在上一部分中,我们看到了Clickhouse及其功能的介绍。此外,我们了解了其不同的台式发动机家庭及其最有用的成员。在这一部分中,我将浏览Clickhouse中的特殊键和索引,这可以大大减少查询延迟和数据库加载。
应该说这些概念仅适用于默认的表引擎家族:Merge-Trees。
首要的关键
ClickHouse索引基于稀疏索引,这是传统DBMS使用的B-Tree索引的替代方案。在b-tree中,每行都是索引的,适用于定位和更新单行,也称为OLTP任务中常见的尖端。这伴随着高量插入速度以及高内存和存储消耗的成本不佳。相反,稀疏索引将数据分成多个 parts ,每个组都通过固定部分称为颗粒。 ClickHouse认为每个颗粒(一组数据)而不是每一行都有一个索引,这就是稀疏索引术语来自的地方。 Clickhouse在主键上过滤了一个查询,请查找这些颗粒,并在与内存并行加载匹配的颗粒。这给OLAP任务中常见的范围查询带来了显着的性能。此外,由于数据存储在多个文件中的列中,因此可以被压缩,从而导致存储消耗更少。
Spars-Index的性质基于LSM trees,允许您每秒插入大量数据。所有这些都带有不适合尖锐查询的成本,这不是Clickhouse的目的。
结构
在下图中,我们可以看到Clickhouse如何存储数据:

- 数据分为多个部分(ClickHouse默认或用户定义的分区密钥)
- 零件是在颗粒中拆分的,这是一个合乎逻辑的概念,Clickhouse不会将数据分为物理。相反,它可以通过标记定位颗粒。
颗粒的位置(开始和结尾)在标记文件中定义了
mrk2扩展名。 - 索引值存储在
primary.idx文件中,该文件包含每个颗粒。 - 列以
.bin文件中的压缩块存储:Wide中每个列的一个文件,以及一个以Compact格式的所有列的文件。宽或紧凑取决于Clickhouse根据列的大小确定。
现在让我们看看Clickhouse如何使用主键找到匹配行:
- Clickhouse通过二进制搜索找到了使用
primary.idx文件的匹配颗粒标记。 - 查看标记文件以查找
bin文件中颗粒的位置。 - 将匹配的颗粒从
bin文件并行加载到内存中,并使用二进制搜索在那些颗粒中寻找匹配行。
案例分析
要澄清上述流程,让我们创建一个表并将数据插入其中:
CREATE TABLE default.projects
(
`project_id` UInt32,
`name` String,
`created_date` Date
)
ENGINE = MergeTree
ORDER BY (project_id, created_date)
INSERT INTO projects
SELECT * FROM generateRandom('project_id Int32, name String, created_date Date', 10, 10, 1)
LIMIT 10000000;
首先,如果您不单独指定主键,则ClickHouse将(按顺序)将键视为主键。因此,在此表中,project_id和created_date是主要钥匙。每次您将数据插入此表时,它将首先按project_id进行排序,然后由created_date。
如果我们查看存储在硬盘驱动器上的数据结构,我们将面对:

- 我们有五个部分,其中是:
all_1_1_0。如果您对命名约定感到好奇,可以访问this link。如您所见,列存储在bin文件中,我们将标记文件与primary.idx文件一起看到。
在第一个初级键上过滤
现在让我们在project_id上过滤,这是第一个主要键,并解释其索引:

您可以看到,系统已将project_id检测为主要键,并使用它排除了1224颗颗粒!
在第二个初级钥匙上过滤
如果我们在created_date上过滤怎么办:第二个PK:
EXPLAIN indexes=1
SELECT * FROM projects WHERE created_date=today()

数据库已将created_date检测为主要键,但无法过滤任何颗粒。为什么?
因为Clickhouse仅使用二进制搜索,仅对第一个键,而generic exclusive search用于其他键,它的效率远不如前者。那么我们如何才能使其更有效?
如果我们在定义表的同时将project_id和created_date替换为排序键,则您将在过滤非第一个键的过滤方面获得更好的结果,因为create_date的基数(唯一性)比project_id:
较低。
CREATE TABLE default.projects
(
`project_id` UInt32,
`name` String,
`created_date` Date
)
ENGINE = MergeTree
ORDER BY (created_date, project_id)
EXPLAIN indexes=1
SELECT * FROM projects WHERE project_id=700
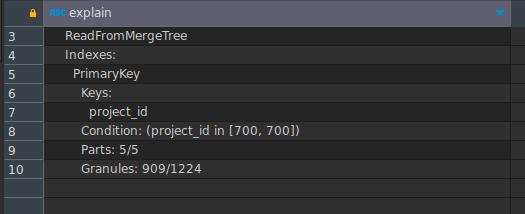
如果我们在project_id上过滤,第二个键,现在是Clickhouse,将仅使用909个颗粒而不是整个数据。
,总而言之,请始终尝试从 low 到高基数。
订单密钥
我前面提到的是,如果您不指定PRIMARY KEY选项,请clickhouse将Sort Keys视为主要密钥。但是,如果要单独设置主键,则应该是排序键的子集。结果,在排序键中指定的其他键仅用于排序目的,并且在索引中不起任何作用。
CREATE TABLE default.projects
(
`project_id` UInt32,
`name` String,
`created_date` Date
)
ENGINE = MergeTree
PRIMARY KEY (created_date, project_id)
ORDER BY (created_date, project_id, name)
在此示例中,created_date和project_id列在稀疏索引和排序中使用,而name列仅用作排序的最后一项。
如果要在查询的ORDER BY部分中使用列,请使用此选项,因为它将在运行时消除数据库分类工作。
分区密钥
分区是Clickhouse中零件的逻辑组合。默认情况下,它考虑了没有特定分区下的所有部分。要了解更多信息,请查看上一节中定义的projects表的system.parts表:
SELECT
name,
partition
FROM
system.parts
WHERE
table = 'projects';

