这是一系列文章的第四部分,名称为“ play Microservices” 。链接到其他部分:
第1部分:Play Microservices: Bird's eye view
第2部分:Play Microservices: Authentication
第3部分:Play Microservices: Scheduler
第4部分:您在这里
可以找到该项目的源代码here:
内容:
- 摘要
- 工具
- docker dev环境
- kafka元数据服务:Zookeeper
- zoonavigator服务
- 消息经纪服务:kafka
- kafka-UI服务
- SMTP服务:可选
- MailJob服务:Python
- 做
- 摘要
在第三部分中,我们开发了调度程序服务。现在,我们的目标是创建一个电子邮件作业执行者服务,该服务消耗了调度程序服务产生的主题 - 工作事件,并在运行工作后,将主题 - 乔布·纳尔(Togub-Job-Job-run-Result)生成消息代理。为了实现这一目标,我们需要四个不同的服务:消息经纪服务,用于支持消息经纪的元数据数据库服务,SMTP服务器服务和电子邮件服务本身。此外,在开发环境中,我们提供了两项专门用于调试目的的额外服务。这些服务由Kafkaui组成,用于管理我们的Kafka服务,Zookeeper服务的Zoonavigator。请记住,假设我们的微服务体系结构中的每种服务都有自己的存储库和开发团队,并且在开发环境中,他们完全独立(从逻辑上讲),我们正在遵循每个团队模式的服务。前四个部分是上一步的副本。您可以跳过它们并进行 SMTP服务
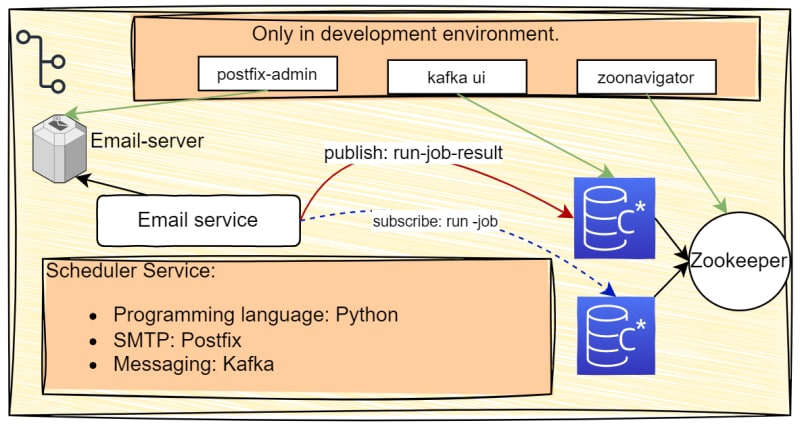
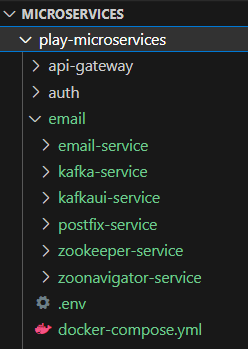
最后,项目目录结构将显示如下:
- 工具
主机机器中所需的工具:
- Docker:容器化工具
- VSCode:代码编辑工具
- vscode的Dev containsers扩展
- vscode的Docker扩展
- Git
我们将在每种服务内部使用内部容器中使用的工具和技术:
- 消息传递服务:Kafka
- Kafka-ui service: Kafka-ui
- 元数据服务:Zookeeper
- zoonavigator服务:Zoonavigator
- SMTP服务:Postfix
- 电子邮件服务:
- Python : programming language
- Kafka-python:对于GO的消息经纪传播。
- docker dev环境
Docker容器内部的开发可以提供多种好处,例如一致的环境,孤立的依赖关系和改进的协作。通过使用Docker,开发工作流可以与团队成员进行集装和共享,从而可以在不同的机器和平台之间进行一致的部署。开发人员可以轻松地在不同版本的依赖项和库之间切换,而不必担心冲突。

在Docker容器内开发时,您只需要在VS代码上安装Docker,Visual Studio Code和Dev Containers和Dockerextensions。然后,您可以使用Docker运行一个容器,并将主机文件夹映射到容器内部的文件夹,然后将VSCODE连接到运行的容器并开始编码,所有更改将反映在主机文件夹中。如果删除图像和容器,则可以通过使用Dockerfile重新创建容器并将内容从主机文件夹复制到容器文件夹来轻松重新开始。但是,重要的是要注意,在这种情况下,需要再次下载容器内部所需的任何工具。在引擎盖下,将VSCODE连接到运行的容器时,Visual Studio代码安装并在容器内运行特殊服务器,该服务器处理容器和主机机器之间更改的同步。
- 元数据服务:Zookeeper
ZooKeeper 是用于维护配置信息的集中式服务。我们将其用作kafka消息服务的元数据存储。
- 在根目录内部创建一个名称Zookeeper-Service
的文件夹- 创建一个dockerfile并将内容设置为
FROM bitnami/zookeeper:3.8.1- 创建一个名为.env的文件,并将内容设置为
ZOO_SERVER_USERS=admin,user1
# for development environment only
ALLOW_ANONYMOUS_LOGIN="yes"
# if yes, uses SASL
ZOO_ENABLE_AUTH="no"
- 创建一个名为server_passwords.properties的文件,并将内容设置为
password123,password_for_user1,请选择自己的密码。- 将以下内容添加到docker-compose的.env文件(项目根目录处的.env文件)。
