介绍
通常,当构建应用程序时,我们将使用数据库存储数据。定义数据库中的主键很简单,困难的部分是主键的数据类型。基本上,默认的主键是bigint和自动启动,这意味着当创建新记录时,主键将增加1,2,3,依此类推。这是确保主键是唯一的最简单,最简单的方法,您可能会听到另一个选择UUIDV4作为主键。 UUIDV4(普遍唯一的标识符版本4)是一种随机生成的UUID类型,而128位的数字表示为字符串,通常由五组由连字符隔开的十六进制数字。 UUIDV4是使用随机或伪随机值生成的,每个UUIDV4在系统和时间之间被认为是唯一的,并且被指定为碰撞的概率较低。格式UUIDV4看起来像这样:
xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx
-
x代表一个随机生成 的十六进制数字(0-9,a-f)
-
4表示是UUID(UUIDV4)的版本4 -
y指定定义UUID变体的某些位 UUIDV4在网络开发中变得很流行,并使其适合在分布式系统中生成唯一标识符。
我在多个应用程序中亲自使用了UUIDV4,并且经验很棒。当您想将主要密钥曝光到最终用户(例如URL,API)而不提供有关表中数据总数的信息时,使用UUIDV4可能是一个不错的选择。例如:
{
"id": "21ba44b5-8ce3-4d07-a303-925c01cd83c3",
"name": "John Doe",
"country": "Indonesia"
}
这是使用bigint作为主键
{
"id": 201,
"name": "John Doe",
"country": "Indonesia"
}
您可以看到,使用bigint时,我们可以猜测John Doe是201est用户。但是,如果使用UUIDV4,我们无法猜到。但是,如果您不担心用户不管用户可以猜测,bigint可能是您的最佳选择。
问题
根据应用程序的性能,使用UUIDV4时没有问题。但是,作为开发人员,我总是试图找到其他选择以提高我的知识,并且将来可能会实施它。如果您不想将bigint用于主键,则UUIDV4是一个不错的选择,但是正如您已经看到结果很长的那样,很难仅通过双击即可复制UUIDV4,因为它是由Hyphen隔开的( -)因此,如果要复制整个ID,则需要手动选择。至少从我的角度来看,这可能不是一个好体验。另一个问题是UUIDV4无法分类,这意味着您需要使用不同的列来对数据进行分类。您可以在表中使用时间戳,如果使用迁移工具,则可以使用此时间戳。
- 那么,我们如何解决这些问题?
- 我们正在寻找解决方案?
- 如果我仍然想使用
bigint,但是我需要可以安全显示给最终用户的数据怎么办?
要回答这些问题,让我们转到下一节,我分享我在最近的应用程序中使用的内容。
纳米ID
介绍纳米ID。 Nano ID是一个微小的,对URL友好且独特的字符串ID生成器。 Nano ID是一个用于生成仍然具有重复ID概率的随机ID的库。但是,此概率非常小,它基于您定义的规则。这是Nano ID的功能:
- 小 - 没有依赖性,尺寸限制控制大小。
- 安全 - 它使用硬件随机生成器,可以安全地用于群集。
- 短ID - 使用比UUID(A-ZA-Z0-9_-)更大的字母。我们可以控制它。
- 便携式 - 纳米ID已移植到许多编程语言中。
来源:Nano ID
回答以前的问题,让他们一个一个
一个一个分解所以,我们如何解决这些问题?
解决方案总是有优势和缺点,但是寻找其他替代方案,即我们的要求很重要。
我们正在寻找解决方案?
