这是一系列文章的第三部分,名称为“ Play Microservices” 。链接到其他部分:
第1部分:Play Microservices: Bird's eye view
第2部分:Play Microservices: Authentication
第3部分:您在这里
可以找到该项目的源代码here:
内容:
- 摘要
- 工具
- docker dev环境
- 数据库服务:MongoDB
- Mongo Express服务
- kafka元数据服务:Zookeeper
- zoonavigator服务
- 消息经纪服务:kafka
- kafka-UI服务
- 调度程序grpcui-service
- 调度程序服务:Golang
- 做
- 摘要
在第二部分中,我们开发了身份验证服务。现在,我们的目标是为我们的微服务应用程序创建作业调度程序服务。为了实现这一目标,我们需要四个不同的服务:数据库服务,消息代理服务,专门用于支持消息代理的元数据数据库服务以及Scheduler Service本身,即GRPC API服务。此外,在开发环境中,我们包括四个专门用于调试目的的额外服务。这些服务由Mongo Express组成,用于管理我们的数据库服务,用于管理我们的Kafka服务的Kafkaui,Zookeeper服务的Zoonavigator和用于测试我们的GRPC API的GRPCUI。

最后,项目目录结构将显示如下:

- 工具
主机机器中所需的工具:
- Docker:容器化工具
- VSCode:代码编辑工具
- vscode的Dev containsers扩展
- vscode的Docker扩展
- Git
我们将在每种服务内部使用内部容器中使用的工具和技术:
- 数据库服务:Mongo
- Mongo Express服务:Mongo express
- 消息传递服务:Kafka <¥Kagkanii-E Stater:Kafka-ui
- 元数据服务:Zookeeper
- zoonavigator服务:Zoonavigator
- grpcui service: grpcui
- 调度程序API服务:
- Golang : programming language
- gRPC-GO: gRPC framework for golang
- Mongo driver:我们的数据库通信查询构建器。
- Kafka go用于我们的消息经纪传播。
- Quartz 用于调度目的。
- docker dev环境
Docker容器内部的开发可以提供多种好处,例如一致的环境,孤立的依赖关系和改进的协作。通过使用Docker,开发工作流可以与团队成员进行集装和共享,从而可以在不同的机器和平台之间进行一致的部署。开发人员可以轻松地在不同版本的依赖项和库之间切换,而不必担心冲突。

在Docker容器内开发时,您只需要在VS代码上安装Docker,Visual Studio Code和Dev Containers和Dockerextensions。然后,您可以使用Docker运行一个容器,并将主机文件夹映射到容器内部的文件夹,然后将VSCODE连接到运行的容器并开始编码,所有更改将反映在主机文件夹中。如果删除图像和容器,则可以通过使用Dockerfile重新创建容器并将内容从主机文件夹复制到容器文件夹来轻松重新开始。但是,重要的是要注意,在这种情况下,需要再次下载容器内部所需的任何工具。在引擎盖下,将VSCODE连接到运行的容器时,Visual Studio代码安装并在容器内运行特殊服务器,该服务器处理容器和主机机器之间更改的同步。
- 数据库服务:Mongo
- 为项目创建一个文件夹,然后为其选择一个名称(例如“微服务”)。然后创建一个名为
scheduler的文件夹。该文件夹是当前项目的根目录。然后,您可以通过右键单击该文件夹并选择“使用代码打开”来打开VS代码中的根文件夹。- 根目录内部创建一个具有名称Scheduler-DB服务的文件夹,然后在内部创建以下文件。
- 创建一个dockerfile并将内容设置为
FROM mongo:7.0.0-rc5- 创建一个名为pass.txt的文件并将内容设置为
password- 创建一个名为user.txt的文件,然后将内容设置为
admin- 创建一个名为db_name.txt的文件,然后将内容设置为
jobs_db- 在root目录中创建一个名为.env的文件,然后将内容设置为
MONGODB_PORT=27017。- 在根目录内部创建一个名为Docker-compose.yml的文件,然后添加以下内容。
version: '3'
services:
# database service for scheduler service
scheduler-db-service:
build:
context: ./scheduler-db-service
dockerfile: Dockerfile
container_name: scheduler-db-service
environment:
MONGO_INITDB_ROOT_USERNAME_FILE: /run/secrets/scheduler-db-user
MONGO_INITDB_ROOT_PASSWORD_FILE: /run/secrets/scheduler-db-pass
env_file:
- ./scheduler-db-service/.env
ports:
- ${MONGODB_PORT}:${MONGODB_PORT}
secrets:
- scheduler-db-user
- scheduler-db-pass
- scheduler-db-dbname
volumes:
- scheduler-db-service-VL:/data/db
volumes:
scheduler-db-service-VL:
secrets:
scheduler-db-user:
file: scheduler-db-service/user.txt
scheduler-db-pass:
file: scheduler-db-service/pass.txt
scheduler-db-dbname:
file: scheduler-db-service/db_name.txt
- 在我们的Docker组成文件中,我们使用秘密在容器之间安全共享凭据数据。虽然我们可以使用.ENV文件和环境变量,但这并不是安全的。在撰写文件中定义秘密时,docker会在每个容器内部在
/run/secrets/路径下创建一个文件(具有秘密名称),然后可以将其读取和使用。例如,我们将将Docker的路径构成Secretscheduler-db-pass的路径到调度程序服务的DATABASE_PASS_FILE环境变量。然后,该服务将转到路径(/run/secrets/scheduler-db-pass)并读取密码文件。我们将在项目后面的其他服务中使用这些秘密。
- Mongo Express服务
此服务的目的仅用于开发环境中运行数据库服务器的调试和管理。
- 在根目录内部创建一个名称Mongo-express-Service
的文件夹- 创建一个dockerfile并将内容设置为
FROM mongo-express:1.0.0-alpha.4- 创建一个名为.env dockerfile旁边的文件,然后将内容设置为
ME_CONFIG_BASICAUTH_USERNAME=admin
ME_CONFIG_BASICAUTH_PASSWORD=password123
ME_CONFIG_MONGODB_ENABLE_ADMIN=true
- 将以下行添加到docker-compose的.env文件(项目根目录处的.env文件)。
MONGO_EXPRESS_PORT=8081
- 将以下内容添加到docker-compose.yml的服务部分。
mongo-express:
build:
context: ./mongo-express-service
dockerfile: Dockerfile
container_name: mongo-express-service
restart: always
environment:
- ME_CONFIG_MONGODB_PORT=${MONGODB_PORT}
- ME_CONFIG_MONGODB_SERVER=scheduler-db-service
- ME_CONFIG_MONGODB_ADMINUSERNAME=root
- ME_CONFIG_MONGODB_ADMINPASSWORD=password123
env_file:
- ./mongo-express-service/.env
ports:
- ${MONGO_EXPRESS_PORT}:${MONGO_EXPRESS_PORT}
depends_on:
- scheduler-db-service
在这里,由于Mongo Express没有提供从文件读取数据库密码的功能,因此我们只需使用环境变量传递MongoDB凭据(不要忘记我们在开发环境中)。
现在在您的项目目录中打开一个终端并运行Docker-Compose。 Docker Compose将在启动容器之前下载并缓存所需的图像。在第一次奔跑中,这可能需要几分钟。如果一切都按计划进行,则可以访问http://localhost:8081/的Mongo Express面板,并使用Mongo Express凭据从Mongo-Express-Servress服务容器内的.env文件登录。您应该看到它已成功连接到Scheduler-DB服务容器。

- 现在运行Docker-Compose
- 元数据服务:Zookeeper
ZooKeeper 是用于维护配置信息的集中式服务。我们将其用作kafka消息服务的元数据存储。
- 在根目录内部创建一个名称Zookeeper-Service
的文件夹- 创建一个dockerfile并将内容设置为
FROM bitnami/zookeeper:3.8.1- 创建一个名为.env的文件,并将内容设置为
ZOO_SERVER_USERS=admin,user1
# for development environment only
ALLOW_ANONYMOUS_LOGIN="yes"
# if yes, uses SASL
ZOO_ENABLE_AUTH="no"
- 创建一个名为server_passwords.properties的文件,并将内容设置为
password123,password_for_user1,请选择自己的密码。- 将以下内容添加到docker-compose的.env文件(项目根目录处的.env文件)。
ZOOKEEPER_PORT=2181
ZOOKEEPER_ADMIN_CONTAINER_PORT=8078
ZOOKEEPER_ADMIN_PORT=8078
- 将以下内容添加到docker-compose.yml的服务部分。
zk1:
build:
context: ./zookeeper-service
dockerfile: Dockerfile
container_name: zk1-service
secrets:
- zoo-server-pass
env_file:
- ./zookeeper-service/.env
environment:
ZOO_SERVER_ID: 1
ZOO_SERVERS: zk1:${ZOOKEEPER_PORT}:${ZOOKEEPER_PORT} #,zk2:{ZOOKEEPER_PORT}:${ZOOKEEPER_PORT}
ZOO_SERVER_PASSWORDS_FILE: /run/secrets/zoo-server-pass
ZOO_ENABLE_ADMIN_SERVER: yes
ZOO_ADMIN_SERVER_PORT_NUMBER: ${ZOOKEEPER_ADMIN_CONTAINER_PORT}