ZOOKEEPER_PORT=2181
ZOOKEEPER_ADMIN_CONTAINER_PORT=8078
ZOOKEEPER_ADMIN_PORT=8078
- 将以下内容添加到docker-compose.yml的服务部分。
e-zk1:
build:
context: ./zookeeper-service
dockerfile: Dockerfile
container_name: e-zk1-service
secrets:
- zoo-server-pass
env_file:
- ./zookeeper-service/.env
environment:
ZOO_SERVER_ID: 1
ZOO_SERVERS: e-zk1-service:${ZOOKEEPER_PORT}:${ZOOKEEPER_PORT}
ZOO_SERVER_PASSWORDS_FILE: /run/secrets/zoo-server-pass
ZOO_ENABLE_ADMIN_SERVER: yes
ZOO_ADMIN_SERVER_PORT_NUMBER: ${ZOOKEEPER_ADMIN_CONTAINER_PORT}
ports:
- '${ZOOKEEPER_PORT}:${ZOOKEEPER_PORT}'
- '${ZOOKEEPER_ADMIN_PORT}:${ZOOKEEPER_ADMIN_CONTAINER_PORT}'
volumes:
- "e-zookeeper_data:/bitnami"
volumes:
e-zookeeper_data:
driver: local
- 将以下内容添加到docker-compose.yml的秘密部分。
zoo-server-pass:
file: zookeeper-service/server_passwords.properties
-zookeeper是一个分布式应用程序,允许我们同时运行多个服务器。它使多个客户可以连接到这些服务器,从而促进它们之间的通信。 Zookeeper服务器协作处理数据并以协调的方式响应请求。在这种情况下,我们的Zookeeper消费者(客户端)是KAFKA服务器,这再次是一个分布式事件流平台。我们可以作为Zookeeper服务器的集合运行多个动物园服务,并通过
ZOO_SERVERS环境变量将它们连接在一起。
- Bitnami Zookeeper docker Image提供了一个ZOO_CLIENT入口点,它充当内部客户端,并允许我们运行Zkcli.sh命令行工具,以与Zookeeper服务器作为客户端进行交互。但是我们将使用GUI客户端进行调试目的:zoonavigator。
- zoonavigator服务
此服务仅存在于开发环境中用于调试目的。我们使用它连接到Zookeeper-Service并管理数据。
- 在根目录内部创建一个名称zoonavigator-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM elkozmon/zoonavigator:1.1.2- 将
ZOO_NAVIGATOR_PORT=9000添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
e-zoo-navigator:
build:
context: ./zoonavigator-service
dockerfile: Dockerfile
container_name: e-zoo-navigator-service
ports:
- '${ZOO_NAVIGATOR_PORT}:${ZOO_NAVIGATOR_PORT}'
environment:
- CONNECTION_LOCALZK_NAME = Local-zookeeper
- CONNECTION_LOCALZK_CONN = localhost:${ZOOKEEPER_PORT}
- AUTO_CONNECT_CONNECTION_ID = LOCALZK
depends_on:
- e-zk1
- 现在从终端运行
docker-compose up -d --build- 跑步时,请转到
http://localhost:9000/。您将看到以下屏幕:
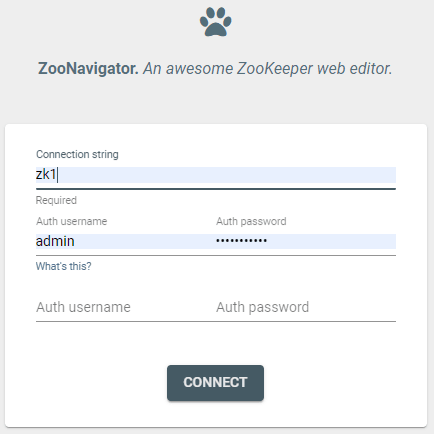
- 输入Zookeeper服务的容器名称(此处E-ZK1)。如果一切都按计划进行,您应该能够建立与Zookeeper服务的连接。

- 没有跑步码头组合。我们稍后将返回这些工具。
- 消息经纪服务:kafka
