上次我们查看WASM和有趣的SIMD功能。我们可以提出的一个问题是,不是一次添加2-4个值,如果有某种方法可以添加更多呢?事实证明,大多数计算机在内,包括电话和其他设备都具有专用硬件,以称为GPU。 GPU通常与图形相关联,实际上它们的设计可同时执行数百至数千个数学操作,以便计算像素颜色以进行栅格化。考虑一下您现在正在使用的屏幕。它可能至少是1080x1920像素(1080p),它比我们的矩阵大很多倍,并且在3个颜色频道上确实这样做,预计每秒至少会执行至少60次。绝对似乎是我们可以利用的东西。
家政
我试图将所有生成的输出合并到temp文件夹中(不确定名称,而是在一个地方的任何位置)。这样生成的代码不会使项目混乱,并且易于删除。不过,没有办法以正确的顺序生成所有内容,因此,如果您正在运行该项目,则可能需要对脚本进行一些反复试验。
网络上的基准测试
在我们能够使用DENO之前,它带有一个不错的基准测试工具。不幸的是,非常缺乏对服务器端框架的支持,令人沮丧的是(希望我的一些文章激发您想要这样的东西),因此我们需要使用浏览器,并在我的帖子中使用浏览器,这意味着我们猜想我们需要滚动我们自己的基准测试。
这并不难,尽管我们只需要多次运行一个函数并从运行中获取一些统计数据。要记住的一件事是因为JavaScript编译是分层,我们需要先运行很多次以“热身”。这将确保我们获得真正的快速性能(这也取决于您正在测量的内容,寒冷的开始也是一件要考虑的事情,而不是为了我们的锻炼)。热身迭代后,我们可以进行真实的迭代,然后像平均值一样进行测量。 Deno给了我们比P90,p999等的更多的东西,我们可以做到这一点,但是要使主题保持一定程度的狭窄,我们正在查看平均值。 DeNo似乎还经营了多次,直到它收敛或其他东西,我们不会做任何手动添加迭代的事情。
export function sum(values) {
return values.reduce((sum, v) => sum + v);
}
export function min(values) {
return values.reduce((min, v) => Math.min(min, v));
}
export function max(values) {
return values.reduce((max, v) => Math.max(max, v));
}
export function average(values) {
return sum(values) / values.length;
}
export async function bench(name, options, benchFn){
options.warmupIterations = options.warmupIterations ?? 500;
options.iterations = options.iterations ?? 500;
for(let i = 0; i < options.warmupIterations; i++){
await benchFn();
}
const runs = [];
for(let i = 0; i < options.iterations; i++){
const start = performance.now();
await benchFn();
runs.push(performance.now() - start);
}
return {
name,
group: options.group,
results: [
{
ok : {
origin: window.location.href,
n: options.iterations,
min: min(runs),
max: max(runs),
avg: average(runs),
p75: NaN,
p99: NaN,
p995: NaN
}
}
]
};
}
这是使用performance.now
测试生成
由于我们必须重写测试(至少在某种程度上)。我认为生成它们会更好。这是因为所有情况都加了很多代码,而且都非常公式化。我不得不修改测试的几次,我花了很长时间的拷贝性,现在是时候从中成长了(甚至不是那么困难,我应该早点做这件事...)。
let testFile = "import {\n";
const sizes = [1,2,4,8,16,32,64,128,256];
//test data (nums)
for(const size of sizes){
testFile += `\tmat${size}ANum,\n\tmat${size}BNum,\n`;
}
testFile += `} from "../data/mat-data-num.js"\n\n`
//strats
testFile += "import {\n";
const strategies = ["Loop"]; //etc
for(const strat of strategies){
testFile += `\taddMatrix${strat},\n`
}
testFile += `} from "../mat.js"\n\n`
//libs
testFile += `import { bench } from "../web/bench.js"\n\n`;
//tests
for(const strat of strategies){
for(const size of sizes){
testFile += `await bench("Add ${size}x${size} (${strat})", { group: "${size}x${size}}" }, () => {
addMatrix${strat}(mat${size}ANum, mat${size}BNum);
});\n\n`
}
}
testFile += `console.log("Complete!");\n`;
Deno.writeTextFileSync("./temp/tests.js", testFile);
这是一个简单的脚本,它为Web Runner生成测试数据。我们需要用感兴趣的策略手动填写策略。由于事物的变化很小,该文件实际上开始变得随着时间的流逝而变得非常复杂。
