这篇文章是我最初发表的in the Orchest blog的改编。自从我编写polar的情况下,有很多事情发生了变化,但是在编写此行时,帖子仍然具有价值。享受!
Polars是一个开源项目,可为Python和Rust提供内存数据框架。尽管它很年轻(its first commit was a mere two years ago,在Covid-19大流行中),由于其“闪电般的”表现和API的表现力,它已经获得了很多知名度。
关于Polar的最有趣的事情之一是它提供了两种操作模式:
- 急切的模式与熊猫的工作方式有些相似:立即执行操作,并且其结果可在内存中可用。但是,链中的每个操作都需要分配数据框架,这不是理想的。
- 懒惰模式,另一方面,构建了一个优化的查询计划,以尽可能多地利用并行性:Porars应用了几种简化技术,并推动计算以尽可能加速运行时间。
这些想法并不新鲜:实际上,在my blog post about Vaex中,我们涵盖了其懒惰的计算功能。但是,Polars通过提供令人愉悦使用的功能性API将它们进一步迈进了一步。
Polars的另一个秘密酱是Apache Arrow。虽然其他库将箭头用于读取镶木木文件之类的东西,但Polars与之紧密相结合:通过使用the Arrow memory format的锈蚀实现来进行柱状储存,Porars可以利用高度优化的箭头数据结构,并专注于数据操作操作。
感兴趣?阅读!
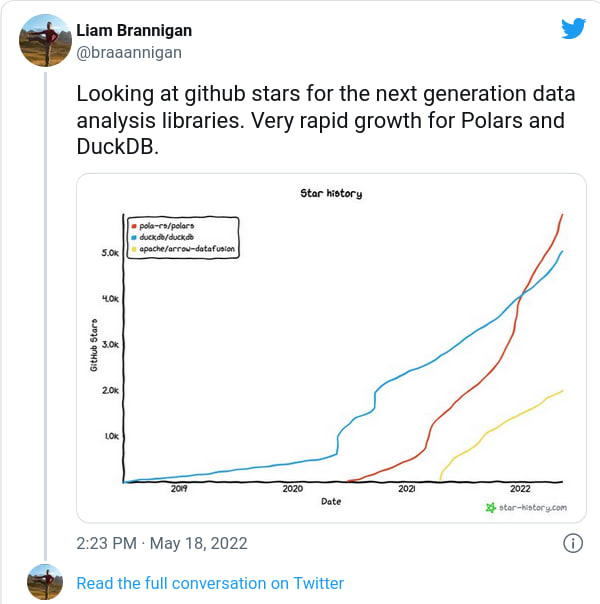
Polars的受欢迎程度正在快速增长(https://twitter.com/braaannigan/status/1526901314978029568)
Polars的第一步
在此示例中,我们将使用从kaggle获得的a sample of Stack Overflow questions and their tags。我们的通用目标是显示最高投票的Python问题。
您可以使用conda/mamba或pip安装极点:
mamba install -y "polars=0.13.37"
pip install "polars==0.13.37"
即使Porars用Rust编写,它也会在PYPI上分发预编译的二进制轮毂,因此PIP安装只能从3.6开始使用所有主要Python版本。
。让我们使用
加载问题和标记CSV文件
import polars as pl
df = pl.read_csv("/data/stacksample/Questions.csv", encoding="utf8-lossy")
tags = pl.read_csv("/data/stacksample/Tags.csv")
这两个对象的类型均为`polars.internals.frame.dataframe `,“二维数据结构,将数据表示为具有行和列的表格”(reference docs)。这两个数据范围都有数百万的行,并且一个问题需要几乎2 GB的内存:
In [7]: len(df), len(tags)
Out[7]: (1264216, 3750994)
In [8]: print(f"Estimated size: {df.estimated_size() >> 20} MiB")
Estimated size: 1865 MiB
PORARS数据范围有一些我们从大熊猫中知道的典型方法来检查数据。请注意,除了jupyter中可用的花式html表示外,调用dataframe上的打印函数还会产生整洁的ascii表示形式:
In [9]: print(df.head(3)) # No `print` needed on Jupyter
shape: (3, 7)
┌─────┬─────────────┬─────────────────┬─────────────────┬───────┬─────────────────┬────────────────┐
│ Id ┆ OwnerUserId ┆ CreationDate ┆ ClosedDate ┆ Score ┆ Title ┆ Body │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ i64 ┆ str ┆ str │
╞═════╪═════════════╪═════════════════╪═════════════════╪═══════╪═════════════════╪════════════════╡
│ 80 ┆ 26 ┆ 2008-08-01T13:5 ┆ NA ┆ 26 ┆ SQLStatement.ex ┆ <p>I've │
│ ┆ ┆ 7:07Z ┆ ┆ ┆ ecute() - ┆ written a │
│ ┆ ┆ ┆ ┆ ┆ multipl... ┆ database │
│ ┆ ┆ ┆ ┆ ┆ ┆ gener... │
├╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 90 ┆ 58 ┆ 2008-08-01T14:4 ┆ 2012-12-26T03:4 ┆ 144 ┆ Good branching ┆ <p>Are there │
│ ┆ ┆ 1:24Z ┆ 5:49Z ┆ ┆ and merging ┆ any really │
│ ┆ ┆ ┆ ┆ ┆ tutor... ┆ good tut... │
├╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 120 ┆ 83 ┆ 2008-08-01T15:5 ┆ NA ┆ 21 ┆ ASP.NET Site ┆ <p>Has anyone │
│ ┆ ┆ 0:08Z ┆ ┆ ┆ Maps ┆ got experience │
│ ┆ ┆ ┆ ┆ ┆ ┆ cre... │
└─────┴─────────────┴─────────────────┴─────────────────┴───────┴─────────────────┴────────────────┘
In [10]: print(df.describe())
shape: (5, 8)
┌──────────┬─────────────┬─────────────┬──────────────┬────────────┬───────────┬───────┬──────┐
