Agê Barros在Unsplashphotot上,由当今的强盗在unspahs上
介绍
我是曼谷学院2023年云计算队列。作为曼谷学院队列的旅程近端,我们一定会完成一个顶峰项目。跨云计算,移动开发和机器学习的学生共同构建一种预期的软件,可以对社会产生积极影响。我们的团队由Saddam Sinatrya Jalu Mukti,Alfatih Aditya Susanto,Arizki Putra Rahman,Dimas Ichsanul Arifin和Ramdhan Firdaus Amelia组成,以构建可扩展且具有成本效益的应用。在本文中,我们将讨论Capstone项目的背景,初始体系结构,最后一分钟的问题,最后一分钟的体系结构以及最终体系结构的执行方式。
背景
我们计划进行咖啡叶疾病检测。我们最初的想法是(当然)收集数据集,向后看过去的研究以及旨在解决问题的当前产品上所取得的成就,然后我们提出了最初的软件体系结构,该软件架构将在开发阶段成为我们的开发指南。在机器学习方面,我们将使用预训练的模型来检测叶子,而移动开发方面将利用JetPack构建移动应用程序。
初始体系结构
我们提出的/初始体系结构如下:
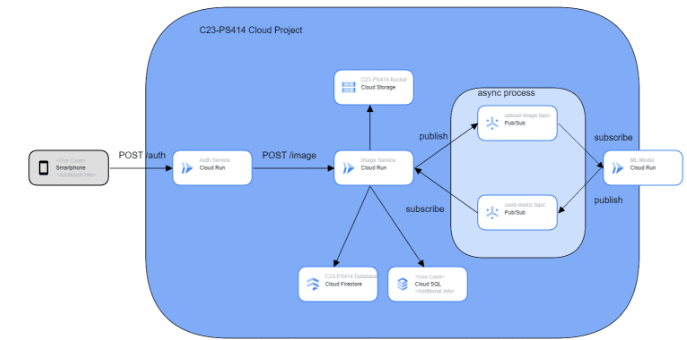
我们计划创建2个REST API,它们都在云运行中部署了两个API,都有身份验证服务和图像服务。身份验证服务是该顶峰项目的强制性要求。身份验证服务负责为身份验证目的,例如注册和登录。图像服务是负责图像数据的API,例如上传,获取和将检测数据从机器学习模型更新为数据库。
我们进行了一项有关图像分类任务使用单个数据多长时间的小型研究。完成这项工作大约需要5秒钟。由于我们不希望用户等待那么长时间,因此我们决定使用云酒吧/子来将图像服务与我们的机器学习集成在一起。 Cloud Pub/sub使图像服务能够与机器学习模型进行异步通信,因此图像服务无需等待机器学习即可完成工作。图像服务和机器学习模型都充当了出版商和订阅者,并具有各自的主题。
最后一分钟
我们计划的建筑效果不佳。由于我们的机器学习同胞不想太多触摸部署,因此当部署机器学习模型以运行云时,我们将面临问题。当时,我们仍然希望通过连接到我们的机器学习存储库来将模型部署到云中运行,但是我们对云构建配额有问题。 为什么不与工件注册表或容器注册表集成?简而言之,我们的机器学习同胞决定将其部署到App Engine。
在App Engine上部署了ML模型后,该将图像服务与ML模型集成在一起了。我最初的方法是通过传统的HTTP请求进行测试,这是成功的尝试。接下来,我想通过使用推送订阅类型来集成。
Cloud Pub/Sub,Push,Pult和BigQuery订阅中有3种订阅类型。我们将介绍此主题中的推动方案。在推送方案中,发布者应知道订户的HTTP端点,端点只能接收邮政请求。同时,在拉动方案中,订户没有提出请求,而是从主题中积极的订户拉消息流。
使用推送订阅的决定是最大程度地减少ML同胞工作,从实施拉动订阅类型(因为实施ML模型很耗时)。但是,当我碰到端点时,从ML模型/App Engine显示的记录显示。