测试跑者
最终,从命令行快速轻松地运行测试跑步者而不手动启动服务器,导航然后尝试将粘贴物复制到控制台中可能很有用。
import { typeByExtension } from "https://deno.land/std/media_types/mod.ts";
import { extname } from "https://deno.land/std/path/mod.ts";
function getChromeExecutablePath(){
//windows
return `C:/Program Files (x86)/Google/Chrome/Application/chrome.exe`;
}
function launchChrome(url){
const command = new Deno.Command(getChromeExecutablePath(), {
args: [
url
]
});
command.outputSync();
}
const baseDir = ".";
Deno.serve(async req => {
const url = new URL(req.url);
let inputPath = url.pathname;
if (inputPath.endsWith("/")) {
inputPath += "index";
}
if (!inputPath.includes(".")) {
inputPath += ".html";
}
if (inputPath.includes("/web/index.html") && req.method === "POST"){
const body = await req.json();
await Deno.writeTextFile("./temp/web-bench.json", JSON.stringify(body, null, 4));
}
if(inputPath.includes("favicon.ico")) {
inputPath = "/web/favicon.ico";
}
const serverPath = baseDir + inputPath
const ext = extname(serverPath);
const file = await Deno.open(serverPath);
return new Response(file.readable, {
headers: {
"Content-Type": typeByExtension(ext)
}
});
});
launchChrome("http://localhost:8000/web/");
这启动了一个非常小的服务器。基本上是我的dev server code的更简单(和黑客)版本。我还创建了一个非常简单的Chrome Launcher。这是启动服务器,将Chrome启动到URL,然后运行。通过生成的测试,我们可以从控制台中提取数据。此版本实际上包含了一个帖子路由,以便页面脚本可以将基准数据发布回去,并且服务器可以将其写入文件。
它变得更加复杂...
实际上,我为代码生成和自动化事物添加了许多功能。一切都是为了从中央JSON文件中运行策略列表。这里和那里的许多很小的重构,重命名,档案改组,超出了我想描述的更多,当然还有很多无聊的工作。我认为您可能可以通过阅读源代码来弄清楚。
单位和解决方案?
DENO基准实用程序将纳秒秒用作单元。 performance.now使用毫秒,但作为浮点值。但是,我们需要小心,performance.now具有安全考虑因素(https://developer.mozilla.org/en-US/docs/Web/API/Performance/now#security_requirements),在该方面,它只能使我们粒度降低到5微秒,而仅在“隔离上下文”(浏览器实现各不相同)中。为了确保我们有孤立的上下文,我们为我们的响应添加了一些安全标头:
return new Response(file.readable, {
headers: {
"Content-Type": typeByExtension(ext),
"Cross-Origin-Opener-Policy": "same-origin",
"Cross-Origin-Embedder-Policy": "require-corp"
}
});
甚至仍然意味着要进行少于5000纳秒的测试(其中包括许多较小的纳秒)将无法代表。解决此问题的一种方法是简单地在更长的时间内采集更多样本,并平均它们。因此,更多的样本,我们只能获得平均值,也没有更多的分钟和最大。有更多聪明的方法来解决这个问题,但这可能是整个文章。
新结果
在相对术语中,结果大致相同 ,但由于我们无法获得相同水平的分辨率事物差异更大。但是至少我们知道到目前为止我们获得的数据似乎也适用于Chrome。链接到CSV,因为它们现在太大了,所以相信策略是相似的,尽管某些测量值是一个不同的命令。
网络:https://github.com/ndesmic/fast-mat/blob/v3/snapshot/bench-by-strat.web.csv
Deno:https://github.com/ndesmic/fast-mat/blob/v3/snapshot/bench-by-start.deno.csv
WebGl
好吧,现在在更有趣的东西上。我们尝试提高性能的一种方法是使用GPU。在网络上执行此操作的经典方法是WebGL。不幸的是,WebGL是在GPU确实是图形处理单元的时代设计的,因此它旨在推动像素。不过,它到底在做什么?它采用像素值(数字),并向他们应用小型算术程序以获取完成的画布。因此,我们可以做的事情将数字打包到纹理中,进行算术,然后从Framebuffer中读取结果。
不好的部分
WebGL仅支持有限数量的颜色格式。实际上,由于我们想要浮点,因此我们需要将EXT_color_buffer_float扩展到WebGL2上下文(WebGL1还有其他一些内容,我将不会谈论或实现)。 WebGL2和该扩展的组合使我们具有浮点纹理,但仅以32位精度为准。
丑陋的部分
