简介
数字识别(NPR)在包括执法,交通管理和停车系统在内的众多领域中变得越来越重要。通过自动化提取和识别车牌编号的过程,NPR系统简化操作,增强安全性并启用有效的数据分析。在这篇博客文章中,我们将探讨一种全面的板识别方法,结合了Azure Custom Vision和Azure Computer Vision Technologies的力量。
方法
我们的数字识别方法涉及两个基本组件:Azure自定义视觉和Azure计算机视觉。 Azure自定义视觉是一种基于云的图像识别服务,使我们能够创建强大而准确的车牌检测模型。相反,由Azure认知服务提供支持的Azure计算机视觉使我们从检测到的车牌区域提取板号。
1。使用Azure自定义视觉培训车牌检测模型
我们方法的第一步是使用Azure自定义视觉训练车牌检测模型。这个过程需要收集各种标有的车牌图像的数据集,涵盖各种车牌尺寸,样式,照明条件和角度。使用Azure自定义视觉,我们可以轻松上传数据集,训练机器学习模型并进行微调以准确检测图像中的车牌。
从Azure门户网站,搜索 cognetive Services Multi Service帐户并创建一个帐户。
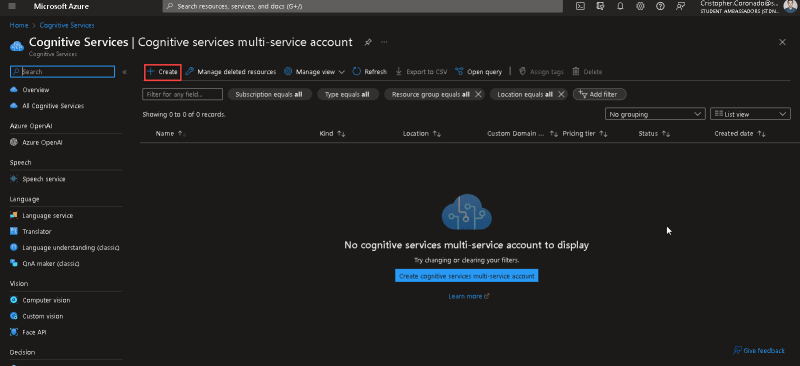
在此示例中,实例名称为carpleatedEtection。
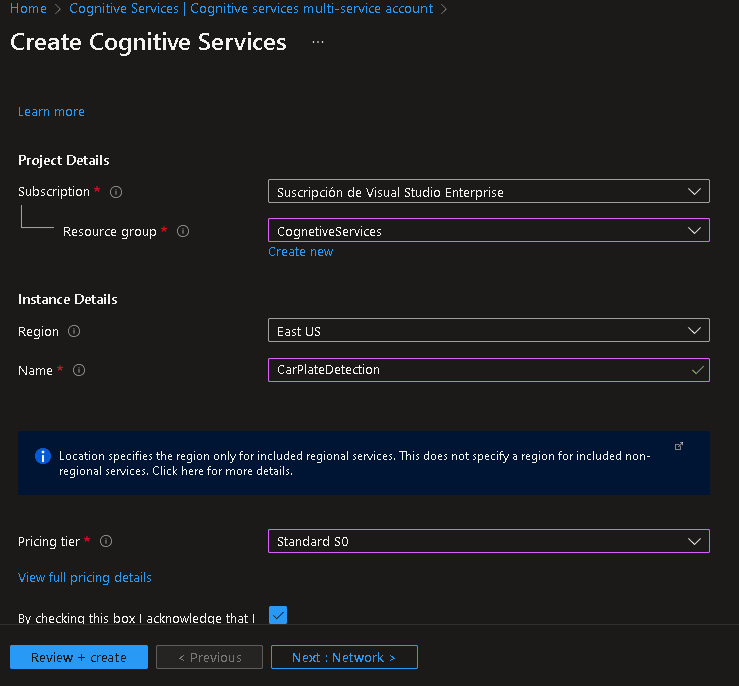
打开另一个标签,然后转到Custom Vision Portal。您必须使用较早使用的Microsoft帐户登录。单击新项目。
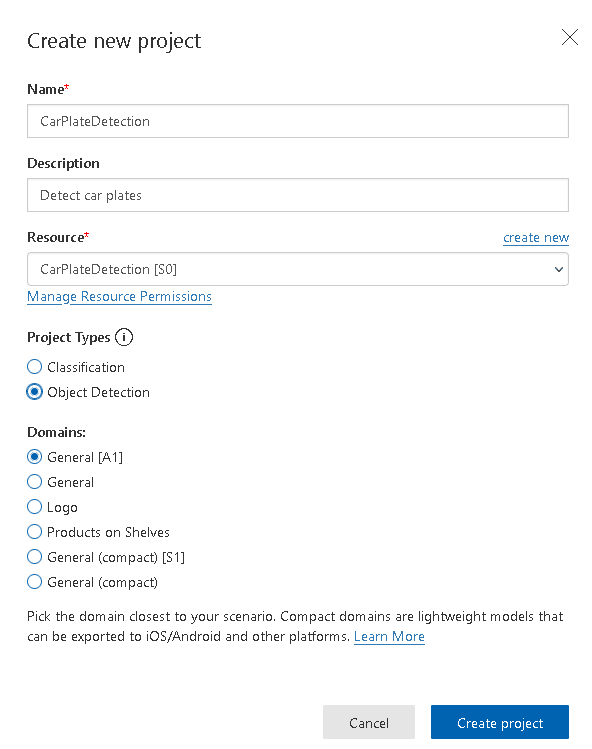
键入项目名称,描述并选择资源。单击对象检测作为项目类型,常规[A1] 作为域。
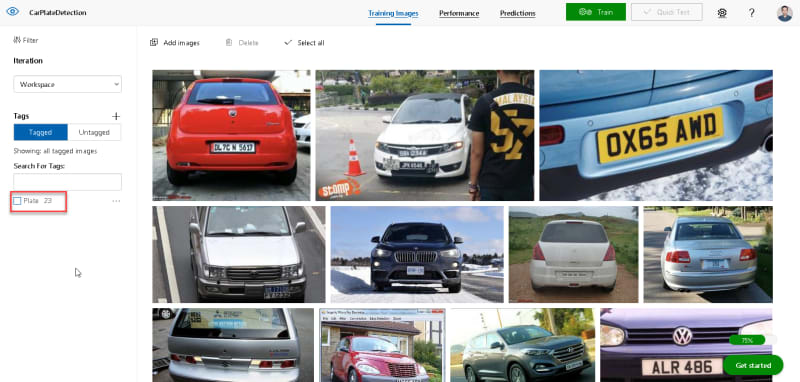
单击添加图像上传可见板号的汽车图像。搜索至少20张图像以查看此示例。
您会看到您上传的图像。

现在,单击每个人以选择想要机器学习模型检测的板号的区域。选择区域后必须输入标签名称。
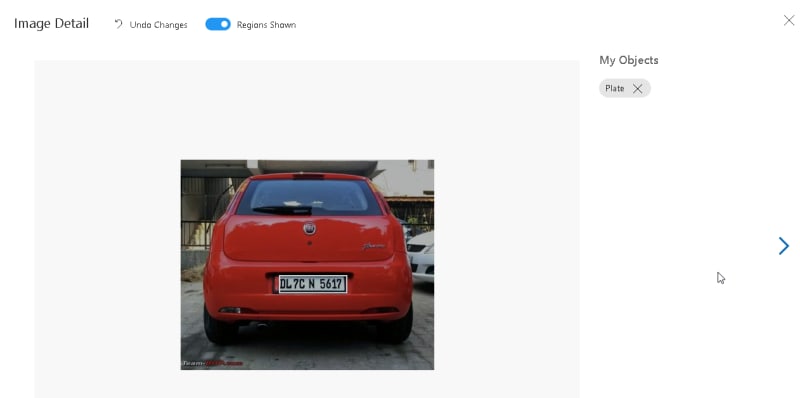
完成标记所有图像后,单击 train 。
chosse 快速培训单击 train 。

根据您标记的图像数量,这可能需要10到15分钟。
您会看到三个指标:
- 精确
- 回忆
- mAP
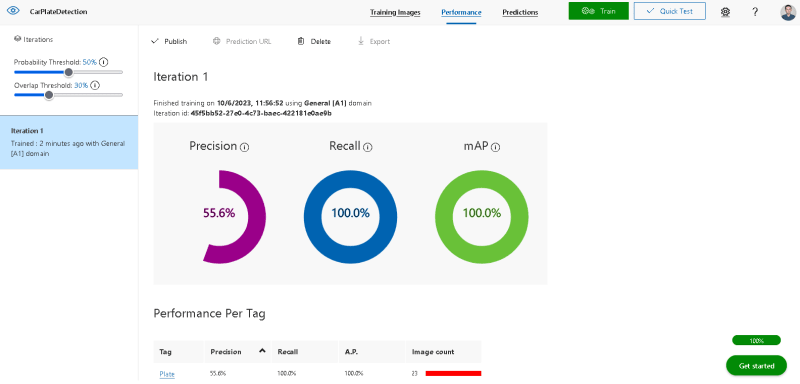
您可以测试单击快速测试的模型。上传任何汽车图像以测试模型。

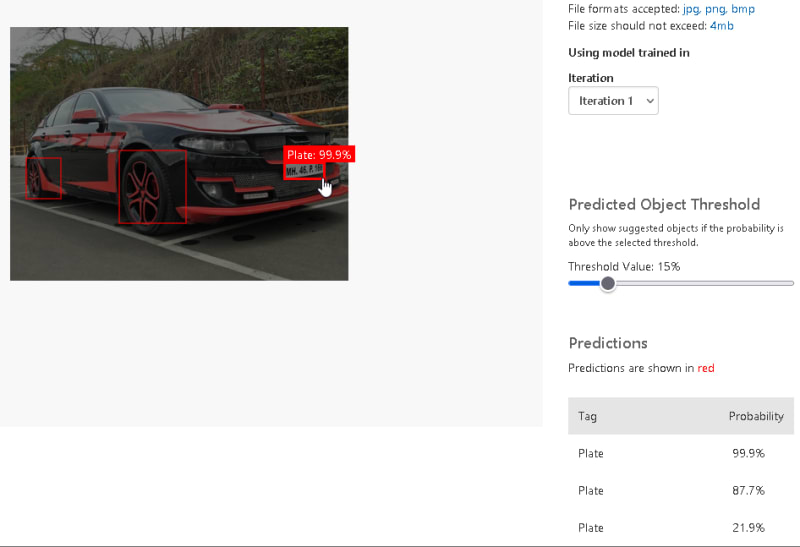
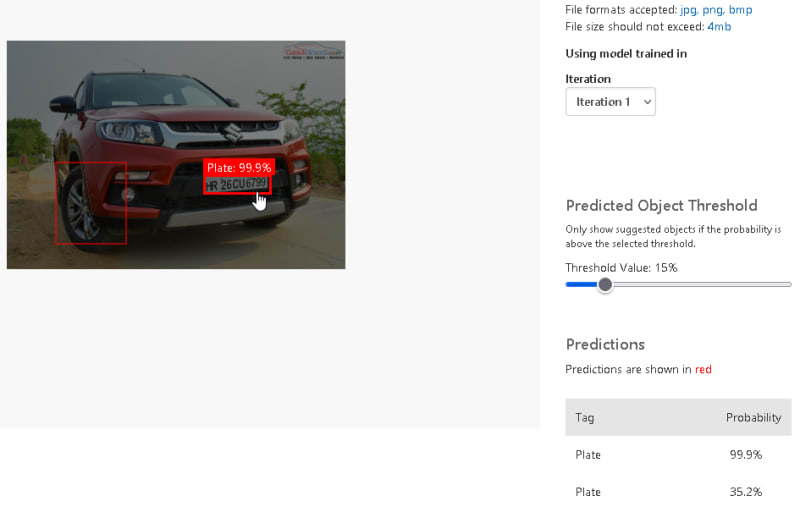