ports:
- '${ZOOKEEPER_PORT}:${ZOOKEEPER_PORT}'
- '${ZOOKEEPER_ADMIN_PORT}:${ZOOKEEPER_ADMIN_CONTAINER_PORT}'
volumes:
- "zookeeper_data:/bitnami"
- 将以下内容添加到docker-compose.yml的秘密部分。
zoo-server-pass:
file: zookeeper-service/server_passwords.properties
-zookeeper是一个分布式应用程序,允许我们同时运行多个服务器。它使多个客户可以连接到这些服务器,从而促进它们之间的通信。 Zookeeper服务器协作处理数据并以协调的方式响应请求。在这种情况下,我们的Zookeeper消费者(客户端)是KAFKA服务器,这再次是一个分布式事件流平台。我们可以运行多个Zookeeper服务作为Zookeeper服务器的集合,并通过
ZOO_SERVERS环境变量将它们连接在一起。
- Bitnami Zookeeper docker Image提供了一个ZOO_CLIENT入口点,它充当内部客户端,并允许我们运行Zkcli.sh命令行工具,以与Zookeeper服务器作为客户端进行交互。但是我们将使用GUI客户端进行调试目的:zoonavigator。
- zoonavigator服务
此服务仅存在于开发环境中用于调试目的。我们使用它连接到Zookeeper-Service并管理数据。
- 在根目录内部创建一个名称zoonavigator-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM elkozmon/zoonavigator:1.1.2- 将
ZOO_NAVIGATOR_PORT=9000添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
zoo-navigator:
build:
context: ./zoonavigator-service
dockerfile: Dockerfile
container_name: zoo-navigator-service
ports:
- '${ZOO_NAVIGATOR_PORT}:${ZOO_NAVIGATOR_PORT}'
environment:
- CONNECTION_LOCALZK_NAME = Local-zookeeper
- CONNECTION_LOCALZK_CONN = localhost:${ZOOKEEPER_PORT}
- AUTO_CONNECT_CONNECTION_ID = LOCALZK
depends_on:
- zk1
- 现在从终端运行
docker-compose up -d --build- 跑步时,请转到
http://localhost:9000/。您将看到以下屏幕:
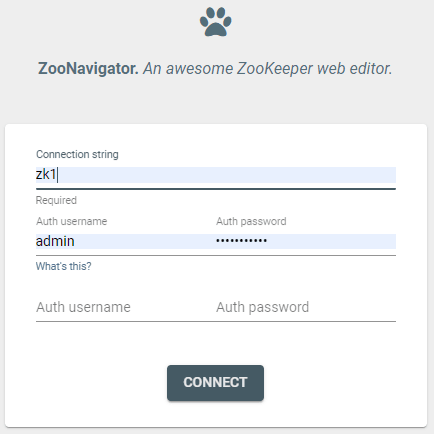
- 输入Zookeeper服务的容器名称(此处ZK1)。如果一切都按计划进行,您应该能够建立与Zookeeper服务的连接。

- 没有跑步码头组合。我们稍后将返回这些工具。
- 消息经纪服务:kafka
Apache Kafka是一个开源分布式事件流平台,非常适合微服务架构。它是实现事件采购等模式的理想选择。在这里,我们将其用作调度程序服务的消息经纪。
- 在根目录内部创建一个名称kafka-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM bitnami/kafka:3.4.1- 在Docker文件旁边创建一个.env文件,并将内容设置为:
ALLOW_PLAINTEXT_LISTENER=yes
KAFKA_ENABLE_KRAFT=no
- 将
KAFKA1_PORT=9092添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
kafka1:
build:
context: ./kafka-service
dockerfile: Dockerfile
container_name: kafka1-service
ports:
- '${KAFKA1_PORT}:${KAFKA1_PORT}'
volumes:
- "kafka_data:/bitnami"
env_file:
- ./kafka-service/.env
environment:
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:${KAFKA1_PORT},LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:${KAFKA1_PORT}
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_CFG_ZOOKEEPER_CONNECT: zk1:${ZOOKEEPER_PORT}
KAFKA_ZOOKEEPER_PROTOCOL: PLAINTEXT #if auth is enabled in zookeeper use one of: SASL, SASL_SSL see https://hub.docker.com/r/bitnami/kafka
KAFKA_CFG_LISTENERS: PLAINTEXT://:${KAFKA1_PORT}
depends_on:
- zk1
- 为了连接到我们的Kafka经纪人进行调试目的,我们运行了另一项服务。 kafka-ui。
- kafka-UI服务
此服务仅存在于开发环境中用于调试目的。我们使用它连接到Kafka服务并管理数据。
- 在根目录内部创建一个名称kafkaui-service