Apache Kafka是一个开源分布式事件流平台,非常适合微服务体系结构。它是实现事件采购等模式的理想选择。在这里,我们将其用作调度程序服务的消息经纪。
- 在根目录内部创建一个名称kafka-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM bitnami/kafka:3.4.1- 在Docker文件旁边创建一个.env文件,并将内容设置为:
ALLOW_PLAINTEXT_LISTENER=yes
KAFKA_ENABLE_KRAFT=no
- 将
KAFKA1_PORT=9092添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
e-kafka1:
build:
context: ./kafka-service
dockerfile: Dockerfile
container_name: e-kafka1-service
ports:
- '${KAFKA1_PORT}:${KAFKA1_PORT}'
volumes:
- "e-kafka_data:/bitnami"
env_file:
- ./kafka-service/.env
environment:
KAFKA_BROKER_ID: 1
KAFKA_CFG_ZOOKEEPER_CONNECT: zk1:${ZOOKEEPER_PORT}
KAFKA_ZOOKEEPER_PROTOCOL: PLAINTEXT #if auth is enabled in zookeeper use one of: SASL, SASL_SSL see https://hub.docker.com/r/bitnami/kafka
KAFKA_CFG_LISTENERS: PLAINTEXT://:${KAFKA1_PORT}
depends_on:
- e-zk1
- 要连接我们的Kafka经纪人进行调试目的,我们运行了另一项服务。 kafka-ui。
- kafka-UI服务
此服务仅存在于开发环境中用于调试目的。我们使用它连接到Kafka服务并管理数据。
- 在根目录内部创建一个名称kafkaui-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM provectuslabs/kafka-ui:latest- 将
KAFKAUI_PORT=8080添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
e-kafka-ui:
build:
context: ./kafkaui-service
dockerfile: Dockerfile
container_name: e-kafka-ui-service
restart: always
ports:
- ${KAFKAUI_PORT}:${KAFKAUI_PORT}
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: e-kafka1:${KAFKA1_PORT}
DYNAMIC_CONFIG_ENABLED: 'true'
depends_on:
- e-kafka1
- 现在运行
docker-compose run -d --build。在运行容器时,请转到http://localhost:8080/打开Kafka-UI仪表板。
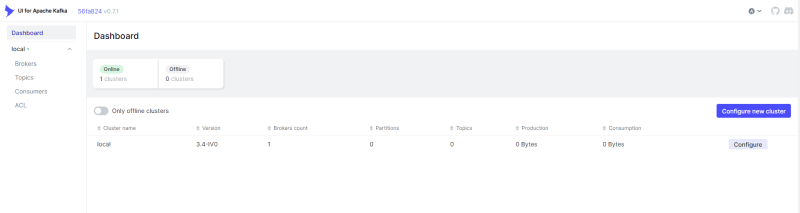
- 从界面中,您可以查看和管理经纪人,主题和消费者。我们将很快详细介绍这些元素。
- 运行
docker-compose down
- SMTP服务:可选
我们想通过Docker在本地计算机上运行简单的出站电子邮件服务。此步骤是可选的,首选使用亚马逊SES等第三方服务。
- 在根目录内部创建一个名称PostFix-Service
的文件夹- 创建一个dockerfile并将内容设置为
FROM FROM catatnight/postfix:latest- 将
POSTFIX_PORT=25添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
postfix:
build:
context: ./postfix-service
dockerfile: Dockerfile
container_name: postfix
restart: always
environment:
- EMAIL_DOMAIN=yourdomain.com
- SMTP_USER=username
- SMTP_PASSWORD=password
ports:
- ${POSTFIX_PORT}:${POSTFIX_PORT}