WebGL为浏览器实现留下了很多东西,因此有很多东西不起作用,而且并不明显。主要的是您如何准确地读取浮点像素值?如果您尝试过(context.readPixels(0, 0, width, height, context.RED, context.FLOAT, buffer)),即使使用扩展名,您也会发现有关无效类型的错误。浏览器只需要实现格式和类型的单一组合,RGBA与UNSIGNED_INT,您不能保证更多。对于主要的chrome,所有铬都会给您带来的。为了制作这项工作,我们需要渲染以创建的框架,并且一旦绑定,它将允许Chrome使用另一种格式,即用FLOAT使用RED。一点都不明显。测试浏览器将允许什么的有用方法:
function glEnumToString(gl, value) {
for (let key in gl) {
if (gl[key] === value) {
return key;
}
}
return `0x${value.toString(16)}`;
}
const altFormat = glEnumToString(context, context.getParameter(context.IMPLEMENTATION_COLOR_READ_FORMAT))
const altType = glEnumToString(context, context.getParameter(context.IMPLEMENTATION_COLOR_READ_TYPE))
console.log(altFormat, altType)
如果取决于注册的FrameBuffer格式,则此值将会更改,但是如果它不报告您想要的格式,则无法正常工作。
代码
我不会为此解释太多,因为我已经写了很多。但是我们设置了一个WebGL2上下文,创建一个四Quad的场景,以便我们可以在其顶部进行像素操作。对于我们的输入,我们创建具有FLOAT类型的Gormat RED的数据纹理,因此每个像素以单个Float-32值表示。在着色器中,我们要做的就是从每个纹理中示例像素(使用紫外线将它们排列起来),将它们添加并写入帧缓冲器。然后,我们使用readPixels将其读回Float32Array。
const canvas = document.createElement("canvas");
canvas.height = 256;
canvas.width = 256;
const context = canvas.getContext("webgl2");
context.getExtension("EXT_color_buffer_float");
function createDataTexture(context, data, textureIndex = 0, width = 32, height = 32) {
context.activeTexture(context.TEXTURE0 + textureIndex);
const texture = context.createTexture();
context.bindTexture(context.TEXTURE_2D, texture);
context.texParameteri(context.TEXTURE_2D, context.TEXTURE_WRAP_S, context.CLAMP_TO_EDGE);
context.texParameteri(context.TEXTURE_2D, context.TEXTURE_WRAP_T, context.CLAMP_TO_EDGE);
context.texParameteri(context.TEXTURE_2D, context.TEXTURE_MIN_FILTER, context.NEAREST);
context.texParameteri(context.TEXTURE_2D, context.TEXTURE_MAG_FILTER, context.NEAREST);
context.texImage2D(context.TEXTURE_2D, 0, context.R32F, width, height, 0, context.RED, context.FLOAT, data);
}
function compileProgram(context){
const vertexShaderText = `#version 300 es
precision highp float;
in vec3 aPosition;
in vec2 aUV;
out vec2 uv;
void main(){
gl_Position = vec4(aPosition, 1.0);
uv = aUV;
}
`;
const vertexShader = context.createShader(context.VERTEX_SHADER);
context.shaderSource(vertexShader, vertexShaderText);
context.compileShader(vertexShader);
const fragmentShaderText = `#version 300 es
precision highp float;
uniform sampler2D samplerA;
uniform sampler2D samplerB;
in vec2 uv;
out float glColor;
void main(){
glColor = texture(samplerA, uv).r + texture(samplerB, uv).r;
}
`;
const fragmentShader = context.createShader(context.FRAGMENT_SHADER);
context.shaderSource(fragmentShader, fragmentShaderText);
context.compileShader(fragmentShader);
if (!context.getShaderParameter(vertexShader, context.COMPILE_STATUS)) {
