在Neo4J中使用地理空间数据的资源
在这篇文章中,我们探讨了一些在Neo4J中使用地理空间数据的技术。我们将介绍一些基本的空间密码函数,空间搜索,路由算法以及将地理空间数据导入Neo4J的不同方法。
我最近在Neo4J直播的一集中浏览了空间密码备忘单中的示例,您可以观看下面的recording:
Spatial Cypher Cheat Sheet的第一页引入了Cypher和属性图数据模型,即Neo4J数据库中可用的空间类型,以及某些在Cypher中可用的空间功能。我们还涉及将地理空间数据导入到neo4j(来自CSV和GEOJSON)以及某些路径找到算法(广度优先搜索,Dijkstra的算法和A*)。
。
Spatial Cypher Cheat Sheet的第2页使用python使用neo4j覆盖。首先,使用neo4j python驱动程序从neo4j查询数据来构建GeodataFrame。然后,我们使用OSMNX Python软件包探索从OpenStreetMap获取数据,以将道路网络加载到Neo4J中。

您可以在此博客文章的其余部分中继续阅读相同的内容。
Introduction To Geospatial Cypher Functions With Neo4j
- Cypher和属性图数据模型的简介
- 空间点类型
- 空间密码函数
- 数据导入
- 与路径的路由查找算法
- neo4j python驱动程序
- 从存储在neo4j中的数据中创建一个geodataframe
- 使用OpenStreetMap数据
- 使用OSMNX加载道路网络
- 用neo4j开花和图形数据科学分析和可视化道路网络
NEO4J的地理空间密码函数简介
Cypher的简介和属性图数据模型
neo4j是一个数据库管理系统(DBMS),该系统使用由节点,关系和属性组成的属性图数据模型来建模,存储和查询数据作为图形。节点可以具有一个或多个标签,关系具有单一类型和方向。键值对属性可以存储在节点和关系上。

Cypher查询语言用于查询数据并与Neo4J交互。 Cypher是一种声明的查询语言,使用像ASCII-ART类似语法来定义构成大多数查询操作基础的图形模式。节点是用括号,与方括号的关系定义的,并且可以组合以创建复杂的图形模式。常见的cypher命令是MATCH(查找图形模式存在的位置),CREATE(使用指定的图形模式将数据添加到数据库中)和RETURN(返回数据子集是通过图形遍历的结果。
MATCH p=(sfo:Airport {iata: "SFO"})-[:FLIGHT_TO*2]->(rsw:Airport {iata: "RSW"}) RETURN p
空间点类型
neo4j支持2D或3D地理(WGS84)或笛卡尔坐标参考系统(CRS)点。在这里,我们通过指定纬度/经度来创建一个点,当使用纬度/经度时,假设WGS84假定:
RETURN point( {latitude:37.62245, longitude:-122.383989} )
点数据可以作为节点或关系上的属性存储。在这里,我们创建一个机场节点并将其位置设置为一个。
CREATE (a:Airport)
SET a.iata = "SFO",
a.location = point( {latitude:37.62245, longitude:-122.383989})
RETURN a
数据库索引用于加快搜索性能。在这里,我们在机场节点的位置属性上创建一个数据库索引。这将帮助我们在按位置搜索机场时更快地找到机场(半径距离或边界空间搜索)。
CREATE POINT INDEX airportIndex FOR (a:Airport) ON (a.location)
空间密码函数
半径距离搜索
要在图中找到靠近点或其他节点的节点,我们可以使用point.distance()函数执行半径距离搜索
MATCH (a:Airport)
WHERE point.distance(
a.location,
point({latitude:37.55948, longitude:-122.32544})) < 20000
RETURN a

在边界框中
要在边界框中搜索节点,我们可以使用point.withinBBox()函数。
MATCH (a:Airport)
WHERE point.withinBBox(
a.location,
point({longitude:-122.325447, latitude: 37.55948 }),
point({longitude:-122.314675 , latitude: 37.563596}))