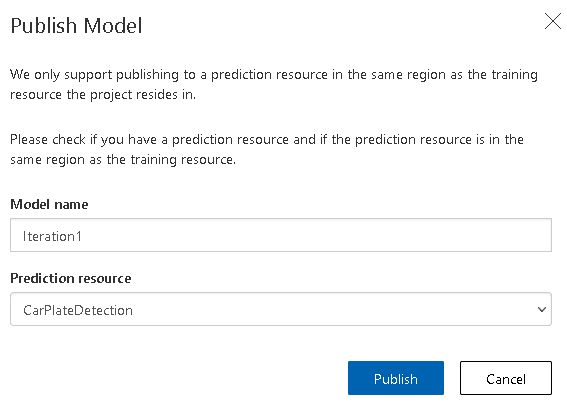
对测试结果感到满意后,单击发布并输入迭代名称,然后选择预测资源。最后,单击发布。
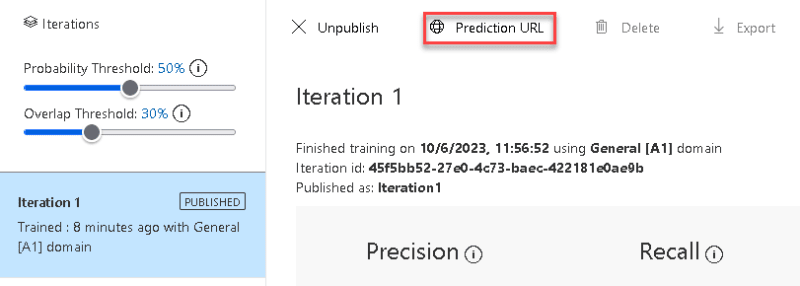
单击预测URL 查看URL和预测密钥。

2。预处理和本地化
训练车牌检测模型后,我们需要预处理输入图像以提高其质量并降低噪声。 Azure认知服务提供了强大的图像预处理功能,例如图像调整,对比度调整和降噪功能,可应用以优化图像以进行后续处理。预处理完成后,使用车牌检测模型在图像中找到车牌区域。
我们将创建一个Python笔记本,以调用Azure自定义视觉和Azure Computer Vision Apis。
import requests
import cv2
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
from numpy import asarray
查看Custom Vision Prediciton 3.0以获取更多详细信息。
custom_vision_imgurl = 'https://<resource_name>.cognitiveservices.azure.com/customvision/v3.0/Prediction/<project_id>/detect/iterations/<published_name>/image'
api_key = '<YOUR_PREDICTION_KEY>'
data = open('Cars326.png', 'rb').read()
# decode the image file as a cv2 image, useful for later to display results
img = cv2.imdecode(np.array(bytearray(data), dtype='uint8'), cv2.IMREAD_COLOR)
custom_vision_headers = {
'Content-Type': 'application/octet-stream',
'Prediction-Key': api_key
}
custom_vision_resp = requests.post(url = custom_vision_imgurl,
data = data,
headers = custom_vision_headers).json()
# inspect the top result, based on probability
hit = pd.DataFrame(custom_vision_resp['predictions']).sort_values(by='probability',ascending=False).head(1).to_dict()