console.error(`⚠ Failed to compile vertex shader: ${context.getShaderInfoLog(vertexShader)}`);
}
if (!context.getShaderParameter(fragmentShader, context.COMPILE_STATUS)) {
console.error(`⚠ Failed to compile fragment shader: ${context.getShaderInfoLog(fragmentShader)}`);
}
const program = context.createProgram();
context.attachShader(program, vertexShader);
context.attachShader(program, fragmentShader);
context.linkProgram(program);
context.useProgram(program);
return program;
}
function createScene(context, program){
const positions = new Float32Array([
-1.0, -1.0,
1.0, -1.0,
1.0, 1.0,
-1.0, 1.0
]);
const positionBuffer = context.createBuffer();
context.bindBuffer(context.ARRAY_BUFFER, positionBuffer);
context.bufferData(context.ARRAY_BUFFER, positions, context.STATIC_DRAW);
const positionLocation = context.getAttribLocation(program, "aPosition");
context.enableVertexAttribArray(positionLocation);
context.vertexAttribPointer(positionLocation, 2, context.FLOAT, false, 0, 0);
const uvs = new Float32Array([
0.0, 1.0,
1.0, 1.0,
1.0, 0.0,
0.0, 0.0
]);
const uvBuffer = context.createBuffer();
context.bindBuffer(context.ARRAY_BUFFER, uvBuffer);
context.bufferData(context.ARRAY_BUFFER, uvs, context.STATIC_DRAW);
const texCoordLocation = context.getAttribLocation(program, "aUV");
context.enableVertexAttribArray(texCoordLocation);
context.vertexAttribPointer(texCoordLocation, 2, context.FLOAT, false, 0, 0);
const indicies = new Uint16Array([
0, 1, 2,
0, 2, 3
]);
const indexBuffer = context.createBuffer();
context.bindBuffer(context.ELEMENT_ARRAY_BUFFER, indexBuffer);
context.bufferData(context.ELEMENT_ARRAY_BUFFER, indicies, context.STATIC_DRAW);
const samplerALocation = context.getUniformLocation(program, "samplerA");
const samplerBLocation = context.getUniformLocation(program, "samplerB");
context.uniform1i(samplerALocation, 0);
context.uniform1i(samplerBLocation, 1);
}
function createFramebuffer(context, width, height){
const framebufferTexture = context.createTexture();
context.bindTexture(context.TEXTURE_2D, framebufferTexture);
context.texImage2D(context.TEXTURE_2D, 0, context.R32F, width, height, 0, context.RED, context.FLOAT, null);
const framebuffer = context.createFramebuffer();
context.bindFramebuffer(context.FRAMEBUFFER, framebuffer);
context.framebufferTexture2D(context.FRAMEBUFFER, context.COLOR_ATTACHMENT0, context.TEXTURE_2D, framebufferTexture, 0)
}
const program = compileProgram(context);
createScene(context, program);
createFramebuffer(context, canvas.width, canvas.height);
export function addMatrixWebGl(a, b){
createDataTexture(context, a.data, 0, a.shape[0], b.shape[1]);
createDataTexture(context, b.data, 1, b.shape[0], b.shape[1]);