RETURN a

另请参见我的其他博客文章,其中详细介绍了使用neo4j的空间搜索功能,包括polygon中的点:Spatial Search Functionality With Neo4j
地理编码
要将位置描述到纬度,经度位置,我们可以使用apoc.spatial.geocode()过程。默认情况下,此过程使用nominatim地理编码API,但可以配置为使用其他地理编码服务,例如Google Cloud。
CALL apoc.spatial.geocode('SFO Airport') YIELD location
---------------------------------------------------------------
{
"description": "San Francisco International Airport, 780, South Airport Boulevard, South San Francisco, San Mateo County, CAL Fire Northern Region, California, 94128, United States",
"longitude": -122.38398938548363,
"latitude": 37.622451999999996,
}
数据导入
我们可以使用Cypher从CSV和JSON等格式中导入数据,包括Geojson。
CSV
使用LOAD CSV cypher命令创建机场路由图。
1-在识别唯一性的字段上创建一个约束,在这种情况下为机场IATA代码。这样可以确保我们不会创建重复的机场,还可以创建一个数据库索引来提高我们数据导入步骤的性能。
CREATE CONSTRAINT FOR (a:Airport) REQUIRE a.iata IS UNIQUE;
2-创建机场节点,将其位置,名称,IATA代码等存储为节点属性。
LOAD CSV WITH HEADERS
FROM "https://cdn.neo4jlabs.com/data/flights/airports.csv"
AS row
MERGE (a:Airport {iata: row.IATA_CODE})
ON CREATE SET a.city = row.CITY,
a.name = row.AIRPORT,
a.state = row.STATE,
a.country = row.country,
a.location =
point({ latitude: toFloat(row.LATITUDE),
longitude: toFloat(row.LONGITUDE)
});
3-创建Flight_to关系与连接航班连接机场的关系。增加num_flights计数器变量以跟踪每年机场之间的航班数量。
:auto
LOAD CSV WITH HEADERS
FROM "https://cdn.neo4jlabs.com/data/flights/flights.csv" AS row
CALL {
WITH row
MATCH (origin:Airport {iata: row.ORIGIN_AIRPORT})
MATCH (dest:Airport {iata: row.DESTINATION_AIRPORT})
MERGE (origin)-[f:FLIGHT_TO]->(dest)
ON CREATE SET
f.num_flights = 0, f.distance = toInteger(row.DISTANCE)
ON MATCH SET
f.num_flights = f.num_flights + 1
} IN TRANSACTIONS OF 50000 ROWS;
geojson
我们还可以存储积分阵列以表示线条和多边形等复杂的几何形状,例如表示土地包裹。
CALL apoc.load.json('https://cdn.neo4jlabs.com/data/landgraph/parcels.geojson')
YIELD value
UNWIND value.features AS feature
CREATE (p:Parcel) SET
p.coordinates = [coord IN feature.geometry.coordinates[0] | point({latitude: coord[1], longitude: coord[0]})]
p += feature.properties;
与路径的路由查找算法
最短路径
