最近,向量嵌入和矢量数据库变得越来越流行,从而可以开发新的智能应用程序,例如向量相似性搜索。由于我没有这些概念的经验,因此我决定探索它们并为您记录我的旅程。
在本文中,您将探讨由佛罗伦萨基金会模型提供动力的Azure Computer Vision 4.0的图像检索功能。您将:
- 探索向量嵌入和向量相似性搜索的概念。
- 了解Azure计算机视觉工作的图像检索如何工作。
- 使用Python中的图像检索API搜索图像集合,以查找与给定查询图像或文本提示最相似的图像。
- 使用Azure Cosmos DB进行PostgreSQL存储和查询向量数据。
开始构建图像向量相似性系统之前,请按照以下步骤:
-
注册Azure free account或Azure for Students account。如果您已经有活动订阅,则可以使用它。
-
在Azure Portal中创建认知服务资源。
图像检索API可在以下地区提供:美国东部,法国中部,韩国中部,北欧,东南亚,西欧,西欧,西美国。要在Vision Studio中运行图像检索演示,您的资源必须属于 East US 区域。
-
安装Python 3.x,Visual Studio代码,Jupyter笔记本和Visual Studio代码的Jupyter扩展名。
您想立即开始编码吗?源代码,图像文件及其矢量嵌入都可以在我的GitHub repository上找到。
什么是矢量嵌入?
让我们从了解向量嵌入开始。简而言之,矢量嵌入是数据的数值表示,例如图像,文本,视频和音频。这些向量是高维密度向量,每个维度都包含有关原始内容的信息。通过将数据转换为密集的向量,我们可以使用它们执行诸如聚类,建议或图像搜索之类的任务。此外,这些密集表示使计算机可以理解两个对象之间的语义相似性。也就是说,如果我们将图像,视频,文档或音频之类的对象表示为矢量嵌入,我们可以通过其在向量空间中的距离来量化它们的语义相似性。例如,猫的图像的嵌入向量将与另一只猫的嵌入向量或“ Meow”一词更相似,而不是狗的图片或“ woof”一词。

产生密集的向量
有很多方法可以生成数据的向量嵌入数据。为了将数据矢量化,您可以使用Azure OpenAI嵌入式模型进行文本文档或用于图像和文本的视觉图像检索API的Azure认知服务。后者是一种多模式嵌入模型,使您能够向量化图像和文本数据并构建图像搜索系统。
如果您有兴趣了解有关向量嵌入的更多信息以及如何创建它们,请在MLOPS社区网站上查看"Vector Similarity Search: From Basic to Production"帖子!
!什么是矢量相似性搜索?
向量嵌入捕获对象的语义相似性,从而允许开发语义相似性搜索系统。矢量相似性搜索是通过基于图像本身的内容搜索图像来工作的,而不仅仅是像基于关键字的搜索系统一样依靠手动分配的关键字,标签或其他元数据。这种方法通常比传统搜索技术更有效,更准确,这在很大程度上取决于用户找到最佳搜索词的能力。
在向量搜索系统中,将用户查询的向量嵌入与一组预存储的向量嵌入式相提并论,以查找与查询向量最相似的向量列表。由于在数字上关闭的嵌入在语义上也很相似,因此我们可以使用距离度量(例如余弦或欧几里得距离)来测量语义相似性。
在这篇文章中,我们将利用余弦相似性度量来衡量两个向量之间的相似性。该度量等于两个向量之间的角度的余弦,或者等效地,向量的点产物除以其幅度的产物。余弦相似性范围为-1至1,值接近1的值表明向量非常相似。为了说明这一点,这是一个python函数,可以计算两个向量之间的余弦相似性。
def get_cosine_similarity(vector1, vector2):
"""
Get the cosine similarity between two vectors
"""
dot_product = 0
length = min(len(vector1), len(vector2))
for i in range(length):
dot_product += vector1[i] * vector2[i]
magnitude1 = math.sqrt(sum(x * x for x in vector1))
magnitude2 = math.sqrt(sum(x * x for x in vector2))
return dot_product / (magnitude1 * magnitude2)
使用Azure计算机视觉进行图像检索
Azure Computer Vision 4.0的图像检索API,由佛罗伦萨基金会模型提供动力,允许图像和文本查询的矢量化。此矢量化将图像和文本转换为1024维矢量空间中的坐标,使用户能够使用文本和/或图像搜索图像集合而无需元数据,例如图像标签,标签或字幕。
。Azure计算机视觉提供了两个图像检索API用于矢量化图像和文本查询:矢量化图像API和矢量化文本API。下图显示了使用这些API的典型图像检索过程。
")
图像检索
导航到我的GitHub repository并下载本文的源代码。在Visual Studio代码中打开image-embedding.ipynb Jupyter笔记本并探索代码。
使用矢量化image API,此代码生成了200张图像的向量嵌入,并将它们导出到JSON文件中。之后,突出显示了两个图像向量相似性搜索过程:图像到图像搜索和文本对图像搜索。
-
在图像到图像搜索过程中,参考图像使用矢量化图像API转换为嵌入向量,并使用余弦距离来测量查询矢量与我们的矢量嵌入之间的相似性图像收集。在参考图像的旁边检索并显示了顶部匹配的图像。
-
在文本到图像搜索过程中,文本查询使用矢量化文本API转换为嵌入向量,并且根据查询向量及其它们的余弦相似性检索和显示最相似的图像向量。
此示例的灵感来自Serge Retkowsky的Azure Computer Vision in a day workshop。
什么是矢量数据库?
