快速矩阵数学2
上次,我们看到了多种方法来添加两个矩阵,从幼稚开始和应用简化,直到我们基本上只是在数据上形成了一个平坦的循环,该数据原来是最快的,甚至击败了打字机。在某些方面,我很遗憾地选择了这样一个简单的元素添加案例,因为它确实简化了测试平坦循环速度的方法,并且也许矩阵乘法会更好。哦,也许下一次。
由于我无法获得所有内容的庞大排列,因此存在一些缺点,因此我们将真正将字节表示作为速度来源。此外,我已经删除了128x128尺寸的测试的100x100,并添加了最终的256x256,以通过“ Big”矩阵真正挑战差异。
这实际上改变了一些策略,因为诸如简单的扁平循环之类的事情实际上比分配的循环差得多。打字阵列真的向前拉。我的猜测是因为编译器不信任分配大JS数组。
简单的打字阵列循环
我忽略了用平坦循环测试打字阵列,因为我们知道我们不需要以前拥有的结构化行柱循环。这些没有太多:
export function addMatrixFloat64Flat(a, b) {
const out = {
shape: a.shape,
data: new Float64Array(a.data.length)
};
for (let i = 0; i < a.data.length; i++) {
out.data[i] = a.data[i] + b.data[i];
}
return out;
}
| 大小 | f64(avg ns) | f64 flat(avg ns) | f32(avg ns) | f32平面(avg ns) | i32(avg ns) | i32平面(avg ns) |
|---|---|---|---|---|---|---|
| 1x1 | 353.9186842105266 | 364.64897959183673 | 348.8261688311688 | 348.4743506493506 | 350.96366013071895 | 352.73506578947377 |
| 2x2 | 356.2128476821191 | 339.31120253164556 | 362.2946000000000006 | 343.3510897435899 | 348.14629870129863 | 342.82884615384626 |
| 4x4 | 380.7755319148939 | 365.68258503401336 | 370.45848275862056 | 366.86794520547926 | 357.194466666666 | 352.2581699346405 |
| 8x8 | 477.342155172414 | 671.9946511627907 | 479.1566086956522 | 435.98608000000013 | 424.486953124997 | 408.53601503759376 |
| 16x16 | 868.6750000000002 | 777.2616 | 879.089552238806 | 738.4939743589744 | 674.5704761904763 | 662.666627906977 |
| 32x32 | 2606.12 | 2246.1545454545458 | 2592.85000000004 | 1986.65527777778 | 1733.683333333332 | 1722.907 |
| 64x64 | 9949 | 12755 | 9609.210000000001 | 8915 | 6712.57222222221 | 6916.692352941176 |
| 128x128 | 54327 | 40977 | 42542 | 33077 | 29148 | 29749 |
| 256x256 | 156667 | 148573 | 136578 | 116117 | 101296 | 105838 |
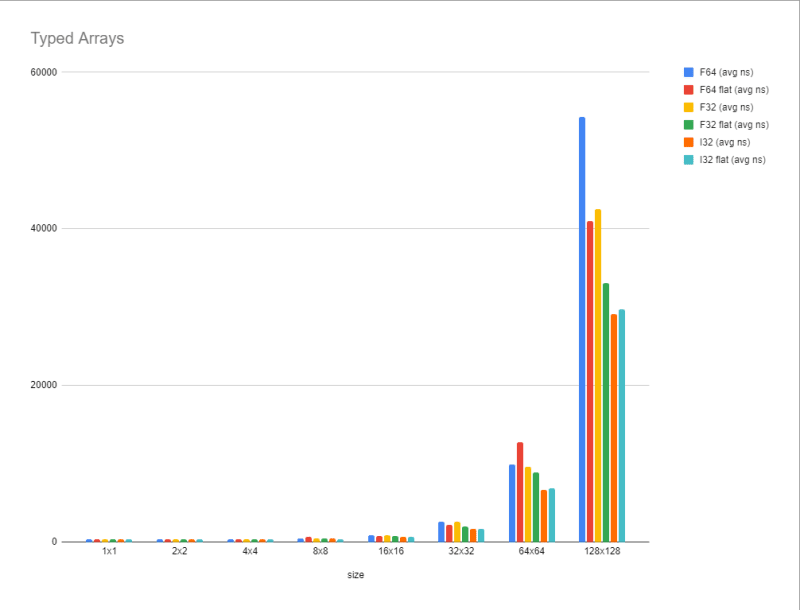
正如预期的那样
修复Float32阵列的测试
上一次我只是忽略的一个问题是,我可以为float32arrays编写测试,因为它们与64位浮子之间的精确差异。我发现JavaScript Math库中实际上有一个名为Math.fround的函数,可以进行浮点精度舍入。在生成数据时,我可以fround参数和fround,以保持32位浮子的准确性。
WASM