短路函数执行二进制广度优先搜索,以找到图中节点之间的最短路径。
MATCH p = shortestPath(
(:Airport {iata: "SFO"})-[:FLIGHT_TO*..10]->(:Airport {iata: "RSW"})
) RETURN p
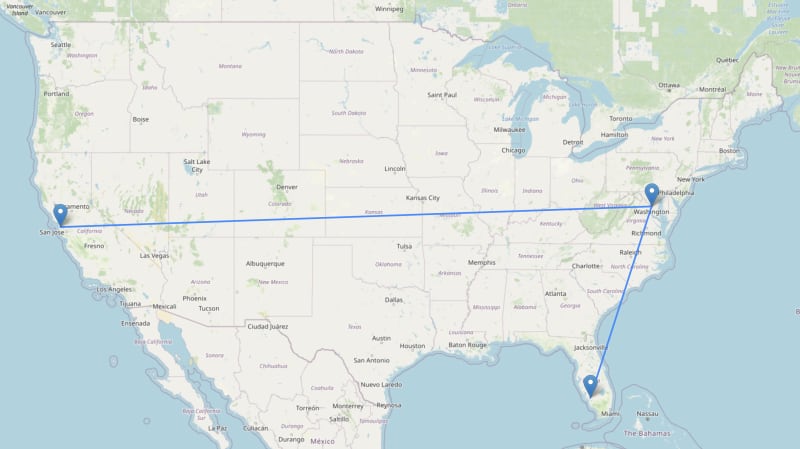
最短加权路径
通常,我们要考虑考虑距离,时间或其他成本作为关系属性的最短加权路径。 Dijkstra和A*是两种算法,在计算最短路径时考虑了关系(或边缘)的权重。
dijkstra的算法
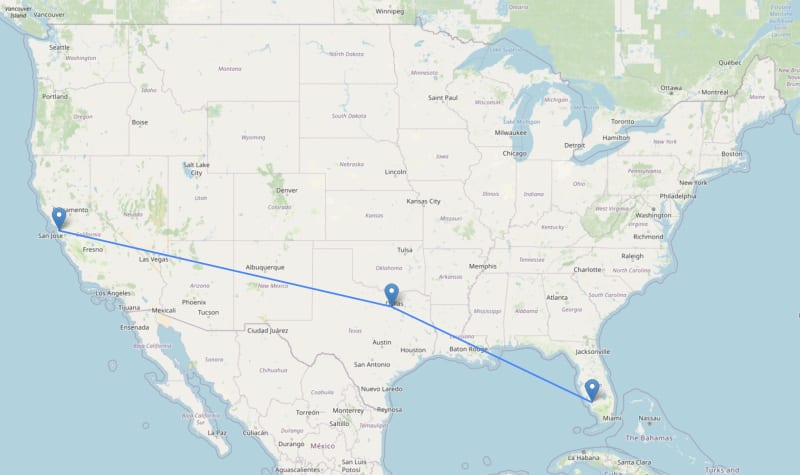
dijkstra的算法类似于广度优先的搜索,但考虑了关系属性(距离),并优先使用优先队列探索低成本路线。
MATCH (origin:Airport {iata: "SFO"})
MATCH (dest:Airport {iata: "RSW"})
CALL
apoc.algo.dijkstra(
origin,
dest,
"FLIGHT_TO",
"distance"
)
YIELD path, weight
UNWIND nodes(path) AS n
RETURN {
airport: n.iata,
lat: n.location.latitude,
lng: n.location.longitude
} AS route
a*算法
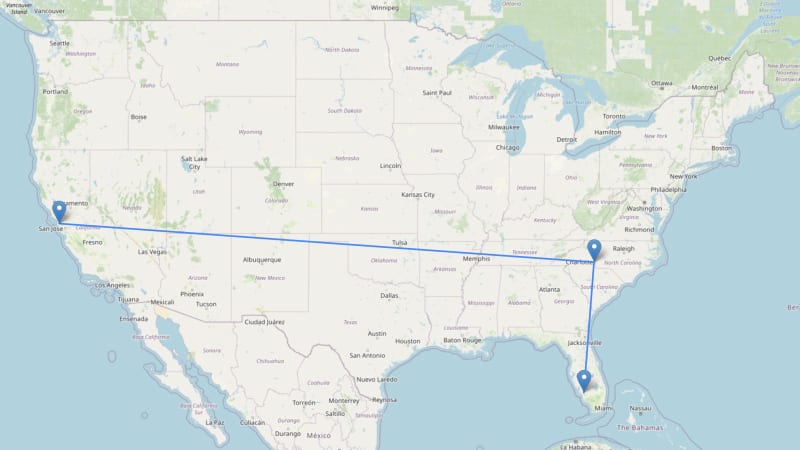
A*算法添加了一个启发式功能,以选择要探索的路径。在我们的情况下,启发式是到达最终目的地的距离。
MATCH (origin:Airport {iata: "SFO"})
MATCH (dest:Airport {iata: "RSW"})
CALL
apoc.algo.aStarConfig(
origin,
dest,
"FLIGHT_TO",
{
pointPropName: "location",
weight: "distance"
}
)
YIELD weight, path
RETURN weight, path
neo4j的Graph Data Science Library中还有其他其他路径调查算法。
将Neo4J与Python一起进行地理空间数据
Neo4J Python驾驶员
在本节中,我们将使用neo4j python驱动程序来创建飞行数据的地理框架。我们还将计算加权学位的中心性,因此我们可以在美国航空公司网络中绘制机场规模相对于其重要性。可以安装Neo4J Python驱动程序:
pip install neo4j
从存储在neo4j
的数据中创建一个GeodataFrame首先,我们导入neo4j python软件包,为neo4j实例定义我们的连接凭据(在这里我们使用局部neo4j实例),并创建一个driver实例。
import neo4j
NEO4J_URI = "neo4j://localhost:7689"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "letmeinnow"
NEO4J_DATABASE = "neo4j"
driver = neo4j.GraphDatabase.driver(
NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD)
)
接下来,我们定义一个Cypher查询以从Neo4J获取数据。除了获取机场之间的每次航班外,我们还计算了加权学位中心度,衡量了每个节点在网络中的重要性的度量,在这种情况下,与给定节点相关的所有关系权重的总和,在这种情况下为航班的数量每个机场的每年。
我们还返回了我们的起源和目的地机场的几何形状,以及众所周知的文字(WKT)。 POINT为机场和LINESTRING进行飞行路线。在定义GeodataFrame的几何形状时,我们将解析此WKT。
AIRPORT_QUERY = """
MATCH (origin:Airport)-[f:FLIGHT_TO]->(dest:Airport)
CALL {
WITH origin
MATCH (origin)-[f:FLIGHT_TO]-()
RETURN sum(f.num_flights) AS origin_centrality
}
CALL {
WITH dest
MATCH (dest)-[f:FLIGHT_TO]-()
RETURN sum(f.num_flights) AS dest_centrality