│ describe ┆ Id ┆ OwnerUserId ┆ CreationDate ┆ ClosedDate ┆ Score ┆ Title ┆ Body │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ str ┆ str ┆ str ┆ f64 ┆ str ┆ str │
╞══════════╪═════════════╪═════════════╪══════════════╪════════════╪═══════════╪═══════╪══════╡
│ mean ┆ 2.1327e7 ┆ null ┆ null ┆ null ┆ 1.781537 ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ std ┆ 1.1514e7 ┆ null ┆ null ┆ null ┆ 13.663886 ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ min ┆ 80.0 ┆ null ┆ null ┆ null ┆ -73.0 ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ max ┆ 4.014338e7 ┆ null ┆ null ┆ null ┆ 5190.0 ┆ null ┆ null │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ median ┆ 2.1725415e7 ┆ null ┆ null ┆ null ┆ 0.0 ┆ null ┆ null │
└──────────┴─────────────┴─────────────┴──────────────┴────────────┴───────────┴───────┴──────┘
shape: (5, 2)
┌────────────┬────────┐
│ Tag ┆ counts │
│ --- ┆ --- │
│ str ┆ u32 │
╞════════════╪════════╡
│ javascript ┆ 124155 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ java ┆ 115212 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ c# ┆ 101186 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ php ┆ 98808 │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ android ┆ 90659 │
└────────────┴────────┘
遵循类似于大熊猫的术语后,Polars DataFrames包含多个类型的极性。
In [12]: df["Title"].head(5)
Out[12]: shape: (5,)
Series: 'Title' [str]
[
"SQLStatement.e...
"Good branching...
"ASP.NET Site M...
"Function for c...
"Adding scripti...
]
In [13]: df.dtypes
Out[13]: [polars.datatypes.Int64,
polars.datatypes.Utf8,
polars.datatypes.Utf8,
polars.datatypes.Utf8,
polars.datatypes.Int64,
polars.datatypes.Utf8,
polars.datatypes.Utf8]
表达式作为链式操作的表达式
Porars中的基本构建块是表达式:接收系列并将其转换为另一个系列的功能。表达start with a root,然后您可以链接更多操作:
(
pl.col("Score") # Root of the Expression (a single column)
.mean() # Returns another Expression
)
最有趣的功能是表达式不绑定到特定对象,而是它们是通用的。表达式链定义了计算,该计算是通过数据框方法实现的(充当执行上下文)。
听起来太抽象了吗?在行动中看到它:
In [20]: print(df.select(pl.col("Score").mean()))
shape: (1, 1)
┌──────────┐
│ Score │
│ --- │
│ f64 │
╞══════════╡
│ 1.781537 │
└──────────┘
df.Select 方法可以做的不仅可以选择列:它可以执行任何列的表达式。实际上,当通过此类表达式列表时,如果尺寸连贯,它可以自动广播它们,并且会并行执行它们:
In [21]: print(df.select([
...: pl.col("Id").n_unique().alias("num_unique_users"),
...: pl.col("Score").mean().alias("mean_score"),
...: pl.col("Title").str.lengths().max().alias("max_title_length"),
...: # To run the above in all text columns,
...: # you can filter by data type:
...: # pl.col(Utf8).str.lengths().max().suffix("_max_length"),
...: ]))
shape: (1, 3)
┌──────────────────┬────────────┬──────────────────┐
│ num_unique_users ┆ mean_score ┆ max_title_length │
│ --- ┆ --- ┆ --- │
│ u32 ┆ f64 ┆ u32 │
╞══════════════════╪════════════╪══════════════════╡
│ 1264216 ┆ 1.781537 ┆ 204 │
└──────────────────┴────────────┴──────────────────┘
懒惰的力量
现在是时候开始缩小分析并专注于与Python有关的问题了。请注意,Polars算法需要所有数据才能生活在内存中,因此,当使用急切的API时,您必须应用有关大数据集的常规警告。结果,由于问题数据集已经很大,因此使用标签数据进行.join操作可能会崩溃内核:
# Don't try this at home unless you have enough RAM!
# (
# df
# .join(tags, on="Id")
# .filter(pl.col("Tag").str.contains(r"(i?)python"))
# .sort("Id")
# )
但不要害怕,因为Polars具有完美的解决方案:切换到懒惰模式!通过将.lazy()和拨打.collect()的操作链加上链接,您可以将Porars优化功能利用其最大的潜力,并执行否则不可能的操作:
In [22]: q_python = (
...: df.lazy() # Notice the .lazy() call
...: # The input of a lazy join needs to be lazy
...: # We use a 'semi' join, like 'inner' but discarding extra columns
...: .join(tags.lazy(), on="Id", how="semi")
...: .filter(pl.col("Tag").str.contains(r"(i?)python"))
...: .sort("Id")
...: ).collect() # Call .collect() at the end
...: print(q_python.head(3))
shape: (3, 7)
┌───────┬─────────────┬──────────────────┬────────────┬───────┬──────────────────┬─────────────────┐
│ Id ┆ OwnerUserId ┆ CreationDate ┆ ClosedDate ┆ Score ┆ Title ┆ Body │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ i64 ┆ str ┆ str │
╞═══════╪═════════════╪══════════════════╪════════════╪═══════╪══════════════════╪═════════════════╡
│ 11060 ┆ 912 ┆ 2008-08-14T13:59 ┆ NA ┆ 18 ┆ How should I ┆ <p>This is a │
│ ┆ ┆ :21Z ┆ ┆ ┆ unit test a ┆ difficult and │
│ ┆ ┆ ┆ ┆ ┆ code-ge... ┆ open-... │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 17250 ┆ 394 ┆ 2008-08-20T00:16 ┆ NA ┆ 24 ┆ Create an ┆ <p>I'm creating │
│ ┆ ┆ :40Z ┆ ┆ ┆ encrypted ZIP ┆ an ZIP file │
│ ┆ ┆ ┆ ┆ ┆ file in ... ┆ with... │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 19030 ┆ 745 ┆ 2008-08-20T22:50 ┆ NA ┆ 2 ┆ How to check set ┆ <p>I have a │
│ ┆ ┆ :55Z ┆ ┆ ┆ of files ┆ bunch of files │
│ ┆ ┆ ┆ ┆ ┆ confor... ┆ (TV e... │
实际上,如果您的RAW CSV太大,以至于不适合RAM开始,Polars也提供了一种懒惰的方式,可以使用Scan_csv读取文件:
# We create the query plan separately
plan = (
# scan_csv returns a lazy dataframe already
pl.scan_csv("/data/stacksample/Questions.csv", encoding="utf8-lossy")
.join(tags.lazy(), on="Id", how="semi")
.filter(pl.col("Tag").str.contains(r"(i?)python"))
.sort("Score", reverse=True)
.limit(1_000)
)
top_voted_python_qs = plan.collect()
如果您对Polars如何在引擎盖下完成所有这些工作感到好奇,请注意您可以看到查询计划!