context.clear(context.COLOR_BUFFER_BIT | context.DEPTH_BUFFER_BIT);
context.drawElements(context.TRIANGLES, 6, context.UNSIGNED_SHORT, 0);
const result = new Float32Array(a.shape[0] * a.shape[1]);context.readPixels(0, 0, a.shape[0], a.shape[1], context.RED, context.FLOAT, result)
;
return {
shape: a.shape,
data: result
};
}
150行并不小,但这就是所需的。
WebGPU
所以webGL有点骇人听闻,但是量身定制的数字处理方式又如何呢?那是webgpu。与WebGL不同,我们可以访问Compute着色器,这与我们所做的几乎相同的事情,而没有制作纹理并代表像素的所有开销。我们可以直接运行数学操作。
代码
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
const module = device.createShaderModule({
code: `
@group(0) @binding(0)
var<storage, read> inputA: array<f32>;
@group(0) @binding(1)
var<storage, read> inputB: array<f32>;
@group(0) @binding(2)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) global_id: vec3<u32>){
output[global_id.x] = inputA[global_id.x] + inputB[global_id.x];
}
`
});
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const pipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module,
entryPoint: "main"
}
});
export async function addMatrixWebGpu(a, b){
const bufferSize = a.shape[0] * a.shape[1] * 4;
const inputA = device.createBuffer({
size: bufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST
});
const inputB = device.createBuffer({
size: bufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST
});
const output = device.createBuffer({
size: bufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
const stagingBuffer = device.createBuffer({
size: bufferSize,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: inputA
}
},
{
binding: 1,
resource: {
buffer: inputB
}
},
{
binding: 2,
resource: {
buffer: output
}
}
]
});
device.queue.writeBuffer(inputA, 0, a.data);
device.queue.writeBuffer(inputB, 0, b.data);
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(Math.ceil(bufferSize / 64));
passEncoder.end();
commandEncoder.copyBufferToBuffer(output, 0, stagingBuffer, 0, bufferSize);
const commands = commandEncoder.finish();
device.queue.submit([commands]);
await stagingBuffer.mapAsync(GPUMapMode.READ, 0, bufferSize);
const copyArrayBuffer = stagingBuffer.getMappedRange(0, bufferSize);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
return {
shape: a.shape,
data: new Float32Array(data)
}
}
一般而言,近10条线较短,密度较少。从顶部开始,我们得到适配器并请求设备,这是基本的WebGPU样板。接下来,我们创建着色器代码。由于它只是一个计算机着色器,我们只需要一个。 group(x) binding(y)告诉编译器该值来自何处,在这种情况下,它们来自绑定组,与WebGL制服基本相同,但更自由形式。在main函数中,我们添加。我们使用全局ID来表示我们所处的位置,您可以将其视为类似于片段着色器中的像素坐标。无论出于何种原因,它是3维,但我们只使用一个维度。还要注意workgroup_size,这个好奇的值决定了工作组的大小,大致翻译为并行线程的数量,但我猜是以3尺寸的数字进行建模,因为GPU可以对此做一些聪明的事情。 64或翻译时(64x1x1)是典型的值。全球ID从中衍生出来,如果您将工作组视为小3D矩形,则全局ID是工作片段的全局坐标。由于我们只给了工作组一个X维度,因此全局ID的X值从1到数组长度。这也意味着,即使对于4x4,我们也有16个元素,但同时索引了所有64个值。尽管索引16-63不存在,但这将起作用,因为它只是将夹具夹紧到最后的价值含义索引15添加了38次,但并行。继续前进,我们有bindGroupLayout,它指定了bindGroup数据的模板(和位置)。我们仅从输入中读取,因此它们可以具有GPU可能优化的readonly。它们也仅在计算阶段(我们唯一拥有的阶段)中使用,所以我们也标记了。