}
RETURN {
origin_wkt:
"POINT (" + origin.location.longitude + " " + origin.location.latitude + ")",
origin_iata: origin.iata,
origin_city: origin.city,
origin_centrality: origin_centrality,
dest_centrality: dest_centrality,
dest_wkt:
"POINT (" + dest.location.longitude + " " + dest.location.latitude + ")",
dest_iata: dest.iata,
dest_city: dest.city,
distance: f.distance,
num_flights: f.num_flights,
geometry:
"LINESTRING (" + origin.location.longitude + " " + origin.location.latitude + ","
+ dest.location.longitude + " " + dest.location.latitude + ")"
}
"""
接下来,我们定义一个python函数,以执行我们的Cypher查询并将结果处理到Geopandas GeodataFrame中。 Neo4J Python驱动程序具有.to_df()方法,该方法将将设置设置为PANDAS DataFrame。请注意,我们将WKT列解析为地理系列,然后将Pandas DataFrame转换为Geopandas GeodataFrame。
def get_airport(tx):
results = tx.run(AIRPORT_QUERY)
df = results.to_df(expand=True)
df.columns =
['origin_city','origin_wkt', 'dest_city', 'dest_wkt', 'origin_centrality', 'distance', 'origin_iata',
'geometry','num_flights', 'dest_centrality', 'dest_iata']
df['geometry'] = geopandas.GeoSeries.from_wkt(df['geometry'])
df['origin_wkt'] = geopandas.GeoSeries.from_wkt(df['origin_wkt'])
df['dest_wkt'] = geopandas.GeoSeries.from_wkt(df['dest_wkt'])
gdf = geopandas.GeoDataFrame(df, geometry='geometry')
return gdf
with driver.session(database=NEO4J_DATABASE) as session:
airport_df = session.execute_read(get_airport)
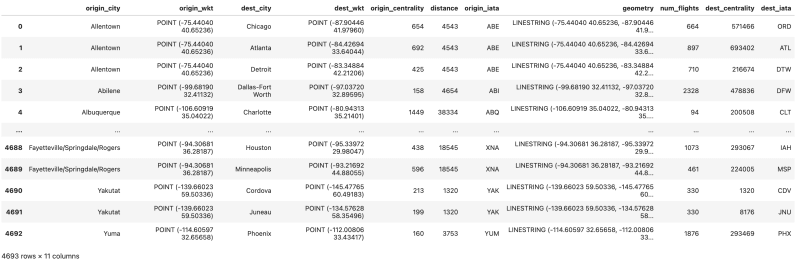
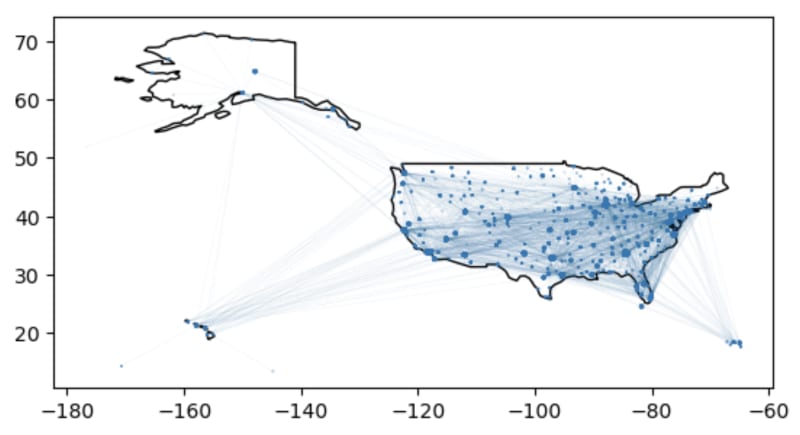
我们现在有一个地理框架,每行都是两个机场之间的飞行路线。我们可以使用中心度度量到机场节点的中心度度量来绘制机场和路线:更重要的机场应该更大。
world = geopandas.read_file(
geopandas.datasets.get_path('naturalearth_lowres')
)
ax = world[world.continent == 'North America']
.plot(color='white', edgecolor='black')
flights_gdf = flights_gdf.set_geometry("origin_wkt")
flights_gdf.plot(ax=ax, markersize='origin_centrality')
flights_gdf = flights_gdf.set_geometry("geometry")
flights_gdf.plot(ax=ax, markersize=0.1, linewidth=0.01)
使用OpenStreetMap数据