向量数据库是一种专门的数据库,旨在将数据作为高维向量或嵌入式处理。向量数据库与传统数据库不同,因为它们可以优化以存储和查询数量大量维数的存储和查询向量,这些尺寸的范围可能从数十到数千,具体取决于数据的复杂性和应用的转换函数。下图说明了基本矢量搜索系统的工作流程。
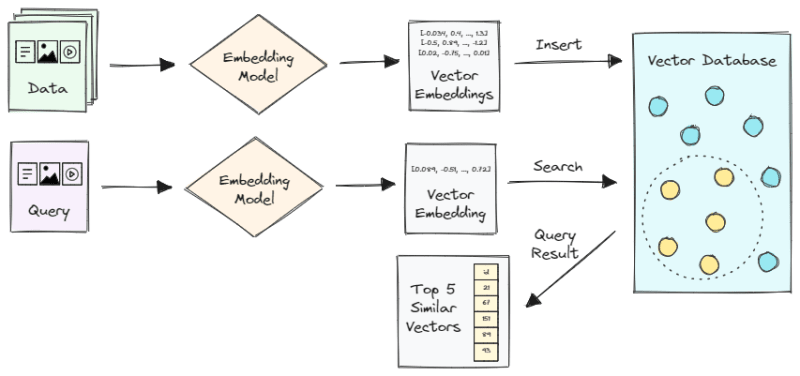
让我们进一步分析。
- 首先,我们使用嵌入模型来生成原始数据的向量嵌入,例如文本,图像,视频或音频。
- 这些向量存储在向量数据库中,并引用了原始数据和/或其他元数据(可选)。
- 当应用程序发出查询时,我们使用相同的嵌入模型来生成查询的嵌入。此查询可以与我们的数据集相同的数据类型(例如,搜索相似图像的图像)或其他数据类型(例如,要搜索相似图像的文本)。
- 然后,我们使用查询向量搜索数据库中的类似向量嵌入。要确定任何两个向量之间的相似性,我们必须使用相似性度量(例如余弦相似性)来计算高维矢量空间中它们之间的距离。
- 相似性搜索将输出与查询向量最相似的向量列表。然后可以访问与每个向量关联的原始数据。
截至2023年7月3日,可用于存储和查询向量数据。
- Azure PostgreSQL Database和Azure Cosmos DB for PostgreSQL
- Azure Cosmos DB for MongoDB vCore
- Azure Cache for Redis Enterprise
- Azure Data Explorer
- Azure Cognitive Search – Vector Search (private preview)
使用Azure Cosmos DB搜索postgresql
在这篇文章中,我想尝试使用azure cosmos db作为postgresql,其中pgvector扩展程序启用了向量相似性搜索。在下面的部分中,我将向您展示如何启用扩展名,创建一个以存储向量数据并查询向量的表。
让我们开始!