的文件夹- 创建一个dockerfile并将内容设置为
FROM provectuslabs/kafka-ui:latest- 将
KAFKAUI_PORT=8080添加到docker-compose的.env文件(项目的根目录处的.env文件。)- 将以下内容添加到docker-compose.yml的服务部分。
kafka-ui:
build:
context: ./kafkaui-service
dockerfile: Dockerfile
container_name: kafka-ui-service
restart: always
ports:
- ${KAFKAUI_PORT}:${KAFKAUI_PORT}
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka1:${KAFKA1_PORT}
DYNAMIC_CONFIG_ENABLED: 'true'
depends_on:
- kafka1
- 现在运行
docker-compose run -d --build。在运行容器时,请转到http://localhost:8080/打开Kafka-UI仪表板。
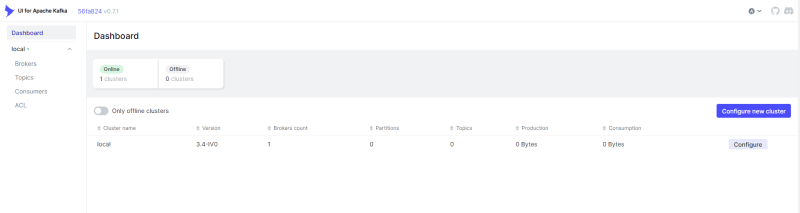
- 从界面中,您可以查看和管理经纪人,主题和消费者。我们将很快详细介绍这些元素。
- 运行
docker-compose down- 我们所需的服务已准备就绪并运行。现在是时候为我们的调度程序服务准备开发环境了。

- 调度程序grpcui-service
在开始开发调度程序服务之前,让我们将额外的服务纳入我们的开发环境中。该服务将促进与我们的调试目的的调度器服务的互动。
- 创建一个名为grpcui-service的文件夹内的调度程序文件夹。
- 创建一个docker文件并将内容设置为
FROM fullstorydev/grpcui:v1.3.1- 将以下内容添加到docker-compose.yml文件的服务部分。
grpcui-service:
build:
context: ./grpcui-service
dockerfile: Dockerfile
container_name: grpcui-service
command: -port $GRPCUI_PORT -plaintext scheduler-service:${SCHEDULER_PORT}
restart: always
ports:
- ${GRPCUI_PORT}:${GRPCUI_PORT}
depends_on:
- scheduler-service
- 添加
GRPCUI_PORT=5000撰写.env文件。 (.env文件在Docker-Compose旁边)- 我们稍后将返回此服务。
- 调度程序服务:Golang
我们的目标是使用GO开发GRPC服务器。开发GRPC服务器的典型管道非常简单。您可以在.proto文件中定义GRPC架构(有关更多信息,请参见here)。然后,您使用协议缓冲器编译器工具(实际上您实际上是将.proto编译为目标编程语言)并将其导入项目。然后,您使用目标语言中的GRPC框架来运行GRPC服务器。该服务器在功能参数中使用.proto模型。接下来,您可以定义相应的数据库层模型,并使用转换器在它们之间转换。您会收到GRPC型号VIS GRPC服务器,将其转换为数据库模型,然后将其存储在数据库中。如果查询查询,您可以从数据库中查询数据,将它们转换为GRPC模型并将其返回给用户。
这是我们将要做的事情的摘要:我们首先在开发环境中安装protoc。然后初始化我们的GO项目,定义我们的原始方案并使用上述工具对其进行编译,然后运行初始的GRPC服务器。然后,我们添加数据库层模型和类。
- 在调度程序文件夹中创建一个名为
scheduler-service的文件夹。- 在
scheduler-service内创建一个Dockerfile,并将内容设置为
FROM golang:1.19
ENV PROTOC_VERSION=23.3
ENV PROTOC_ZIP=protoc-${PROTOC_VERSION}-linux-x86_64.zip
RUN apt-get update && apt-get install -y unzip
RUN curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v${PROTOC_VERSION}/$PROTOC_ZIP \
&& unzip -o $PROTOC_ZIP -d /usr/local bin/protoc \
&& unzip -o $PROTOC_ZIP -d /usr/local 'include/*' \
&& rm -f $PROTOC_ZIP
RUN go install google.golang.org/protobuf/cmd/protoc-gen-go@latest
RUN go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest
RUN export PATH="$PATH:$(go env GOPATH)/bin"
WORKDIR /usr/src/app
- 将以下内容添加到我们docker-compose.yml文件的服务部分。
scheduler-service:
build:
context: ./scheduler-service
dockerfile: Dockerfile
container_name: scheduler-service
command: sleep infinity
environment:
ENVIRONMENT: development
SERVER_PORT: ${SCHEDULER_PORT}
DATABASE_USER_FILE: /run/secrets/scheduler-db-user
