请求延迟是时间服务器性能的重要指标。由于其自定义持久性后端和专业管理的时间服务器基础架构,时间云可以提供可靠的低要求潜伏期。在这篇文章中,我们将为您提供一些提示,以获得较低,更可预测的请求潜伏期,并在部署Kubernetes上的自托管时间服务器时更有效地利用您的节点。
评估时间服务器部署的性能时,我们首先要查看请求潜伏您的应用程序或工人的指标,或者在与临时服务器进行通信时观察。为了使整个系统有效,可靠地运行,必须以一致,低的延迟来处理请求。低潜伏期使我们能够获得高吞吐量,并且稳定的潜伏期避免了应用程序的意外放缓,并允许我们在不触发错误警报的情况下监视性能降解。
在这篇文章中,我们将使用History服务作为我们的示例,这是负责处理呼叫以启动新工作流执行的服务,或更新工作流的状态(历史),因为它会取得进展。这些技巧都不适用于历史服务。其中大多数都不能应用于所有Temporal Server services。
意外的节流的奇怪案例
通常,Kubernetes部署将在容器上设置CPU限制,以阻止它们消耗过多的CPU,从而饿死其他容器在同一节点上运行。强制执行的方式使用了称为CPU throttling的东西。 kubernetes将您设置在容器上的CPU限制转换为每1/10秒CPU周期的限制。如果容器试图使用超过此限制,则它是油门的,这意味着其执行延迟。这可能会对容器的性能产生非平凡的影响,因为它可以增加请求延迟。对于需要CPU密集任务的请求,例如获得锁。
尤其如此。用于监视我们的缩放系列中的kubernetes簇(first post here),我们使用koude0堆栈。
与用于管理CPU节流的1/10秒相反,Prometheus系统在聚合的CPU指标之间使用15秒或更长的间隔。节流期与监视刮擦间隔之间的间隔差异很大,这意味着即使CPU使用指标在100%使用下报告了很长的路要数,也可能发生CPU节流。由于这个原因,特别重要的是监视CPU限制。
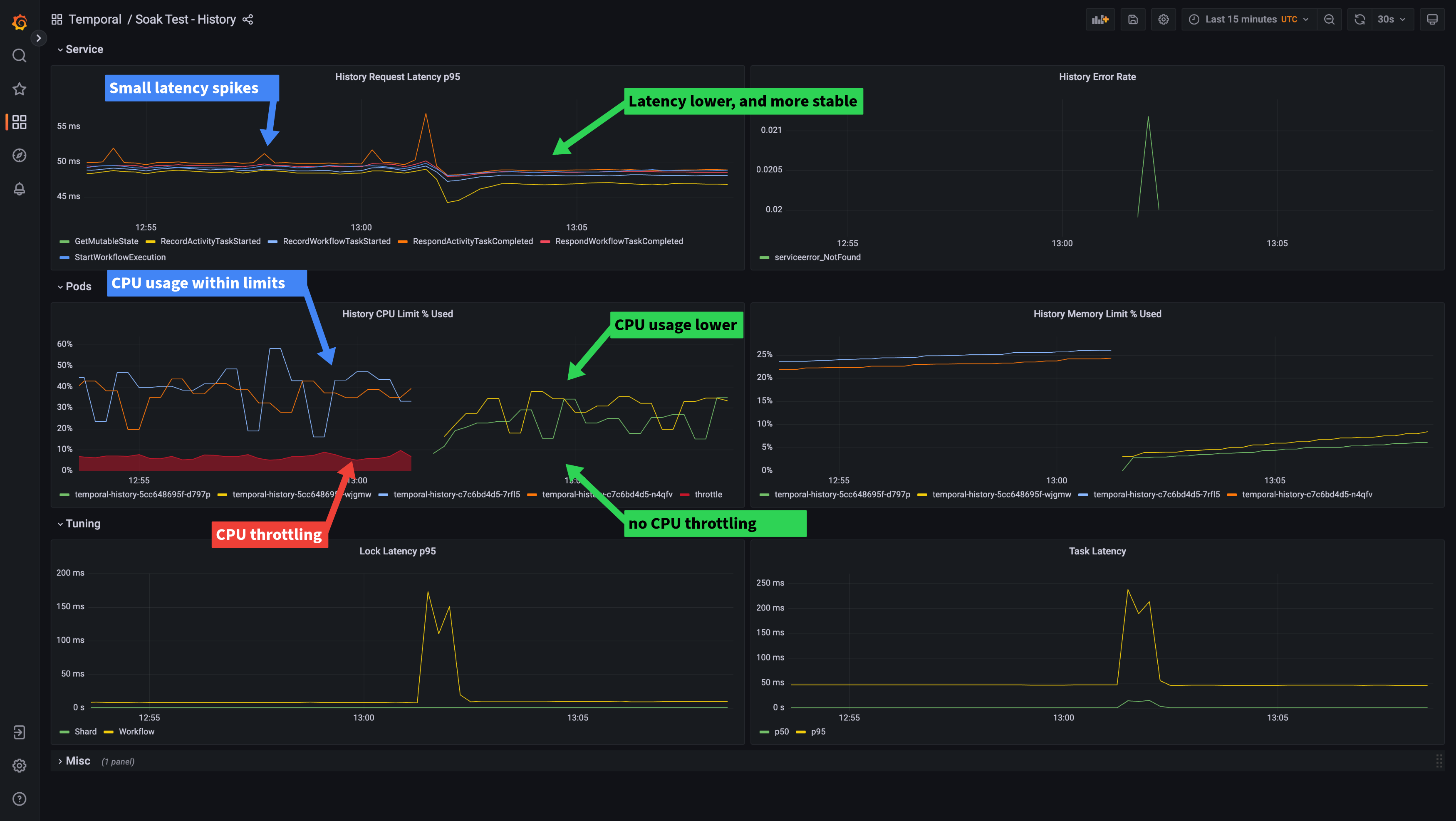
这是历史服务的示例:

我们可以从仪表板中看到,尽管历史pods cpu的用法报告低于60%,但仍处于限制。
在kube-prometheus设置中,您可以使用此Prometheus查询检查CPU节流,调整namespace和workload选择器,以适当地:
sum(
increase(container_cpu_cfs_throttled_periods_total{job="kubelet", metrics_path="/metrics/cadvisor", container!=""}[$__rate_interval])
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{namespace="temporal", workload="temporal-history"}
)
/
sum(
increase(container_cpu_cfs_periods_total{job="kubelet", metrics_path="/metrics/cadvisor", container!=""}[$__rate_interval])
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{namespace="temporal", workload="temporal-history"}
) > 0
那么,我们如何修复节流?稍后,我们将讨论为什么您可能应该完全停止使用CPU限制,但是目前,随着临时服务器的编写,我们还可以做些其他事情来改善潜伏期。
kubernetes中的gomaxprocs
GOMAXPROCS是GO的运行时设置,该设置控制允许分叉提供并发处理的多少个过程。默认情况下,GO将假定它可以为其运行的机器上的每个核心分配一个过程,从而使其具有很高的并发。
为了解决此问题,我们可以通过设置GOMAXPROCS环境变量来匹配我们的CPU限制来知道它允许使用多少个核心。注意:GOMAXPROCS必须是一个整数,因此您应该将其设置为设置在限制中的整个内核数。让我们看看当我们在部署上设置GOMAXPROCS时会发生什么:
在图形的左侧,您可以使用默认的GOMAXPROCS设置看到性能。朝右边,您可以看到将GOMAXPROCS环境变量设置为2的结果,让Go We Dew知道它只能在最多2个过程中使用。 CPU节流完全消失了,这使我们的延迟更加稳定。我们还可以看到,由于GO可以更好地决定要创建多少个过程,因此我们的CPU使用情况降低了,即使性能实际上略有改善(请求延迟降低了)。在这里,您可以在调整GomaxProcs之后查看所有时间服务中的CPU如何下降:
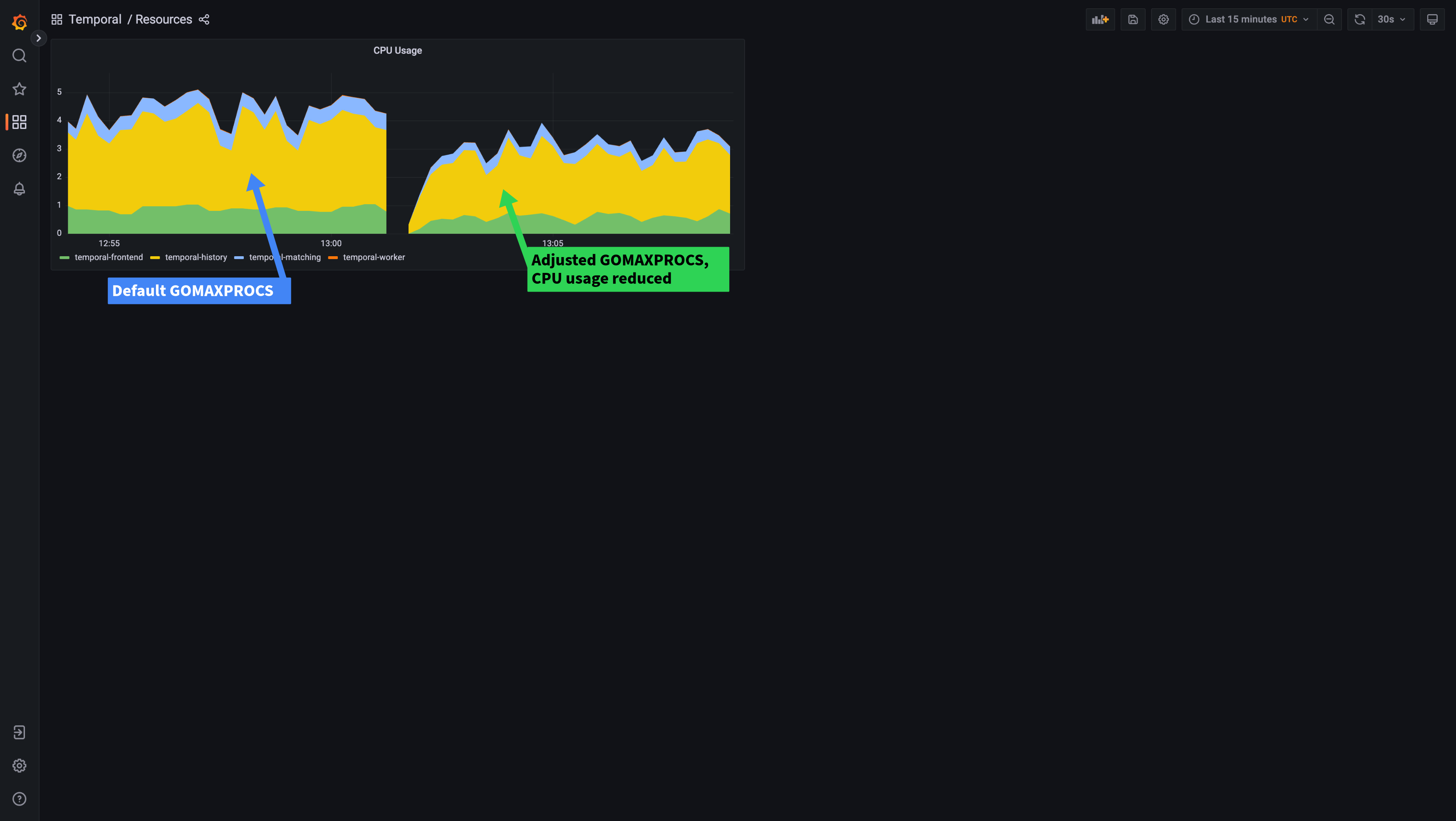
从发行版1.21.0开始,暂时性将自动设置GOMAXPROCS,以匹配kubernetes cpu限制,并且尚未设置GOMAXPROCS环境变量。在发布之前,您应该手动为时间群集部署设置GOMAXPROCS环境变量。另请注意,GOMAXPROCS不会基于CPU requests自动设置,仅设置限制。如果您不使用CPU限制,则应将GOMAXPROCS手动设置为接近(等于或稍大),而不是您的CPU请求。这允许考虑CPU请求的CPU效率做出很好的决定。
这使我们能够很好地了解我们的第二个建议
CPU限制可能弊大于利
现在,我们提高了CPU使用的效率,我将回荡sentiment of Tim Hockin(Kubernetes名望)和many others,并建议您停止完全使用CPU限制。应密切监视CPU请求,以确保您为容器请求明智的CPU,以便Kubernetes可以就其分配给节点的豆荚数量做出很好的决定。这允许具有CPU爆发的容器可利用节点上的任何备用CPU。确保监视节点CPU的使用情况以及节点上经常用尽CPU的情况告诉您,POD的破裂频率超过您的请求所允许的,您应该重新检查其CPU请求。
>如果您可以在执行某些业务需求(例如客户隔离)时完全禁用限制,请考虑将某些节点用于时间群集,并使用taints and tolerations将部署固定到这些节点上。这使您可以从临时群集部署中删除CPU限制,同时将其留在其他工作负载时。
避免在暂时升级期间重新平衡的潜伏期增加
暂时服务器的History服务自动平衡了可用历史记录范围的历史记录碎片,这就是允许时间群集水平扩展的原因。 注意:尽管我们在此处使用术语余额,但时间上不能保证每个吊舱上都有相等数量的碎片。 历史服务每次添加或删除新的历史pod时都会重新平衡碎片,这个过程可能需要一段时间才能解决。根据群集的规模,这种重新平衡可以增加请求的延迟,因为在将其重新分配到新历史或豆荚时,无法写入碎片。其效果将因每个豆荚的碎片的百分比而有所不同。您拥有的豆荚越少,添加/删除时对延迟的影响就越大。