您可以看到projects表没有特定的分区。但是,您可以使用PARTITION BY选项自定义它:
CREATE TABLE default.projects_partitioned
(
`project_id` UInt32,
`name` String,
`created_date` Date
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(created_date)
PRIMARY KEY (created_date, project_id)
ORDER BY (created_date, project_id, name)
在上表中,ClickHouse分区基于created_date列的月份:

指数
clickhouse为分区键创建 min-max 索引,并将其用作查询运行中的第一个滤波器层。让我们看看当我们通过分区密钥中存在的列过滤数据时会发生什么:
EXPLAIN indexes=1
SELECT * FROM projects_partitioned WHERE created_date='2020-02-01'

您可以看到数据库使用分区密钥的Min-Max索引选择了16个部分。
用法
Clickhouse中的分区旨在将数据操纵功能带入表格。例如,您可以删除或移动属于超过一年的分区的零件。由于Clickhouse根据存储在物理上的本月将数据拆分,因此它比未分会的表更有效。因此,可以轻松执行此类操作。
尽管ClickHouse为分区键创建了一个额外的索引,但绝不应该将其视为查询性能改进方法,因为它失去了在排序键中定义列的性能之战。因此,如果您想增强查询性能,请在排序键中考虑这些列,并使用列作为分区密钥,如果您有基于该列的数据操作的特定计划。
最后,在分布式系统中,在不同节点上分配数据的分布式系统中,请不要在Clickhouse中获得分区。如果您倾向于实现此类目的,则应使用shards and distributed tables。
跳过索引
您可能已经认识到,在排序键的最后一个项目中定义列是没有帮助的,主要是只有在没有排序键的情况下仅在该列上过滤。在这种情况下,您应该怎么做?
考虑要阅读的字典。您可以使用用字母排序的目录找到单词。这些项目是表中的排序键。您可以简单地找到一个以 w 开始的单词,但是如何找到包含与战争有关的单词的页面?

您可以在这些页面上放置标记或粘性笔记,使您下次努力减少努力。这就是Skip Index的工作方式。它可以通过创建其他索引来帮助没有某些列值的数据库过滤器颗粒。
案例分析
考虑在顺序中定义的部分中定义的projects表。 created_date和project_id被定义为主要键。现在,如果我们在name列上过滤,我们将遇到以下内容:
EXPLAIN indexes=1
SELECT * FROM projects WHERE name='hamed'

结果是预期的。现在,如果我们在上面定义跳过索引怎么办?
ALTER TABLE projects ADD INDEX name_index name TYPE bloom_filter GRANULARITY 1;
上面的命令在name列上创建了跳过索引。我使用了Bloom过滤器类型,因为列是字符串。您可以找到有关其他种类here的更多信息。
此命令仅为新数据提供索引。希望为已经插入的创建创建,您可以使用此信息:
ALTER TABLE projects MATERIALIZE INDEX name_index;
这次让我们看看查询分析:
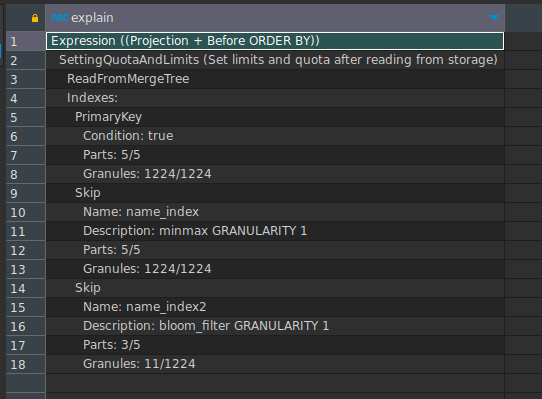
您可以看到,跳过索引极大地影响了颗粒的排除和性能。
在此示例中,跳过索引有效地执行,但在其他情况下它的性能差。这取决于您指定的列的相关性以及对索引粒度及其类型等键和设置的相关性。
结论
结论,理解和利用Clickhouse的主要密钥,订单密钥,分区密钥和SKIP索引对于优化查询性能和可扩展性至关重要。选择适当的主键,订单密钥和分区策略可以增强数据分配,提高查询执行速度并防止超载。此外,利用SKIP索引功能智能有助于最大程度地减少磁盘I/O并减少查询执行时间。通过在Clickhouse模式设计中考虑这些因素,您可以解锁Clickhouse的全部潜力,以获得高效和性能的数据解决方案。