DATABASE_PASS_FILE: /run/secrets/scheduler-db-pass
DATABASE_DB_NAME_FILE: /run/secrets/scheduler-db-dbname
DATABASE_SCHEMA: mongodb
DATABASE_HOST_NAME: scheduler-db-service
DATABASE_PORT: ${MONGODB_PORT}
KAFKA_BROKERS: kafka1-service:${KAFKA1_PORT}
ports:
- ${SCHEDULER_PORT}:${SCHEDULER_PORT}
volumes:
- ./scheduler-service:/usr/src/app
secrets:
- scheduler-db-user
- scheduler-db-pass
- scheduler-db-dbname
- 我们将在码头容器内部进行所有开发,而无需在主机机器中安装golang。为此,我们运行容器,然后将VSCODE连接到调度程序服务容器。您可能会注意到,Scheduler-Service的Dockerfile没有入口点,因此我们将调度程序服务的命令值设置为
sleep infinity,以保持容器清醒。- 现在运行
docker-compose up -d --build- 在运行时,通过单击左下图标,然后选择
attach to running container,将其连接到调度程序服务。选择调度程序服务,然后等待VSCODE的新实例启动。一开始,Vscode要求我们打开容器内部的文件夹。我们在Dockerfile内选择了WORKDIR /usr/src/app,因此我们将在容器内打开此文件夹。此文件夹将使用Docker组成的音量安装到主机计算机内的调度程序服务文件夹,因此,我们所做的任何更改也将同步到主机文件夹。- 打开文件夹
/usr/src/app后,打开一个新的终端,然后通过运行go mod init github.com/<your_username>/play-microservices/scheduler/scheduler-service初始化GO项目。此命令将创建一个go.mod文件。- 运行
go get -u google.golang.org/grpc。这是使用Golang运行GRPC服务器的GRPC框架。- 运行
go get -u google.golang.org/grpc/reflection。我们将反射添加到我们的GRPC服务器,以便我们的GRPCUI服务可以连接到它并轻松地检索端点和消息以进行调试。- 现在创建一个名为proto的文件夹,并创建一个名为job.proto内部的文件。设置here的内容
- 运行
protoc --go_out=./proto --go-grpc_out=./proto proto/*.proto。此命令将我们的.proto文件编译到Golang。将创建两个文件。 job.pb.go和job_grpc.pb.go。第一个包含原始模型,第二个包含工作服务接口的代码(我们需要创建我们的服务并实现此接口)。- 注意:我们采用了与建议的指南here相符的Golang项目结构
- 创建一个名为Config的文件夹和一个名为
config.go的文件。设置here的内容。还可以在同一文件夹中创建一个名为.env的文件。我们将将内部环境变量放在这里。设置here的内容。创建另一个名为.ENV.Topics的文件,以将Kafka主题放置。对于生产环境,我们通过Docker构成秘密传递主题文件,并通过TOPICS_FILE环境变量发送文件位置。然后,我们加载文件的内容。- 在根目录中创建一个名为pkg的文件夹(旁边是mod.go)。我们将在这里放置通用软件包。内部创建一个名为Logger的文件夹,然后在一个名为Logger.go的文件中设置来自here的内容。
- 创建此文件夹树:
internal/models/job/grpc。在GRPC文件夹中创建一个名为job_service.go的文件,然后将内容设置为
package grpc
import (
context "context"
pb "github.com/<your_username>/play-microservices/scheduler/scheduler-service/proto"
codes "google.golang.org/grpc/codes"
status "google.golang.org/grpc/status"
)
type JobService struct {
pb.UnimplementedJobServiceServer
}
func NewJobService() *JobService {
return &JobService{}
}
func (j *JobService) CreateJob(ctx context.Context, req *pb.CreateJobRequest) (*pb.CreateJobResponse, error) {
return nil, status.Errorf(codes.Unimplemented, "method CreateJob not implemented")
}
func (JobService) GetJob(context.Context, *pb.GetJobRequest) (*pb.GetJobResponse, error) {
return nil, status.Errorf(codes.Unimplemented, "method GetJob not implemented")
}
func (JobService) ListJobs(context.Context, *pb.ListJobsRequest) (*pb.ListJobsResponse, error) {