我们正在寻找一个安全,小且易于控制的随机ID时,我们可以安全地向最终用户展示并改善用户体验。
如果我仍然想使用bigint,但是我需要可以安全显示给最终用户的数据
您来正确的位置,Nano ID是另一个不错的选择,您希望控制用户可以看到的内容,同时仍将使用bigint用于主键,并且当然您不必担心,因为bigint是可分类的。就像普通的int一样,但容量更大。
铁轨中的纳米ID
在这篇文章中,我们专注于试图在Rails应用程序中实现Nano ID的Rails生态系统。 Nano ID已移植到包括Ruby在内的许多编程语言中,您可以检查Ruby here的Nano ID。
我们将为客户数据构建简单的铁路应用程序,我们将查找Stripe客户页面以获取基本灵感。如果您以条纹查看客户详细信息页面,您将看到URL使用随机字符串而不是整数。这是一个示例
https://dashboard.stripe.com/test/customers/cus_MYkMUCVOIudoZg
cus_MYgMUCVOIuqoZg是为客户生成的随机独特字符串,您将在所有系统中看到此字符串。因此,我们将在Rails应用程序中实施此类策略。
请注意,哪种条纹的实现可能是不同的,因此将此帖子作为参考。
建筑应用
让我们从Run rails new rails-nanoid -T创建空导轨应用程序开始。 -T表示我们现在不需要跳过测试文件。如果您想以后可以添加。
然后,移至应用程序目录cd rails-nanoid,如果您使用git,请不要忘记进行更改。
git add .
git commit -m "Initial commit"
打开文本编辑器中的应用程序,打开Gemfile并添加nanoid gem,也可以通过运行
从终端添加它
bundle add nanoid
此命令将将nanoid添加到您的Gemfile并下载。如果您检查Gemfile,现在您将看到nanoid已安装。
gem "nanoid", "~> 2.0"
我们构建一个包括姓名和国家的客户数据。我们仍将使用bigint作为主键,并添加一个名为public_id的新列来存储Nano ID生成的随机ID。我们不会公开id,而是将public_id用于URL路由。例如,要访问客户详细信息,URL将为customers/cus_MYgMUCVOIuqoZg。
创建客户模型
我们将使用Rails脚手架生成器来创建客户页面,此命令将为我们创建模型,视图和控制器。
rails g scaffold Customer name:string country:string
添加带有string类型的public_id字段,长度为18。为什么?这是插图:

-
cus是具有3个长度3个字符 的 -
_是具有1个字符 的分离器
-
randomId后跟随机ID,长度为14个字符
public_id的前缀
因此,对于我们的public_id,总数为18个字符。我们需要指定字段的长度,以免浪费数据库中的资源。
然后打开客户迁移,就我而言,将是db/migrate/20230531051206_create_customers.rb并添加public_id字段,您可以将其命名为任何您想要的,但建议它命名为有意义且易于理解的建议。因此,客户表的完整迁移看起来像这样:
class CreateCustomers < ActiveRecord::Migration[7.0]
def change
create_table :customers do |t|
t.string :public_id, limit: 18, null: false
t.string :name
t.string :country
t.timestamps
end
add_index :customers, :public_id, unique: true
end
end
在此迁移中,我们用string类型定义public_id,限制为18,不能为null。另外,我们添加了一个新的唯一索引,以确保没有重复的public_id。
通过运行rails db:migrate运行数据库迁移。
如果您尝试创建客户,则会遇到错误,因为public_id是空的,我们已经定义了public_id在数据库中不能无效。
使用Nano ID生成随机ID
是时候将纳米ID添加到我们的代码中了,并创建一个名为public_id_generator.rb的新问题
touch app/models/concerns/public_id_generator.rb
然后添加此代码
# frozen_string_literal: true
module PublicIdGenerator
extend ActiveSupport::Concern
included do
class_attribute :public_id_prefix
self.public_id_prefix = nil
before_create :set_public_id
end
PUBLIC_ID_ALPHABET = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
PUBLIC_ID_LENGTH = 14
MAX_RETRY = 1000
class_methods do
def generate_nanoid(alphabet: PUBLIC_ID_ALPHABET, size: PUBLIC_ID_LENGTH, prefix: nil)
random_id = Nanoid.generate(size:, alphabet:)
prefix.present? ? "#{prefix}_#{random_id}" : random_id
end
end
def set_public_id
return if public_id.present?