我们可以迅速加快事物的另一种方式是WASM。 WASM通常被称为网络的数学协会。至少,人们认为,如果您将代码移至WASM,您会看到很大的速度。然而,这比我们可能会想到的要复杂得多。呼叫WASM的开销很高,因为必须在主机和WASM模块之间移动内存,这意味着我们可能看不到很大的收益,但希望低的内部开销可能有助于加快事物的速度。
我在纯WAT(WebAssembly文本格式)中构建了一个模块。虽然通常我们不这样做,而是使用Rust或c之类的语言将其编译到WASM上,但编译的复杂性很大,怪异的东西可能会使它进入模块并更改我们的结果,并且很难优化。使其尽可能接近金属,是最好的选择。值得庆幸的是,我们正在做的事情并不复杂,可以合理地写在WAT中。
;;mat.wat
(module
(func $matrix_add_f64 (param $lhs_ptr i32) (param $rhs_ptr i32) (param $length i32) (param $out_ptr i32)
(local $i i32)
(local $offset i32)
(local.set $i (i32.const 0))
(block
(loop
(local.set $offset (i32.mul (local.get $i) (i32.const 8)))
(i32.add (local.get $out_ptr) (local.get $offset)) ;;out addr on stack
(f64.add ;;result on stack
(f64.load (i32.add (local.get $lhs_ptr) (local.get $offset)))
(f64.load (i32.add (local.get $rhs_ptr) (local.get $offset))))
(f64.store)
(local.set $i (i32.add (local.get $i) (i32.const 1)))
(br_if 1 (i32.eq (local.get $i) (local.get $length)))
(br 0)
)
)
)
(export "addMatrix" (func $matrix_add))
(memory (export "memory") 1)
)
我不会因为它不超出范围而解释这一点,但这与平面简单版本基本相同。它将数据视为一个单数阵列,并在添加时迭代。参数是指向左侧数组,右手数组,总长度以及存储输出的位置的指针。我们可以从技术上使用长度,如果我们从0开始确切知道一切都在哪里,但是我希望明确开始。
编译什么
为了实际编译,我们可以使用称为Wabt(WebAssembly二进制工具包)的工具。基本上,这是一个需要CMAKE的混乱,我无法在WSL上运行它,我不会安装MingW。取而代之的是,有一个名为WAPM的不错的工具,该工具与WebAssembly软件包一样可用,并且由于已编译为WebAssembly,因此我们可以在任何环境中运行它。实际上,只要安装了wapm,我们甚至不需要添加配置即可。我们可以运行wax wat2wasm -- wat/mat.wat -o wasm/mat.wasm。 wax就像NPM的NPX一样。如果您想知道命令,我们给出的蜡是由wasmer/wabt软件包(https://wapm.io/wasmer/wabt)定义的。另外,由于某种原因,您无法将本地路径带有./的前缀,因此wax wat2wasm -- ./wat/mat.wat无法使用哪个工具来弄清楚。无论如何,如果您想在RAW WAT文件上工作,这提供了一个不错的简单编译环境。
这将起作用,直到我们尝试使用128x128矩阵为止。它将为我们提供越野访问权限。原因是因为我们分配的内存无法符合我们需要的所有数据!但是,我们可以根据较大的输入来生长页面。
页面生长:
export function addMatrixWasmF64(a,b){
const lhsElementOffset = 0;
const rhsElementOffset = lhsElementOffset + a.data.length;
const rhsByteOffset = rhsElementOffset * 8;
const resultElementOffset = lhsElementOffset + a.data.length + b.data.length;
const resultByteOffset = resultElementOffset * 8;
const elementLength = a.data.length;
//grow memory if needed
const spaceLeftover = matInstance.exports.memory.buffer.byteLength - (a.data.length * 3 * 8)
