)
如果数据库中缺少这些密码查询,则会创建User和Movie。电影也与他们所属的流派有关。最后,用户和电影之间创建了类型RATED的边缘,表明评分为等级。
现在我们创建了转换模块,另一个问题出现了。如何将转换模块加载到memgraph中?
1。首先,找到备忘录正在运行的容器(CONTAINER_ID)的ID:
docker ps
注意memgraph-mage容器的ID。
2。
docker cp movielens.py CONTAINER_ID:/usr/lib/memgraph/query_modules/movielens.py
3。
4。用以下Cypher查询加载模块
如果您没有收到错误,则成功加载了该模块。 1。在 memgraph Lab 中执行以下查询,以创建流: 2。
3。
就是这样!您只需使用MEMGRAPH连接到实时数据源,并可以开始探索数据集。如果您在Memgraph Lab中打开概述选项卡,则应该看到已经创建了许多节点和边缘。 可以肯定的是,打开选项卡图形架构,然后单击生成按钮,查看图表是否遵循我们在文章开头定义的数据模型 。 对于数据分析,我们将使用 cypher ,这是图形数据库中最受欢迎的查询语言。它提供了一种与属性图一起工作的直观方式。即使您不熟悉它,如果您对SQL有所了解,以下查询也不难理解。 1。让我们从数据库中返回10部电影: 2。找到类型的电影冒险和幻想: 3。计算电影矩阵的平均评分得分: 4。是时候进行更严肃的查询了。让我们为特定用户找到一个建议,例如,使用ID 就是这样,您已经根据每个用户之间评分的相似性生成了建议。如果您想了解有关此查询的更多信息,请肯定地查看our tutorial,我们可以在其中进行详细介绍。 分析来自流平台的实时数据从未如此简单。正如我们通过使用Redpanda和Memgraph所证明的那样,这也适用于图形分析。如果您有任何疑问或评论,请查看我们的Discord server。 规则很简单,您只需要创建一些丰富图形世界的东西CALL mg.load("movielens");
4.连接到Memgraph的Redpanda流
CREATE KAFKA STREAM movielens_stream
TOPICS ratings
TRANSFORM movielens.rating
BOOTSTRAP_SERVERS "redpanda:29092";
START STREAM movielens_stream;
SHOW STREAMS;
5.分析流数据
MATCH (movie:Movie)
RETURN movie.title
LIMIT 10;

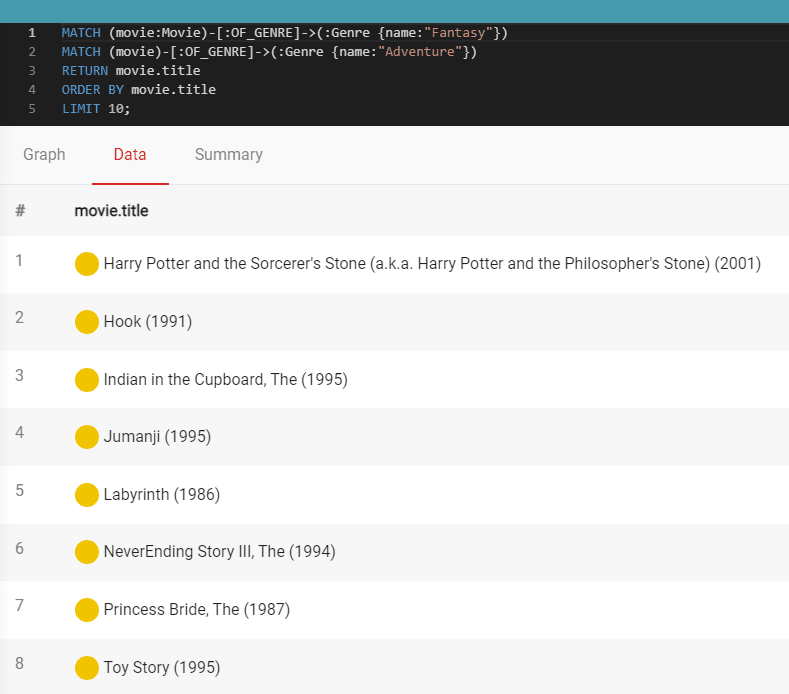
MATCH (movie:Movie)-[:OF_GENRE]->(:Genre {name:"Fantasy"})
MATCH (movie)-[:OF_GENRE]->(:Genre {name:"Adventure"})
RETURN movie.title
ORDER BY movie.title
LIMIT 10;
MATCH (:User)-[r:RATED]->(m:Movie)
WHERE m.title = "Matrix, The (1999)"
RETURN avg(r.rating)

6:
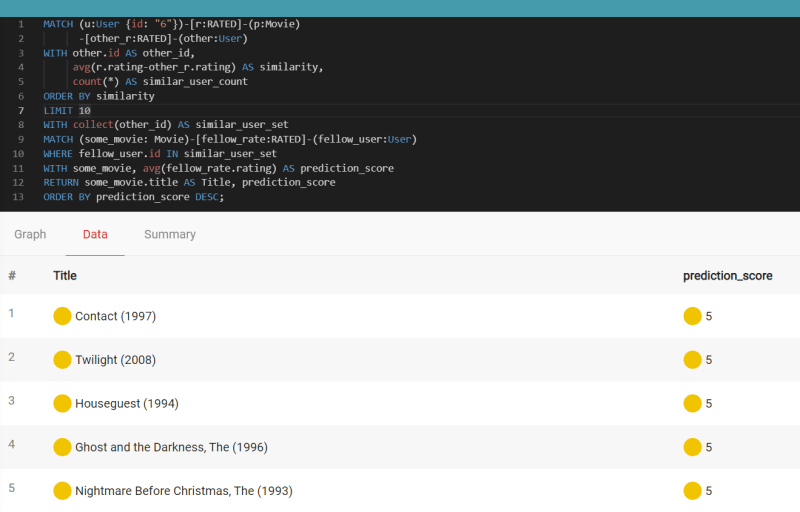
MATCH (u:User {id: "6"})-[r:RATED]-(p:Movie)
-[other_r:RATED]-(other:User)
WITH other.id AS other_id,
avg(r.rating-other_r.rating) AS similarity,
ORDER BY similarity
LIMIT 10
WITH collect(other_id) AS similar_user_set
MATCH (some_movie: Movie)-[fellow_rate:RATED]-(fellow_user:User)
WHERE fellow_user.id IN similar_user_set
WITH some_movie, avg(fellow_rate.rating) AS prediction_score
RETURN some_movie.title AS Title, prediction_score
ORDER BY prediction_score DESC;
结论
祝您编码好运,不要忘记register for the Challenge!