MAX_RETRY.times do
self.public_id = generate_public_id
return unless self.class.exists?(public_id:)
end
raise "Failed to generate a unique public id after #{MAX_RETRY} attempts"
end
def generate_public_id
self.class.generate_nanoid(prefix: self.class.public_id_prefix)
end
end
说明:
- 第7-8行:定义称为
public_id_prefix的类属性,其中包括PublicIdGenerator在内的每个模型都可以根据要求指定前缀。示例cus用于客户模型 - 第10行:添加活动记录回调
before_create将public_id字段分配到纳米ID生成的随机ID。因此,只有在创建资源之前才会调用。 - 第13行:定义常数有关发电机中将使用的字符,纳米ID将采用此常数来生成随机ID。
- 第14行:定义随机ID的最大长度。
- 第15行:定义最大数字,当碰撞时应用程序尝试。在这种情况下,该应用将尝试最多1000次,直到找到唯一的随机ID。
- 第18-21行:定义使用Nano ID生成随机ID的类方法,这是使用Nano ID生成随机ID的实际代码。
- 行24-32:在第10行中,我们添加回调以调用此方法。此方法执行工作以检查是否使用了唯一ID并将其分配给
public_id字段。 - 第34-36行:调用
generate_nanoid方法并通过模型中定义的prefix。
使用publicIdgenerator
我们创建一个用于生成公共ID的模块后,现在我们将模块包括在客户模型中。另外,在这种情况下为客户定义public_id_prefix是cus。
class Customer < ApplicationRecord
+ include PublicIdGenerator
+ self.public_id_prefix = "cus"
end
因此,如果您想在更多型号中使用public_id,您要做的就是添加public_id字段并包括PublicIdGenerator模块,您可以使用。
现在让我们尝试一下,通过rails server运行该应用程序,在浏览器中打开http://localhost:3000/customers,然后尝试添加新客户。如果成功,您将被重定向到详细信息页面,请注意,URL仍在使用默认ID http://localhost:3000/customers/1。但是,如果您查看日志,您将看到public_id生成

您也可以检查第一个客户的导轨控制台
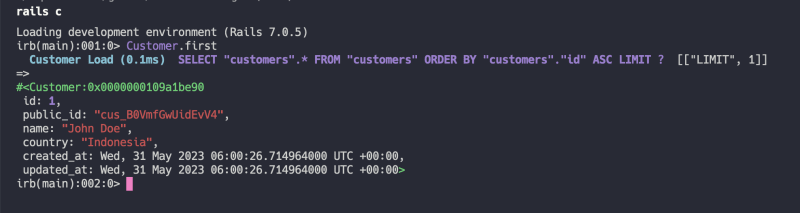
您可以看到,我们成功地生成了使用Nano ID的随机ID。我们有一个左todo,它是在URL中暴露了public_id而不是id。
公开public_id
当前,在URL中使用的是id,我们希望它改用public_id。在Rails中,更改URL中的参数ID非常常见,并且非常简单。
打开路由文件config/routes.rb并更改customers路线。
- resources :customers
+ resources :customers, param: :public_id
打开客户模型并添加覆盖to_param方法,该方法用于将其用于为该对象构造URL的操作包。在这种情况下,我们将使用public_id而不是id。
class Customer < ApplicationRecord
# code before...
def to_param
public_id
end
end
最后,打开客户控制器app/controllers/customers_controller.rb并更新以找到public_id的客户
def set_customer
- @customer = Customer.find(params[:id])
+ @customer = Customer.find_by!(public_id: params[:public_id])
end
让我们再试一次,重新启动服务器并访问客户页面。单击您创建的客户之一,然后查看URL已更改,现在使用public_id。就我而言,第一个客户将是http://localhost:3000/customers/cus_B0VmfGwUidEvV4。
恭喜!ð您在Rails应用程序中已成功实现Nano ID,使用此方法,我们仍然维护主键的常规ID,该密钥支持独特的数据并可以分类。
结论
尽管使用bigint使用默认的主键是好的,但我们必须首先注意要求。定义应用程序需要的内容,并考虑使用其他方法的利弊。
使用随机生成的ID(例如Nano ID)可能是一个不错的选择,但是,作为开发人员,我们必须了解Nano ID在应用程序中的真正作用。定义生成的ID中的字符数量也很重要,以帮助使用Nano ID具有Collision Calculator,以便我们给我们多少年以具有1%的碰撞概率。

在我们的情况下,我们有14个字符,如果我们每小时生成1000个ID,则至少需要5.7万年才能碰撞1%。
下载源代码:https://github.com/daily-newer/rails-nanoid