可以通过两种方式来减轻推出期间的延迟峰值,具体取决于您拥有的历史记录数量:
如果您有10个以上的豆荚,那么最好的选择是缓慢进行推出,理想情况下一个吊舱。您可以为maxSurge和maxUnavailable使用低值,以确保吊舱缓慢旋转。使用minReadySeconds或带有InitiaDelayseconds的startupProbe,可以在添加每个POD时给时间服务器进行重新平衡。
如果您的豆荚少于10个豆荚,最好迅速旋转豆荚,以便重新平衡可以迅速安定下来。您会看到每次更改的延迟峰值,但总体影响会较低。您可以使用maxSurge和maxUnavailable设置进行实验,以允许Kubernetes同时推出更多的豆荚。每个默认值为25%,其中4个POD意味着只能一次旋转1个POD。您的里程会根据尺度和负载而有所不同,但是我们在低(4或更少)的POD计数上获得了MaxSurge/Maxunavail的50%成功。
。基于拉的监测系统(例如Prometheus)使用发现机制来寻找用于指标的豆荚。由于启动豆荚和普罗米修斯意识到它之间存在延迟,因此启动后可能不会在几个间隔中刮擦豆荚。这意味着指标可以在部署过程中报告不准确的值,直到所有新豆荚都被刮擦为止。
因此,最好确保您在评估历史记录部署策略时不会使用历史服务发出的指标。取而代之的是,诸如StartWorkflowExecution请求延迟之类的SDK指标非常适合。前端指标也可能很有用,只要前端服务没有与历史服务同时推出。
这些相同的部署策略对Matching服务也很有用,该服务平衡了跨匹配豆荚的任务队列分区。
概括
在这篇文章中,我们讨论了CPU节流,CPU限制以及在时间升级/推出期间重新平衡的效果。希望这些技巧将通过使用更少的CPU并提高自托管时间群的性能和可靠性来帮助您节省资源。
。我们希望您发现这有用,我们希望进一步讨论或回答您可能遇到的任何问题。请在Community Forum或Slack上提出任何疑问或评论。我叫罗布·荷兰(Rob Holland),如果您愿意,请随时在Temporal’s Slack上与我联系,很乐意收到您的来信。如果您喜欢这种内容,也可以在Twitter上关注我们。