- 我们所需的服务已准备就绪并运行。现在是时候为我们的电子邮件工作执行者服务准备开发环境了。
- MailJob服务:Python
我们的目标是创建一项简单的Python服务,该服务消耗Kafka事件的主题topic-job-run(由我们的调度程序服务),执行工作(发送电子邮件),然后为topic topic-job-run-result生成事件。一块蛋糕!

- 创建一个名为
mailjob-service的文件夹。- 在
scheduler-service内部创建一个Dockerfile,并将内容设置为
FROM python:3.11.4
WORKDIR /usr/src/app
- 将以下内容添加到我们docker-compose.yml文件的服务部分。
mailjob-service:
build:
context: ./mailjob-service
dockerfile: Dockerfile
container_name: mailjob-service
command: sleep infinity
ports:
- ${EMAIL_SERVICE_PORT}:${EMAIL_SERVICE_PORT}
environment:
ENVIRONMENT: development
KAFKA_BROKERS: e-kafka1-service:${KAFKA1_PORT}
# TOPICS_FILE: ''
MAIL_SERVER_HOST: postfix
MAIL_SERVER_PORT: 25
EMAIL_DOMAIN: yourdomain.com
SMTP_USER: username
SMTP_PASSWORD: password
volumes:
- ./mailjob-service:/usr/src/app
depends_on:
- e-kafka1
- postfix
- 我们将在码头容器内部进行所有开发,而无需在主机机器中安装Python。为此,我们运行容器,然后将VSCODE连接到MailJob-Service容器。您可能会注意到,MailJob-Service的Dockerfile没有入口点,因此我们将MailJob-Service的命令值设置为
sleep infinity以保持容器醒着。- 现在运行
docker-compose up -d --build- 在运行时,通过单击左下图标,然后选择
attach to running container,将其连接到MailJob服务。选择MailJob-Service,然后等待VSCODE的新实例启动。一开始,Vscode要求我们打开容器内部的文件夹。我们在Dockerfile内选择了WORKDIR /usr/src/app,因此我们将在容器内打开此文件夹。此文件夹使用Docker组成的卷将其安装到主机机器内部的MailJob-Service文件夹,因此,我们所做的任何更改也将同步到主机文件夹。- 打开文件夹
/usr/src/app后,创建一个名为unignts.txt的文件,并将内容设置为:
kafka-python==2.0.2
python-dotenv==1.0.0
- 打开一个新终端并运行
pip install -r requirements.txt- 创建一个名为.env.Topics的文件,并将内容设置为:
TOPIC_JOB_RUN = "topic-job-run"
TOPIC_JOB_RUN_CONSUMER_GROUP_ID = "topic-job-run-consumer"
TOPIC_JOB_RUN_CONSUMER_WORKER_COUNT = 1
TOPIC_JOB_RUN_RESULT = "topic-job-run-result"
TOPIC_JOB_RUN_RESULT_CONSUMER_GROUP_ID = "job-run-result-consumer"
TOPIC_JOB_RUN_RESULT_CONSUMER_WORKER_COUNT = 1
- 创建一个名为config.py的文件,并设置来自here的内容。
- 创建一个名为应用程序的文件夹,然后为应用模块的名为__init__.py的文件。将内容设置为
from config import Config
def create_app():
config = Config()
- 在根目录中创建一个名为main.py的文件,然后将内容设置为
from app import create_app
import logging
def main():
create_app()
if __name__ == '__main__':
logging.basicConfig(