为PostgreSQL群集创建一个Azure Cosmos DB
- 登录Azure portal并选择+创建资源。
- 搜索 Azure Cosmos DB 。在 Azure Cosmos DB 屏幕上,选择 Create 。
- 在上哪个API最适合您的工作负载?屏幕,选择 create 在 azure cosmos db上用于PostgreSql tile。
-
在上为PostgreSQL群集创建一个Azure Cosmos DB 表格填写以下值:
- 订阅:选择您的订阅。
- 资源组:选择现有资源组或创建一个新的资源组。
- 群集名称:为PostgreSQL群集输入Azure Cosmos DB的名称。
- 位置:选择一个可用区域之一。
- 比例:您可以将比例作为其默认值或选择最佳节点数量以及计算,内存和存储配置。
- PostgreSQL版本:选择一个PostgreSQL版本,例如 15 。
-
数据库名称:您可以在其默认值
citus中留下数据库名称。 -
管理员帐户:管理用户名必须为
citus。选择将用于citus角色连接到数据库的密码。

-
在网络选项卡上,选择允许Azure服务和资源中的公共访问该集群并创建您首选的防火墙规则。

-
导航到评论 +创建选项卡,然后选择创建创建群集。
-
部署完成后,选择转到资源。
-
保存协调员名称,数据库名称和 admin username 在概述您的群集,因为您需要在后续步骤中。
启用PGVECTOR扩展
pgvector扩展名将矢量相似性搜索功能添加到您的PostgreSQL数据库中。要使用扩展程序,您必须首先在数据库中创建它。要启用扩展名,我们将使用psql shell。
- 在您的Azure资源的左窗格上选择快速启动选项卡,然后选择 postgresql shell tile。
- 输入密码以连接到数据库。
-
可以使用以下命令启用
pgvector扩展名:
SELECT CREATE_EXTENSION('vector');
创建一个存储向量数据的表
在psql shell上,运行以下命令以创建一个表格存储向量数据。
CREATE TABLE imagevectors(
file TEXT PRIMARY KEY,
embedding VECTOR(1024)
);
该表有两列:一个用于类型TEXT的图像文件路径,一个用于类型VECTOR(1024)的相应向量嵌入。
创建Python应用程序
创建一个新的.ipynb文件,然后在Visual Studio代码中打开它。创建一个.env文件并保存以下变量:
| 可变名称 | 可变值 |
|---|---|
| CV_KEY | Azure认知服务密钥 |
| cv_endpoint | Azure认知服务终点 |
| Postgres_host | PostgreSQL群集协调员名称 |
| Postgres_db_name | PostgreSQL群集数据库名称 |
| Postgres_user | PostgreSQL群集管理用户名 |
| Postgres_password | PostgreSQL群集管理员密码 |
源代码,图像文件及其矢量嵌入都可以在我的GitHub repository上找到。
-
从
azurecv.py文件中导入以下库和3个函数。
import os import glob import json import psycopg2 from psycopg2 import pool from dotenv import load_dotenv import pandas as pd import csv from io import StringIO import math from azurecv import text_embedding, image_embedding, display_image_grid -
插入一个新的代码单元格并添加以下代码,该代码将加载图像文件路径和上一节中生成的向量嵌入。
# images images_folder = "images" image_files = glob.glob(images_folder + "/*") # embeddings output_folder = "output" emb_json = os.path.join(output_folder, "embeddings.json") with open(emb_json) as f: image_embeddings = json.load(f) print(f"Total number of images: {len(image_files)}") print(f"Number of imported vector embeddings: {len(image_embeddings)}") -
在新的代码单元格中,创建一个带有两个列的熊猫数据框:一个用于图像文件路径,一个用于相应的向量嵌入(转换为字符串表示)。
df_files = pd.DataFrame(image_files, columns=['file']) df_embeddings = pd.DataFrame([str(emb) for emb in image_embeddings], columns=['embedding']) df = pd.concat([df_files, df_embeddings], axis=1) df.head(5) -
然后,您将连接到PostgreSQL群集的Azure Cosmos DB。以下代码使用环境变量为您的Azure Cosmos DB构成一个连接字符串,用于PostgreSQL群集,并为Postgres数据库创建一个连接池。之后,创建了一个
cursor对象,可用于使用execute()方法执行SQL查询。
# Load environment variables load_dotenv() host = os.getenv("POSTGRES_HOST") dbname = os.getenv("POSTGRES_DB_NAME") user = os.getenv("POSTGRES_USER") password = os.getenv("POSTGRES_PASSWORD") sslmode = "require" table_name = "imagevectors" # Build a connection string from the variables conn_string = "host={0} user={1} dbname={2} password={3} sslmode={4}".format(host, user, dbname, password, sslmode) postgreSQL_pool = psycopg2.pool.SimpleConnectionPool(1, 20, conn_string) if (postgreSQL_pool): print("Connection pool created successfully") # Get a connection from the connection pool conn = postgreSQL_pool.getconn() cursor = conn.cursor() -
让我们在表中添加一些数据。将数据插入postgresql表中可以通过多种方式完成。我选择不使用