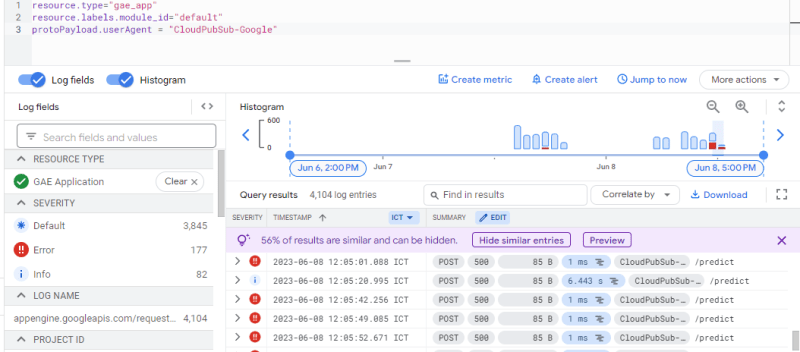
它返回500 HTTP状态代码。目前,我毫无疑问为什么ML模型拒绝请求。事实证明,当使用推送订阅传递消息时,云公共/sub将使用给定格式存储消息:
{
"message": {
"attributes": {
"key": "value"
},
"data": "SGVsbG8gQ2xvdWQgUHViL1N1YiEgSGVyZSBpcyBteSBtZXNzYWdlIQ==",
"messageId": "2070443601311540",
"message_id": "2070443601311540",
"publishTime": "2021-02-26T19:13:55.749Z",
"publish_time": "2021-02-26T19:13:55.749Z"
},
"subscription": "projects/myproject/subscriptions/mysubscription"
}
您要发送到订户的有效载荷或数据位于data中。有效载荷的值已由Cloud Pub/Sub Client解码为Base64。此时,ML模型被迫更改其数据层以匹配当前有效载荷。
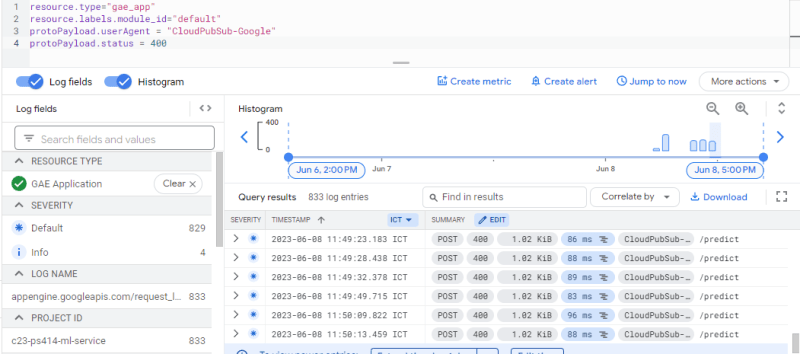
简而言之,当从图像服务到ML模型调用Cloud Pub/Sub时,一切都会顺利进行,但是当在云上部署图像服务时,ML模型通过返回400 HTTP代码来拒绝消息。
。
目前,我完全无知在不更改建议/初始体系结构的情况下应该采取什么步骤。
最后一分钟的架构
经过一几天或几天的思考,截止日期已经接近结束,我们应该更改架构,以便整合我们的服务并跟踪我们的目标,以不同步地服务预测任务。这是我们的最后一刻架构。

以前,我们将ML模型部署到App Engine,并将Cloud Pub/sub与推送订阅一起与图像服务集成。但是,这种方法不能很好地工作。
在我们的最后一刻体系结构中,我们将ML模型移至云功能。触发器是每当成功的写DAT尝试爆炸时,ML模型都会检索数据以执行预测任务。使用这种方法,一切都会顺利进行,我们的用户无需在屏幕上最多等待5秒钟! :)
建筑性能
我们可以在此体系结构上提供2个性能:成本和延迟。出于成本,我们预计该应用程序可以服务某些可以找到here的任务。这是来自ML模型的图像服务和时间执行的延迟的结果。
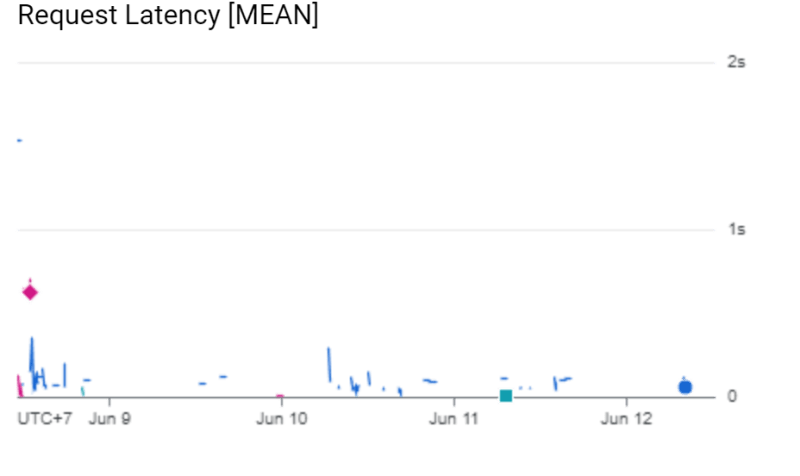
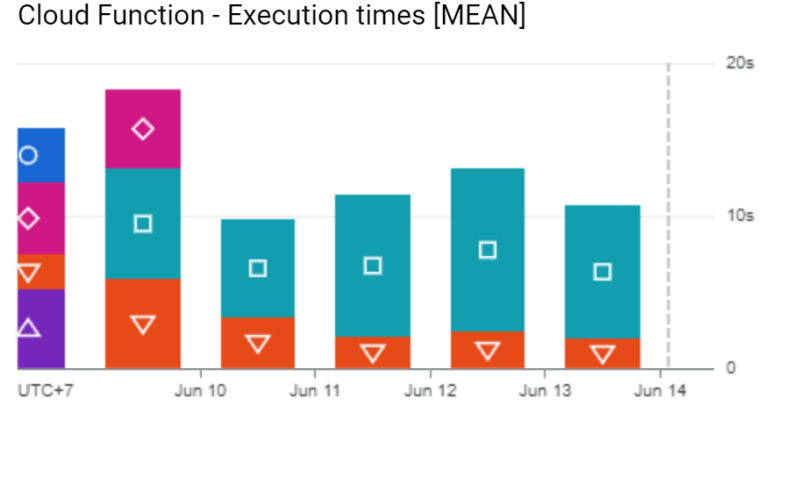
在我们的最后一分钟架构中,图像服务能够在1秒钟内提供请求。同时,在ML模型上(用蓝绿色的背景编码正方形),在服务请求时几乎没有某些尖峰。该模型应加载来自云存储的.H5文件/模型文件。负载过程可能执行一次。在没有传入请求的某些时间窗口之后,ML模型将关闭,并且每当有传入请求时,ML模型将重复该步骤。