format='%(asctime)s.%(msecs)s:%(name)s:%(thread)d:' + '%(levelname)s:%(process)d:%(message)s',
level=logging.INFO
)
main()
- 在应用程序中创建一个名为fol的电子邮件,然后创建一个名为__init__.py的文件。创建另一个名为email_sender.py的文件,并设置here中的内容。该课程负责执行电子邮件作业。
- 我们的目标是消费使用以下结构的Kafka消息。
{
"jobId": "649f07e619fca8aa63d842f6",
"name": "job1",
"scheduleTime": "2024-01-01T00:00:00Z",
"createdAt": "2023-06-30T16:50:46.3042083Z",
"updatedAt": "2023-06-30T16:50:46.3042086Z",
"status": 2,
"jobData": {
"SourceAddress": "example@example.com",
"DestinationAddress": "example@example.com",
"Subject": "subject ",
"Message": "message"
}
}
- 在应用程序内创建一个名为“模型”的文件夹,然后为模块创建__init__.py。创建一个名为email_job的文件夹和一个名为__init__.py的文件,并将内容设置为
import json
class JsonObject:
def toJsonData(self):
return json.dumps(vars(self)).encode('utf-8')
def valueForKey(self,key,json):
try:
return json[key]
except Exception as e:
print(f"no value for json key : {key}")
raise e
class EmailJob(JsonObject):
def __init__(self, json):
self.jobId = self.valueForKey("jobId",json)
self.status = int(self.valueForKey("status",json))
self.JobData = self.valueForKey("jobData",json)
def get_email(self):
return Email(self.JobData)
class Email(JsonObject):
def __init__(self,json):
self.SourceAddress = self.valueForKey("SourceAddress",json)
self.DestinationAddress= self.valueForKey("DestinationAddress",json)
self.Subject = self.valueForKey("Subject",json)
self.Message = self.valueForKey("Message",json)
- 现在创建一个名为Message_Broker Infem emails_job文件夹的文件夹。创建一个名为emailjob_consumer_service.py的文件,并设置here的内容。运行Kafka消费者工人的逻辑来到这里。我们在构造函数中接受配置和电子邮件执行者,然后使用以下功能运行KAFKA消费者工人。
def run(self):
logging.info(f"Starting email job consumers with {self.cfg.TopicJobRunWorkerCount } workers...")
if self.cfg.TopicJobRunWorkerCount == 1:
self.run_worker()
logging.info(f"Worker 1 started for consuming job events...")
else:
worker_threads = []
for i in range(0,self.cfg.TopicJobRunWorkerCount):
t = Thread(target=self.worker)
t.Daemon = True
worker_threads.append(t)
t.start()
logging.info(f"Worker {i} started for consuming job events...")