return nil, status.Errorf(codes.Unimplemented, "method ListJobs not implemented")
}
func (JobService) UpdateJob(context.Context, *pb.UpdateJobRequest) (*pb.UpdateJobResponse, error) {
return nil, status.Errorf(codes.Unimplemented, "method UpdateJob not implemented")
}
func (JobService) DeleteJob(context.Context, *pb.DeleteJobRequest) (*pb.DeleteJobResponse, error) {
return nil, status.Errorf(codes.Unimplemented, "method DeleteJob not implemented")
}
- 在内部文件夹中创建一个名为“服务器”的文件夹。然后一个名为server.go的文件。将内容设置为
package server
import (
"log"
"net"
"github.com/<your_username>/play-microservices/scheduler/scheduler-service/config"
"github.com/<your_username>/play-microservices/scheduler/scheduler-service/pkg/logger"
MyJobGRPCService "github.com/<your_username>/play-microservices/scheduler/scheduler-service/internal/models/job/grpc"
JobGRPCServiceProto "github.com/<your_username>/play-microservices/scheduler/scheduler-service/proto"
"google.golang.org/grpc"
"google.golang.org/grpc/reflection"
)
type server struct {
log logger.Logger
cfg *config.Config
}
// NewServer constructor
func NewServer(log logger.Logger, cfg *config.Config) *server {
return &server{log: log, cfg: cfg}
}
func (s *server) Run() error {
lis, err := net.Listen("tcp", ":"+s.cfg.ServerPort)
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
grpc_server := grpc.NewServer()
job_service := MyJobGRPCService.NewJobService()
JobGRPCServiceProto.RegisterJobServiceServer(grpc_server, job_service)
reflection.Register(grpc_server)
log.Printf("server listening at %v", lis.Addr())
if err := grpc_server.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
return err
}
return nil
}
- 创建一个名为cmd的文件夹和一个名为main.go的文件。将内容设置为
package main
import (
"log"
"github.com/<your_username>/play-microservices/scheduler/scheduler-service/config"
"github.com/<your_username>/play-microservices/scheduler/scheduler-service/pkg/logger"
"github.com/<your_username>/play-microservices/scheduler/scheduler-service/internal/server"
)
func main() {
cfg, err := config.InitConfig()
if err != nil {
log.Fatal(err)
}
appLogger := logger.NewApiLogger(cfg)
appLogger.InitLogger()
appLogger.Info("Starting user server")
appLogger.Infof(
"AppVersion: %s, LogLevel: %s, Environment: %s",
cfg.AppVersion,
cfg.Logger_Level,
cfg.Environment,
)
appLogger.Infof("Success parsed config: %#v", cfg.AppVersion)
s := server.NewServer(appLogger, cfg)
s.Run()
}
- 运行
go mod tidy- Run
go run cmd/main.go- 当我们的服务器运行时,请转到Docker桌面并重新启动GRPCUI服务。现在转到
http://localhost:5000/。如果一切都在计划中,您可以连接到服务器。

- 调用任何方法都会导致
method xxx not implemented中的任何方法,因为我们仍未实施我们的工作服务方法。- 返回到已经连接到我们调度程序服务的VSCODE实例。通过击中