在本节中,我们将使用OSMNX Python软件包将数据从OpenStreetMap导入Neo4J。以下是我们将使用的属性图数据模型来建模波士顿的道路网络。
pip install osmnx
使用OSMNX加载道路网络
import osmnx as ox
G = ox.graph_from_place("Boston, MA, USA", network_type="drive")
fig, ax = ox.plot_graph(G)
gdf_nodes, gdf_relationships = ox.graph_to_gdfs(G)
gdf_nodes.reset_index(inplace=True)
gdf_relationships.reset_index(inplace=True)
这是我们的节点GeodataFrame。每行代表波士顿路网络中的一个交叉点:

这是我们的关系GeodataFrame。每行代表连接两个交叉点的路段。

我们将定义一个密码查询,以添加节点GeodataFrame的交点节点,并添加来自关系的路段GeodataFrame连接交叉节点。
首先,让我们创建一个约束,以确保我们没有重复的相交节点(这也将创建一个节点索引来改善导入期间的查找):
CREATE CONSTRAINT FOR (i:Intersection) REQUIRE i.osmid IS UNIQUE
我们还可以在ROAD_SEGMENT关系的osmid属性上创建一个索引,以提高进口性能:
CREATE INDEX FOR ()-[r:ROAD_SEGMENT]-() ON r.osmid

因为我们的地理frame可能很大,所以我们将它们分解为批处理,以免一次向数据库发送太多数据。
node_query = '''
UNWIND $rows AS row
WITH row WHERE row.osmid IS NOT NULL
MERGE (i:Intersection {osmid: row.osmid})
SET i.location =
point({latitude: row.y, longitude: row.x }),
i.ref = row.ref,
i.highway = row.highway,
i.street_count = toInteger(row.street_count)
RETURN COUNT(*) as total
'''
rels_query = '''
UNWIND $rows AS road
MATCH (u:Intersection {osmid: road.u})
MATCH (v:Intersection {osmid: road.v})
MERGE (u)-[r:ROAD_SEGMENT {osmid: road.osmid}]->(v)
SET r.oneway = road.oneway,
r.lanes = road.lanes,
r.ref = road.ref,
r.name = road.name,
r.highway = road.highway,
r.max_speed = road.maxspeed,
r.length = toFloat(road.length)
RETURN COUNT(*) AS total
'''
def insert_data(tx, query, rows, batch_size=1000):
total = 0
batch = 0
while batch * batch_size < len(rows):
results = tx.run(query, parameters = {
'rows':
rows[batch * batch_size: (batch + 1) * batch_size]
.to_dict('records')
}).data()
print(results)
total += results[0]['total']
batch += 1
with driver.session() as session:
session.execute_write(insert_data, node_query, gdf_nodes.drop(columns=['geometry']))
session.execute_write(insert_data, rels_query, gdf_relationships.drop(columns=['geometry']))
在这篇文章中,我们介绍了NEO4J本来支持的一些空间功能,包括点类型和相关的Cypher函数,并演示了如何完成各种空间搜索操作以及与图算法的路由。
的简短查看。