Web自动化是公司可以在开发中测试产品的最佳方法之一,尤其是应用程序的功能,例如单击,滚动和其他操作。
本质上,Web自动化是关于模仿人类动作的,因为确保软件在所有设备的用户类型中都起作用至关重要。
在本文中,我们将学习如何使用硒作为自动化工具,以使用Python测试网站,并在不使用浏览器上使用鼠标或键盘的情况下自动化整个过程。 Selenium不单独使用Python,而是与许多其他编程语言一起工作。
硒是用什么?
Selenium允许我们浏览或使用浏览器,而无需涉及人类,并通过代码自动化过程,例如在用户输入中输入并与网站进行交互。例如,可以自动使用Selenium提交表单。 Selenium无需单击即可完成所有操作。
入门
在硒可以通过代码执行任何操作之前,我们需要包装和工具才能运行浏览器自动化并使其无缝。
安装
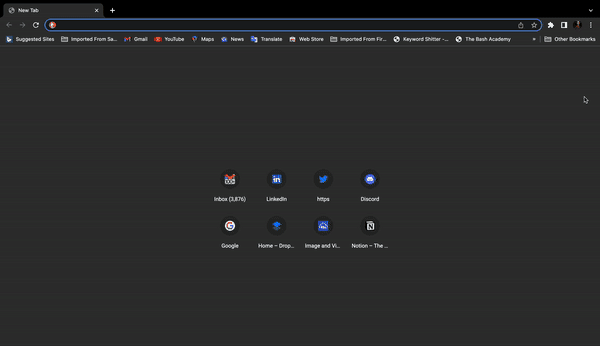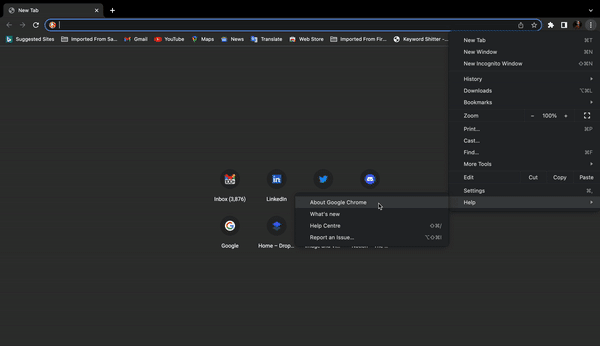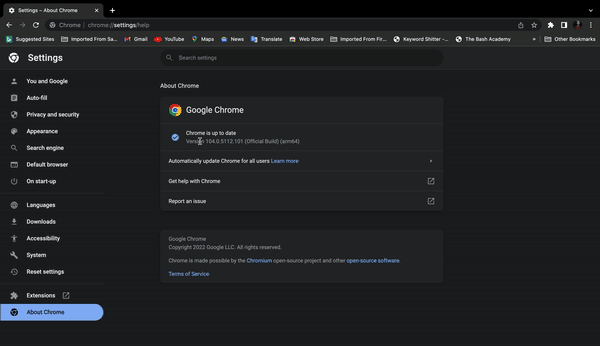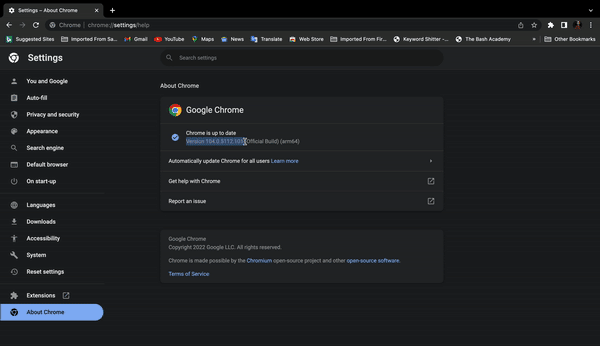
本节,我们安装了Selenium软件包和WebDriver可执行文件。首先,检查Chrome浏览器的版本,以便与Webdriver Exec文件的同等版本。
需要在我们的本地机器上安装以下内容:
Chrome浏览器。下载它here。
下载ChromeDriver的最新稳定版本。在Chromedriver网页上,检查以确认Chrome的版本与Chromedriver的版本匹配。
现在,运行此命令以在您的终端安装硒:
pip install selenium
自动化网页
开始,创建一个包含文件和下载的Chromedriver Exec文件的新文件夹。硒要求驾驶员与所选浏览器接口,在本教程中,我们使用Chrome浏览器。
必须将Chromedriver与Python文件相同的目录。
该项目的目录应该像这样:
.