pandas.DataFrame.to_sql()方法将数据插入我们的PostgreSQL表中,因为它相对较慢。相反,我使用COPY FROM STDIN命令添加数据。此方法的灵感来自Ellis Michael Valentiner的A Fast Method to Bulk Insert a Pandas DataFrame into Postgres。
以下代码创建了一个与
imagevectors表相同的列的临时表,并且将数据框中的数据复制到其中。然后考虑到由于重复的键可能引起的任何潜在冲突(如果代码多次运行,可能会发生这种冲突)。sio = StringIO() writer = csv.writer(sio) writer.writerows(df.values) sio.seek(0) cursor.execute("CREATE TEMPORARY TABLE tmp (file TEXT PRIMARY KEY, embedding VECTOR(1024)) ON COMMIT DROP;") cursor.copy_expert("COPY tmp FROM STDIN CSV", sio) cursor.execute(f"""INSERT INTO {table_name} (file, embedding) SELECT * FROM tmp ON conflict (file) DO NOTHING;""") conn.commit() -
要查看插入表中的前10行,请运行以下代码:
# Fetch all rows from table cursor.execute(f"SELECT * FROM {table_name} limit 10;") rows = cursor.fetchall() # Print all rows for row in rows: print(f"Data row = ({row[0]}, {row[1]})") -
使用向量数据填充表后,您可以使用此图像集合来搜索与参考图像或文本提示最相似的图像。工作流程总结如下:
- 使用矢量化图像API或矢量化文本API分别生成图像或文本的向量嵌入。
- 要计算相似性并检索图像,请使用
SELECT语句和PostgreSQL数据库的内置向量运算符。 - 使用
display_image_grid()函数显示检索到的图像。

-
让我们了解简单的
SELECT语句的工作方式。考虑以下查询:
SELECT * FROM imagevectors ORDER BY embedding <=> '[0.003, …, 0.034]' LIMIT 5此查询计算给定向量(
[0.003, …, 0.034])和存储在imagevectors表中的向量之间的余弦距离(<=>),按计算的距离对结果进行分类,并返回五个最相似的图像(LIMIT 5)。PostgreSQL
pgvector扩展名提供了3个可用于计算相似性的操作员:操作员 描述 <->欧几里得距离 <#>负面的内部产品 <=>余弦距离 -
可以在下面找到文本对图像搜索过程的示例。有关图像到图像搜索的示例,请参阅我的GitHub存储库中的Jupyter Notebook。
# Generate the embedding of the text prompt txt = "a seahorse" txt_emb = text_embedding(txt, endpoint, key) # Vector search topn = 9 cursor.execute(f"SELECT * FROM {table_name} ORDER BY embedding <=> %s LIMIT {topn}", (str(txt_emb),)) # Display the results rows = cursor.fetchall() for row in rows: print(row) # Display the similar images images = [row[0] for row in rows] captions = [f"Top {i+1}: {os.path.basename(images[i])}" for i in range(len(images))] ncols = 3 nrows = math.ceil(len(images)/ncols) display_image_grid(images, captions, 'Search results for: "' + txt + '"', nrows, ncols)
摘要和下一步
在这篇文章中,我们探索了嵌入式,矢量搜索和vector数据库的概念,并使用Azure Computer Vision Image创建了一个简单的图像向量相似性搜索系统用于PostgreSQL的检索API和Azure Cosmos DB。如果您想深入研究此主题,这里有一些有用的资源。
- Azure Computer Vision Image Retrieval – Microsoft Docs
- How to use pgvector on Azure Cosmos DB for PostgreSQL – Microsoft Docs
您还可以查看我以前有关Azure Computer Vision 4.0(佛罗伦萨模型)的博客文章:
- Explore Azure Computer Vision 4.0 (Florence model)
- Extract text from images with Azure Computer Vision 4.0 Read OCR
ð嗨,我是foteini savvidou!
来自希腊的电气和计算机工程专业的学生以及Microsoft AI MVP(最有价值的专业人士)。