ctl + c停止服务- 创建一个名为job.go内部模型文件夹的文件。在此文件中,我们将定义与原始模型相对应的数据库层模型。从/转换为原始模型的逻辑来到这里。另外,我们为工作模型数据库定义了一个接口,并为工作模型事件消息传递的接口定义了一个接口。从here设置作业的内容。
// databas interface for Job model
type JobDB interface {
Create(ctx context.Context, job *Job) (*Job, error)
Update(ctx context.Context, job *Job) (*Job, error)
GetByID(ctx context.Context, jobID primitive.ObjectID) (*Job, error)
DeleteByID(ctx context.Context, jobID primitive.ObjectID) (error)
GetByScheduledKey(ctx context.Context, jobScheduledKey int) (*Job, error)
DeleteByScheduledKey(ctx context.Context, jobScheduledKey int) (error)
ListALL(ctx context.Context, pagination *utils.Pagination) (*JobsList, error)
}
//Message broker interface for Job model
type JobsProducer interface {
PublishCreate(ctx context.Context, job *Job) error
PublishUpdate(ctx context.Context, job *Job) error
PublishRun(ctx context.Context, job *Job) error
}
type JobService struct {
jobDB models.JobDB
jobsProducer models.JobsProducer
jobsScheduler scheduler.Scheduler
pb.UnimplementedJobServiceServer
}
func NewJobService(jobDB models.JobDB, jobsProducer models.JobsProducer, jobsScheduler scheduler.Scheduler) *JobService {
return &JobService{jobDB: jobDB, jobsProducer: jobsProducer, jobsScheduler: jobsScheduler}
}
- 现在是时候选择数据库引擎并使用它来实现
JobDB接口了。运行go get go.mongodb.org/mongo-driver。在internal/models/job文件夹中创建一个名为database的文件夹。然后一个名为job_db_mongo.go的文件。设置here的内容- 在PKG目录中创建一个名为MongoDB的文件夹,然后创建一个名为Mongodb.go的文件。该软件包用于初始化我们的Mongo DB数据库。设置here的内容。
- 现在,我们选择一个消息代理框架,然后使用它实现
JobsProducer接口。运行go get github.com/segmentio/kafka-go。在internal/models/job文件夹中创建一个名为Message_broker的文件夹。然后在这里创建一个名为job_producer_kafka.go的归档,我们实现了JobsProducer接口。设置here的内容。- 在PKG中创建一个名为Kafka的文件夹,然后创建一个名为Kafka.go的文件。该软件包用于初始化Kafka连接。设置here的内容。
- 关于卡夫卡体系结构的一些注释:
- 主题:kafka中的核心抽象并表示记录流。
- 分区:作为记录链的主题可以分配给分区以实现并行处理和可扩展性。分区可以分配在经纪人中,也可以位于一个经纪人中。
- 经纪人:经纪人是构成集群的Kafka服务器。他们以分布式的方式存储和管理已发布的记录。
- 复制:Kafka提供了数据复制以实现错误的容忍度。每个分区都可以在不同的经纪人中分布多个副本。复制品确保如果经纪人失败,另一个经纪人可以接管并继续无缝提供数据。
- 生产者:生产者负责向Kafka主题发布数据。
- 消费者:消费者阅读来自Kafka主题的数据。消费者属于消费者群体。每个消费者都可以订阅多个主题,但仅用于一个主题的一个分区。
- 配置Kafka环境可能很棘手,并且取决于用例。

"github.com/pkg/errors"
- 从here设置Job_service.go的内容。 CreateJob函数的代码如下:
func (j *JobService) CreateJob(ctx context.Context, req *pb.CreateJobRequest) (*pb.CreateJobResponse, error) {
job := models.JobFromProto_CreateJobRequest(req)
job.Status = int32(pb.JobStatus_SCHEDULED)
jobFingerPrint := fmt.Sprintf("%s:%s:%s:%p", job.Name, job.Description, job.JobData, &job.ScheduleTime)
job.ScheduledKey = int(fnv1a.HashString64(jobFingerPrint)) //We assume 64 bit systems!