for t in worker_threads:
t.join()
def run_worker(self):
job_consumer = JobConsumer(self.cfg, self.emailExecuter)
job_consumer.run()
- 内部Message_Broker创建一个名为emailjob_consumer_worker.py的文件,并设置here的内容。此处实施了用于主题工作的Kafka消费者的逻辑。我们在构造函数中接收配置和电子邮件发送者类,然后通过以下功能运行消费者:
def run_kafka_consumer(self):
consumer = KafkaConsumer(self.cfg.TopicJobRun,
group_id=self.cfg.TopicJobRunConsumerGroupID,
bootstrap_servers=self.cfg.KafkaBrokers,
value_deserializer= self.loadJson)
for msg in consumer:
if isinstance(msg.value, EmailJob):
logging.info("An email job json recieved. doing the job.")
self.handleJob(msg.value)
else:
logging.error(f"error handling: {msg}")
在应用程序文件夹中创建一个名为Server的文件夹和一个名为__init__.py的文件。将内容设置为:
from config import Config
from app.email.email_sender import EmailSender
from app.models.email_job.message_broker.emailjob_consumer_service import EmailjobConsumerService
class Server:
def run(self, cfg: Config):
es = EmailSender(cfg)
ecs = EmailjobConsumerService(cfg,es)
ecs.run()
- 现在返回到app文件夹的__init__.py,然后将代码更改为
import logging
from config import Config
from app.server import Server
def create_app():
logging.info("Creating job-executor app")
config = Config()
s = Server()
s.run(config)
- 现在运行
python run main.py如果一切按计划进行,我们的应用程序开始并等待来自kafka的消息。- 在主题下转到
http://localhost:8080/选择topic-job-run。从右上单击Produce message按钮,然后将值设置为以下JSON,然后单击“生产消息”。
{
"jobId": "649f07e619fca8aa63d842f6",
"name": "job1",
"scheduleTime": "1970-01-01T00:00:00Z",
"createdAt": "2023-06-30T16:50:46.3042083Z",
"updatedAt": "2023-06-30T16:50:46.3042086Z",
"status": 2,
"jobData": {
"SourceAddress": "example@example.com",
"DestinationAddress": "example@example.com",
"Subject": "Message From example@example.com contact form",
"Message": "This is a Job test!!!!"
}
}
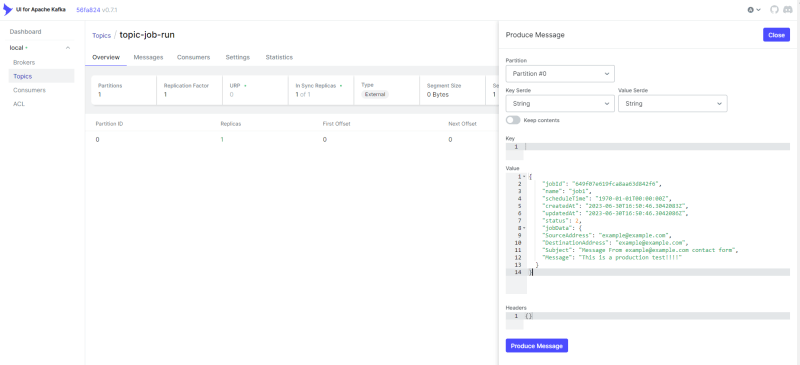
- 该应用程序会消耗消息,然后尝试发送电子邮件,然后为主题
topic-job-run-result提供另一个消息,该主题在我们的微服务应用程序中将被调度程序服务消费。您可以转到http://localhost:8080/,在主题下,您可以看到创建了另一个主题,并且它有一条消息。 (注意:我们已经在开发环境中激活了Kafka中的自动主题创建。在生产环境中,为整个微服务应用程序提供单独的主题创建和管理服务是很常见的)。
- 做
- 添加测试
- 使用Jaeger添加跟踪
- 使用Grafana添加监视和分析
- 重构
我很想听听您的想法。请评论您的意见。如果您发现这很有帮助,让我们在Twitter上保持联系! khaled11_33。