print(hit)
{
"probability":{
"0":0.99115235
},
"tagId":{
"0":"c5b7e0da-7c90-4e63-bf6f-b299f1c6492a"
},
"tagName":{
"0":"Plate"
},
"boundingBox":{
"0":{
"left":0.3620827,
"top":0.6698199,
"width":0.2792757,
"height":0.08204675
}
}
}
# extract the bounding box for the detected number plate
boundingbox = list(hit['boundingBox'].values())[0]
l, t, w, h = (boundingbox['left'],
boundingbox['top'],
boundingbox['width'],
boundingbox['height'])
# extract bounding box coordinates and dimensions are scaled using image dimensions
polylines1 = np.multiply([[l,t],[l+w,t],[l+w,t+h],[l,t+h]],
[img.shape[1],img.shape[0]])
# draw polylines based on bounding box results
temp_img = cv2.polylines(img, np.int32([polylines1]),
isClosed = True, color = (255, 255, 0), thickness = 2)
# display the original image with the plate region
plt.imshow(cv2.cvtColor(temp_img, cv2.COLOR_BGR2RGB))

# crop the image to the bounding box of the plate region
crop_x = polylines1[:,0].astype('uint16')
crop_y = polylines1[:,1].astype('uint16')
img_crop = img[np.min(crop_y):np.max(crop_y),
np.min(crop_x):np.max(crop_x)]
# display the detected plate region
plt.imshow(cv2.cvtColor(img_crop, cv2.COLOR_BGR2RGB))