PORARS可视化查询计划(未优化)
使用列表列
请注意,在上一节中,我们进行了“半”加入以过滤这些问题,但是我们仍然没有与此类问题相关的标签列表。为了实现这一目标,我们将使用Polars最令人惊讶的令人愉悦的功能之一:其列表处理。
In [30]: tag_list_lazy = (
...: tags.lazy()
...: .groupby("Id").agg(
...: pl.col("Tag")
...: .list() # Convert to a list of strings
...: .alias("TagList")
...: )
...: )
...: print(tag_list_lazy.limit(5).collect())
shape: (5, 2)
┌──────────┬─────────────────────────────────────┐
│ Id ┆ TagList │
│ --- ┆ --- │
│ i64 ┆ list [str] │
╞══════════╪═════════════════════════════════════╡
│ 994990 ┆ ["spring"] │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 29087440 ┆ ["android", "android-intent"] │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 12093870 ┆ ["asp.net", ".net", "sqldatasour... │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 32889780 ┆ ["c", "extern", "function-declar... │
├╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 22436290 ┆ ["mysql", "sql", ... "multiple-t... │
└──────────┴─────────────────────────────────────┘
按“ ID”进行分组并将每行变成标签列表之后,是时候添加一个布尔列“包含“包含”列表的“列表中的任何标签”是否包含“ Python”的标签。为此,让我们使用_.arr.eval_上下文(也称为List context):
tag_list_extended_lazy = tag_list_lazy.with_column(
pl.col("TagList")
.arr.eval(
pl.element()
.str.contains(r"(i?)python")
.any()
).flatten().alias("ContainsPython")
)
最终连接将提供我们要寻找的答案:
top_python_questions = (
pl.scan_csv("/data/stacksample/Questions.csv", encoding="utf8-lossy")
.join(tag_list_extended_lazy, on="Id")
.filter(pl.col("ContainsPython"))
.sort("Score", reverse=True)
).limit(1_000).collect()
和结果:

在Porars中加入两个数据范围
非常整洁!
熊猫有一些差异
与VAEX发生的情况类似,Polars DataFrames没有索引。用户指南甚至说this:
不需要索引!没有它们会让事情变得更容易 - 否则说服我们!
讨论这种有争议的立场将是未来博客文章的主题。无论如何,这允许Polars到simplify indexing operations,因为字符串将始终参考列名,并且第一个轴中的数字将始终参考行数:
In [36]: print(df[0]) # First row
shape: (1, 7)
┌─────┬─────────────┬───────────────────┬────────────┬───────┬──────────────────┬──────────────────┐
│ Id ┆ OwnerUserId ┆ CreationDate ┆ ClosedDate ┆ Score ┆ Title ┆ Body │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ str ┆ i64 ┆ str ┆ str │
╞═════╪═════════════╪═══════════════════╪════════════╪═══════╪══════════════════╪══════════════════╡
│ 80 ┆ 26 ┆ 2008-08-01T13:57: ┆ NA ┆ 26 ┆ SQLStatement.exe ┆ <p>I've written │
│ ┆ ┆ 07Z ┆ ┆ ┆ cute() - ┆ a database │
│ ┆ ┆ ┆ ┆ ┆ multipl... ┆ gener... │
└─────┴─────────────┴───────────────────┴────────────┴───────┴──────────────────┴──────────────────┘
[37]: df[0, 0] # First row, first column
Out[37]: 80
In [38]: df[0, "Id"] # First row, column by name
Out[38]: 80
In [39]: df["Id"].head(5) # Column by name
Out[39]: shape: (5,)
Series: 'Id' [i64]
[
80
90
120
180
260
]
另一方面,即使用布尔面具索引在Polar中支持与Pandas用户弥合差距的一种方式,但它的使用却不建议使用 select 和 filter < /em>和"the functionality may be removed in the future"。但是,正如您在上面的示例中看到的那样,直接索引不像熊猫那样频繁。
您应该使用方面吗?
除了简短的介绍之外,Polars还提供更多,从window functions和complex aggregations到time-series processing等等。
是一个缺点,因为它是一个年轻的项目,并且正在发展迅速,您会注意到文档的某些区域有点缺乏,或者有no comprehensive release notes yet。幸运的是,Polars创建者和当前维护者Ritchie Vink快速回答堆栈溢出问题和GitHub问题,并且经常使用错误修复和新功能的发布。
另一方面,如果您正在寻找最终的解决方案,则可以使用大于RAM的数据集,Polars可能不适合您。它的懒惰处理功能可以带您很远,但是在某个时候,您必须面对一个事实,即Polars是一个内存的数据框架库,类似于Pandas。
。总结:
- 如果您愿意学习不同但功能强大的新API,如果您的数据适合内存,如果您的工作流程涉及很多列表列的操作,并且通常是否想探索Pandas的替代品,通常。
- 如果您的数据比RAM大得多,请不要使用Polars,如果您正在寻找快速迁移大型PANDAS代码库的解决方案,或者您正在寻找一个旧的,战斗测试的库。