//cretae job in the database
created, err := j.jobDB.Create(ctx, job)
if err != nil {
return nil, grpcErrors.ErrorResponse(err, err.Error())
}
jobID := created.JobID
functionJob := jobFucntion.NewFunctionJobWithKey(job.ScheduledKey, func(_ context.Context) (int, error) {
jb, err := j.jobDB.GetByID(ctx, jobID)
if err != nil {
return 0, grpcErrors.ErrorResponse(err, err.Error())
}
//set the state of the job to running
jb.Status = int32(pb.JobStatus_RUNNING)
_, err2 := j.jobDB.Update(ctx, jb)
if err2 != nil {
return 0, grpcErrors.ErrorResponse(err2, err2.Error())
}
j.jobsProducer.PublishRun(ctx, job)
return 0, nil
})
triggerTime := time.Duration(time.Until(job.ScheduleTime).Seconds())
j.jobsScheduler.ScheduleJob(ctx, functionJob, scheduler.NewSimpleTrigger(triggerTime))
j.jobsProducer.PublishCreate(ctx, created)
return &pb.CreateJobResponse{Id: created.JobID.String()}, nil
}
我们在GRPC服务器中接收CreateJob。我们首先将.proto模型转换为
job := models.JobFromProto_CreateJobRequest(req)中的数据库层模型。然后,我们将状态设置为计划,并将其保存到数据库中并检索ID。然后,我们安排工作并发布topic-job-create,以被其他服务(例如报告服务)消费,最后我们将CreateJobresponse返回给用户。在计划功能中,我们从数据库中检索作业,然后将JobState设置为运行,然后将其再次保存到数据库中。然后,我们发布了topic-job-run,将由我们的跑步者服务消费。然后,我们收听将由Job Runner触发的topic-job-run-result事件。如果结果是成功,我们将更改工作状态以将其保存到数据库中。运行
go mod tidy运行
go run cmd/main.go现在转到Docker Desktop重新启动GRPCUI服务。然后转到
http://localhost:5000/。如果一切都按计划进行,则可以连接到服务。从方法名称中选择CreateJob,然后填写表单。在时间表的时间内,如果您在时间之前的时间。now()()时间表将立即触发。对于工作数据,根据工作类型,我们需要发送特定的JSON字符串。对于电子邮件类型,我们需要发送具有以下结构的JSON:
{
"SourceAddress": "example@example.com",
"DestinationAddress": "example@example.com",
"Subject": "Message From example@example.com contact form",
"Message": "This is a production test!!!!"
}
- 按下调用按钮。您将收到创建的工作ID。
- 转到
http://localhost:8081/并检查数据库。

- 现在转到
http://localhost:8080/。您可以看到已经创建了3个主题。topic-job-create和topic-job-run的消息数为1。因为我们已经发布了topic-job-create,并且topic-job-run已在我们的计划函数中发布。

- 通过击中
ctl + c停止服务- 关于Kafka主题创建的注释:通常在微服务架构中进行主题创建的两种常见方法。
- 集中式主题创建:专门的团队或基础架构管理员负责创建和管理Kafka主题。
- 自助主题创建:在这种方法中,每个微服务都负责创建和管理自己的Kafka主题。在这里,在开发环境中,我们遵循这种方法,主题的生产者负责主题创建。我们在.env.Topic文件中为开发环境定义主题名称,并从该文件中加载它们。对于生产环境,我们可以使用topics_file环境变量(来自Docker撰写秘密的文件的位置),然后从中加载数据。
- 我们需要收听
topic-job-run结果。为此,我们必须订阅topic-job-run-result主题。为此,在路径内部/型号/job/message_broker中创建一个名为job_consumer_kafka.go的文件。然后设置来自here的内容。- 将以下内容添加到server.go文件。
jobsConsumer := kafka.NewJobsConsumerGroup(s.log, job_db)
jobsConsumer.Run(ctx, cancel, s.kafkaConn, s.cfg)
- 运行
go mod tidy然后运行go run cmd/main.go- 转到
http://localhost:8080/,在消费者的领导下,您可以看到我们是消费者的组ID的job-run-result-consumer。现在,转到主题 - > topic-job-create,在“消息”选项卡中,单击消息的值的预览,然后复制消息的JSON结构。这样的东西(您需要复制您的内容,因为在收听时,我们在数据库中搜索Jobid):
{
"jobId": "649f07e619fca8aa63d842f6",
"name": "job1",
"scheduleTime": "1970-01-01T00:00:00Z",
"createdAt": "2023-06-30T16:50:46.3042083Z",
"updatedAt": "2023-06-30T16:50:46.3042086Z",
"status": 2,
"scheduledKey": 6072375870331110000
}
- 将JSON字符串的作业状态的值设置为4。
- 现在转到主题 - >主题 - job-run-result,然后从右上角单击“生产消息”。将JSON字符串粘贴到值中,然后单击“农产品”消息。如果一切都按计划进行,则可以看到Vscode终端的结果。您也可以在http://localhost:8081/上访问Mongo Express,看看工作状态已更改为4。
- 做
- 添加测试
- 使用Jaeger添加跟踪
- 使用Grafana添加监视和分析
- 重构
我很想听听您的想法。请评论您的意见。如果您发现这很有帮助,让我们在Twitter上保持联系! khaled11_33。