3。使用Azure计算机视觉提取车牌
一旦确定了车牌区域,我们就会采用Azure计算机视觉技术来提取实际的板数。此步骤涉及应用图像分割算法以隔离车牌上的字符和数字。凭借Azure Computer Vision的OCR功能,我们可以准确地从分段区域提取字母数字信息。
在调用Azure Computer Vision API之前,我们必须确保发送的图像至少具有50%的高度。
img_crop_height = img_crop.shape[0]
if img_crop_height < 50:
pil_image = Image.fromarray(img_crop)
img_crop_width = img_crop.shape[1]
difference = 50 / img_crop_height
resized_dimensions = (int(img_crop_width * difference), int(img_crop_height * difference))
pil_image_resized = pil_image.resize(resized_dimensions)
img_crop_resized = asarray(pil_image_resized)
plt.imshow(cv2.cvtColor(img_crop_resized, cv2.COLOR_BGR2RGB))
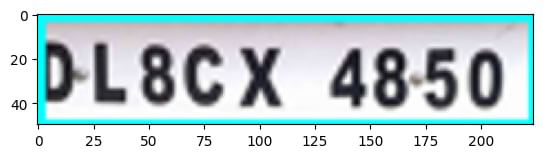
computer_vision_imgurl = 'https://<resource_name>.cognitiveservices.azure.com/computervision/imageanalysis:analyze?api-version=2023-02-01-preview&features=read'
crop_bytes = bytes(cv2.imencode('.png', img_crop_resized)[1])
# make a call to the computer_vision_imgurl
computer_vision_resp = requests.post(
url=computer_vision_imgurl,
data=crop_bytes,
headers={
'Ocp-Apim-Subscription-Key': api_key,
'Content-Type': 'application/octet-stream'}).json()
{
"readResult":{
"stringIndexType":"TextElements",
"content":"DL8CX 48.50",
"pages":[
{
"height":50.0,