├── automation.py
└── chromedriver
在此项目中使用Chromedriver的另一种方法是查找文件的路径位置并复制它,应该像这样:
MacBook用户:
/Users/<computer user name>/Desktop/chromedriver
Windows用户:
C:\Users\<computer user name\Desktop\chromdriver
Web Driver是桥接硒代码与Chrome浏览器配合使用的桥梁。 Chrome浏览器提供了桥梁。没有它,自动化将是不可能的。
接下来,让我们复制并将以下代码粘贴到automation.py文件中:
automation.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
chrome_driver_path = './chromedriver'
service = Service(chrome_drive_path)
driver = webdriver.Chrome(service=service)
url = "https://en.wikipedia.org/wiki/Main_Page"
driver.get(url)
article_count = driver.find_element(By.CSS_SELECTOR, "#articlecount a")
print(article_count.text)
drive.close()
以下发生在上面的代码段中,因为我们将使用硒浏览Wikipedia:
- 从硒模块导入函数 WebDriver
-
selenium.webdriver模块提供了所有WebDriver实现,服务对象用于处理浏览器驱动程序 - 使用其CSS 类, IDS 等等,使用
By类用于在网页文档中找到元素 - 键类模拟键盘按键的动作,例如返回/ enter , f1 , alt alt ,依此类推
- 将Chromedriver Exec文件分配给变量
- 将驱动程序的可执行路径拨打到服务对象
- 接下来是用
webdriver.Chrome()与服务参数实例化chrome浏览器 - 定义网页的 url 检查
- 使用
.get()方法将导航到URL给出的页面
在Wikipedia页面上,打开“检查元素”以访问我们将使用的元素以获取自动化页面的详细信息。
现在要找到本文计数的任务。 WebDriver为我们提供了一种方法,通过使用find_element方法来定位元素,并将By.CSS_SELECTOR用作选择器名称#articlecount a的第一个参数。

在运行Python程序之前,该脚本具有driver.close()的方法,该方法在运行测试后关闭浏览器窗口。
使用命令运行程序:
python automation.py
终端的结果应显示文章计数,该文章计数显示了网页上的确切数字, 6,545,457 。
ps:文章计数的此值不会与其价值增加相同。
模拟点击动作
从我们到目前为止所做的工作,很明显,硒可以在不使用或单击鼠标的情况下导航网站。
现在,让我们模拟一个动作,浏览器对页面上的链接的单击反应。
使用这些代码来更新automation.py:
automation.py
...
contact_us = driver.find_element(By.LINK_TEXT, "Contact us")
contact_us.click()
使用此代码段,我们正在找到链接文本的元素,与By.LINK_TEXT联系。找到元素后,将contact_us连接到使用.click()方法的动作。
再次运行命令:
python automation.py
上面的命令给出了联系我们页面的结果。
搜索网页
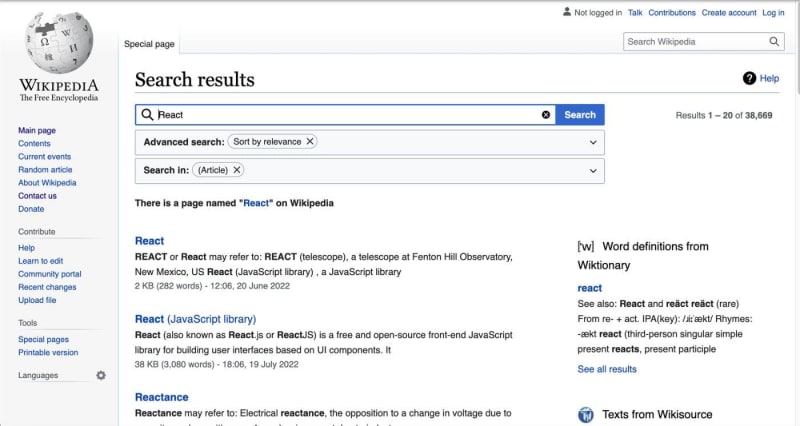
硒的用例太多。搜索网页可以通过自动化来实现,这为您提供了搜索字的结果。
仍然,在同一文件中,automation.py,使用此代码更新文件:
automation.py
search = driver.find_element(By.NAME, "search")
search.send_keys("React", Keys.ENTER)
上面的代码与以前的代码使用find_element方法与输入的名称属性,搜索。
另外,send_keys模拟按下 enter 键,搜索关键字 react 。
页面的结果应该像这样:
结论
本文是如何使用Python中的Selenium自动化网络的概述,尤其是对于想知道代码中是否存在错误以及如何修复它们的专业开发人员。
将Selenium与Python一起进行Web自动化的可能性是无穷无尽的。一些用例包括填写在线表格,申请LinkedIn作业,玩点击器游戏等等。您知道其他使用硒的用例吗?
请在下面的评论中分享您喜欢的用例。