然后,我们定义管道,这是真正设置WebGPU与WebGL区分开来的管道。我们可以从本质上自定义阶段,而不是固定的顶点 - >片段。在这种情况下,我们只有一个简单的计算管道,带有着色器和绑定组作为输入/输出。最后,我们可以掌握功能本身。我们需要将数组绑定到GPU缓冲区,并用大小和一些属性来帮助GPU优化。然后,我们将它们连接到bindGroup。接下来的几个项目实际上将命令发送到GPU。前两个将输入数据写入我们刚刚创建的GPU缓冲区(您也可以在createBuffer Call中使用mappedAtCreation来执行此操作)。然后,我们创建一个命令编码器,该编码器将命令(二进制指令)编码到GPU。一旦设置了管道和绑定,我们实际上使用dispatchWorkgroups运行着着色器。然后,我们将输出复制到一个缓冲区,这是从WebGPU访问数据所需的奇怪事物。它基本上是将GPU缓冲区数据移至内存可以访问它的内存。最后,我们完成并提交说明。
最后,我们可以将数据从登台缓冲区中抽出。但是由于它链接到GPU,因此数据将消失,因此我们需要创建最后一个最终数组缓冲副本,以确保将其保存在JavaScript端。这是一个复杂的舞蹈。一旦我们拥有该副本,我们就可以返回它。
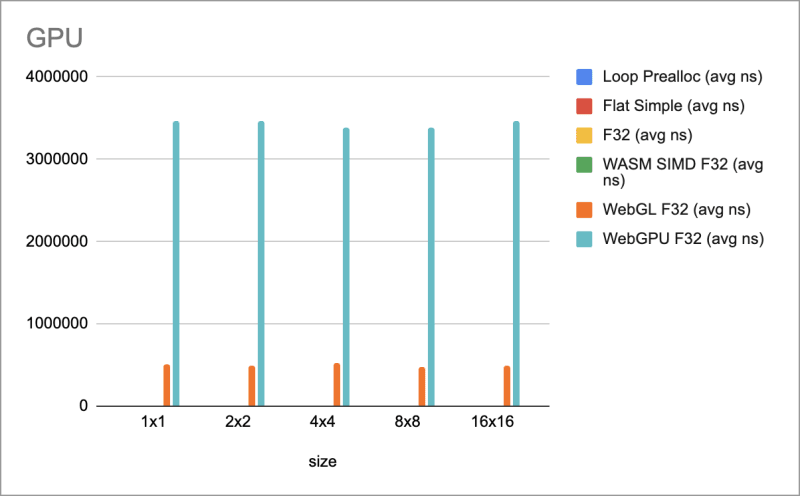
结果
结果令人失望。 WebGPU的时间比其余部分要长得多,甚至比效率低下的WebGL还要多。老实说,我尚不清楚如何更好地优化,但是有很多缓冲副本正在进行中,因此可以看一看。

使其更大
我对我们的GPU版本的失败失败了,我决定提高基质尺寸,希望他们在某个时候可能会有真正的优势,毕竟,GPU是高潜伏期,但吞吐量很高。为此,我用512和1024尺寸的矩阵构建了另一个测试。在这些测试中,我排除了展开版本,因为我们知道这将是一个可怕的想法(还有数千个线路功能会减慢测试的速度)。此外,我还抛出了预先计算的矩阵,而只是在即时生成并手动测试,从而加快了基准的速度。
秤也需要对我们的功能进行一些调整。对于WASM,我们需要再次增加页面大小:1024 * 1024 * 4 * 3 / 65,536 = 192页。对于WebGL,我们需要将帆布尺寸提高到1024x1024。 WebGPU更加困难。在使用1个尺寸64的1维工作组之前。在1024时,我们实际上超过了每个维度的允许工作项。因此,我们可以将工作组重新调整为8x8,总尺寸仍为64,但沿尺寸扩散,因此我们在任何维度上都不会超过最大值。然后,我们可以将此工作组应用于两个维度,实际上更直观...有点。然后问题是索引变得棘手,因为我们不知道矩阵的尺寸。为了解决这个问题,我们需要传递那些,这意味着将数组变成看起来像JS矩阵对象的WGSL结构。然后这使通过数据复杂化,因为我们需要编码结构。我们要做的是在每个缓冲区的开头留下8个字节,以通过2 32位INTS代表形状含义2份2份。其次,我们遇到了一致问题。我们可以通过结构的最小字节为16,对于1x1矩阵,我们只通过12。
const dataSize = (a.shape[0] * a.shape[1] * 4);
const bufferSize = dataSize + 8; //adding dimensions to front
const alignedBufferSize = Math.ceil(bufferSize / 16) * 16; //must meet 16-byte alignment
着色器代码与结构相同,并在2个维度上扩散:
struct Matrix {
size: vec2<u32>,
data: array<f32>
}
@group(0) @binding(0)
var<storage, read> inputA: Matrix;
@group(0) @binding(1)
var<storage, read> inputB: Matrix;
@group(0) @binding(2)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(8, 8)
fn main(
@builtin(global_invocation_id) global_id: vec3<u32>
){
if(global_id.x > inputA.size.x || global_id.y > inputA.size.y){
return;
}
let idx = (inputA.size.x * global_id.y) + global_id.x;
output[idx] = inputA.data[idx] + inputB.data[idx];
}
,但我们还必须小心输出缓冲区。我们只想阅读所需的字节量,而不是使用编码的维度或对齐方式。这需要一些调试才能使我变得正确,如果您开始看到大量的零,那可能是因为您没有阅读正确的位置。另外,我没有使输出Matrix结构主要是因为我必须在每次运行中分配形状,也许这实际上不是问题,但我选择将其保留在JS中(未来的台式测试I'当然)。 有关最高实现的区别,请参见底部的最终代码链接。
之后,我们可以得到“ XL”尺寸的结果:

WebGL可获得收益,但WebGPU仍然很糟糕。
结论
这里的大部分工作都是尝试获得合理的设置(我仍然没有一个好的图形设置,因为我需要改进我的标签,所以我只是将其复制到Google文档中)。制作两个GPU版本很有趣,因为API非常复杂,我不得不学习一些新知识。他们真的没有做得更好,尤其是WebGPU,真是令人失望。到目前为止,失败者确实使我认为自己做错了什么,但是在这一点上,我不确定如何解决它。总而言之,对于快速矩阵数学,一个预先关联的循环可能是最好的。
代码
https://github.com/ndesmic/fast-mat/tree/v3