"width":224.0,
"angle":0.5536,
"pageNumber":1,
"words":[
{
"content":"DL8CX",
"boundingBox":[
5.0,
12.0,
103.0,
13.0,
102.0,
43.0,
4.0,
42.0
],
"confidence":0.677,
"span":{
"offset":0,
"length":5
}
},
{
"content":"48.50",
"boundingBox":[
127.0,
14.0,
208.0,
14.0,
207.0,
44.0,
127.0,
43.0
],
"confidence":0.668,
"span":{
"offset":6,
"length":5
}
}
],
"spans":[
{
"offset":0,
"length":11
}
],
"lines":[
{
"content":"DL8CX 48.50",
"boundingBox":[
4.0,
11.0,
211.0,
13.0,
211.0,
43.0,
4.0,
41.0
],
"spans":[
{
"offset":0,
"length":11
}
]
}
]
}
],
"styles":[
],
"modelVersion":"2022-04-30"
},
"modelVersion":"2023-02-01-preview",
"metadata":{
"width":224,
"height":50
}
}
在上述响应中,我们可以看到板号是readResult.content中存在的 dl8cx 48.50 。
您可以找到源代码here。
4。后处理和分析
成功提取车牌编号后,可以应用其他后处理技术来完善结果。这些可能包括去除噪声,字符识别验证和格式调整,以确保提取的板数准确且格式正确。一旦准备就绪,可以进一步分析,存储或用于各种目的,例如数据库集成或实时监视系统。
结论
使用Azure自定义视觉和Azure Computer Vision Technologies识别数字板识别,为准确的车牌检测和提取提供了全面的解决方案。通过利用Azure基于云的服务的功能,我们可以自动化识别和提取车牌号码的过程,为交通管理,停车系统和执法部门的应用开放广泛的可能性。在此博客系列的即将到来的部分中,我们将深入研究方法的每个步骤,探索潜在的技术,并使用Azure自定义愿景和Azure计算机视觉来展示其实现。请继续关注以解锁数字识别的潜力,并使用Azure的Advanced AI功能彻底改变您的图像处理工作流程。
感谢您的阅读
非常感谢您的阅读,希望您发现这篇文章很有趣,并且在将来可能会很有用。如果您有任何需要讨论的疑问或想法,那么能够一起协作和交流知识将是一种荣幸。