if (spaceLeftover < 0){
const pagesNeeded = Math.ceil((a.data.length * 3 * 8) / (64 * 1024));
const pagesHave = matInstance.exports.memory.buffer.byteLength / (64 * 1024);
matInstance.exports.memory.grow(pagesNeeded - pagesHave);
}
const f64View = new Float64Array(matInstance.exports.memory.buffer);
f64View.set(a.data, lhsElementOffset);
f64View.set(b.data, rhsElementOffset);
matInstance.exports.addMatrix(0, rhsByteOffset, elementLength, resultByteOffset);
return {
shape: a.shape,
data: f64View.slice(resultElementOffset, resultElementOffset + elementLength)
};
}
这可能是我们要制作版本的方式,所以事情不会爆炸,但出于性能原因,我将忽略它并使其变得静态,我们只能进行256x256尺寸的矩阵,因此我们总共需要24页分配。
(memory (export "memory") 24)

基准结果令人失望。它预计从包装的底部开始,将数据加载到WASM模块的开销中是昂贵的。它慢慢爬上后者,但即使在128x128时,它仍然比简单的循环慢。缺乏分配有很大的不同。这意味着除非可以将更多的数据存储在WASM方面,否则WASM不太可能会带来很多好处。尽管如此,Wasm还有一个技巧。
simd
与JavaScript WASM不同,可以访问SIMD指令,该说明可用于并行化迭代,并且非常受支持。 SIMD代表单个指令多个数据。这个想法是,它可以让我们一次添加/加载等一个以上的值,只要一切都正确地排列。 WASM至少在写作时只有128位类型。它的工作方式是,我们加载一个128位值,在操作级别我们可以选择如何解释它,在我们的情况下,这将对应于2个Float-64。当我们增加$i时,我们现在以2。
修改现有代码实际上并不难。我们不是踏入8字形,而是逐步加载128位值而不是64。
(func $matrix_add_simd_f64 (param $lhs_ptr i32) (param $rhs_ptr i32) (param $length i32) (param $out_ptr i32)
(local $i i32)
(local $offset i32)
(local.set $i (i32.const 0))
(block
(loop
(local.set $offset (i32.mul (local.get $i) (i32.const 8))) ;;moving in 128-bit blocks
(i32.add (local.get $out_ptr) (local.get $offset)) ;;out addr on stack
(f64x2.add
(v128.load (i32.add (local.get $lhs_ptr) (local.get $offset)))
(v128.load (i32.add (local.get $rhs_ptr) (local.get $offset)))) ;;result on stack
(v128.store)
(local.set $i (i32.add (local.get $i) (i32.const 2)))
(br_if 1 (i32.ge_u (local.get $i) (local.get $length)))
(br 0)
)
)
)
要考虑的另一件事是,如果我们没有2个浮子要添加,会发生什么?我们需要进行一次修改,即检查分支条件要大于或平等(i32.ge),而不是等于(i32.eq),以解释可能的占领。但是,让我们考虑记忆的界限。如果我们只有一个F64,那么第二个F64将从我们的边界外加载垃圾,但是我们从不以这种方式写入(v128.store),它会撞到下一个段(假设指针没有重叠),只有最终的阵列, $out_ptr曾经写过。由于我们仅读回了想要奇数值的确切元素数量。我们也无法在分配的内存的范围之外阅读,因为它们始终由页面赋予。
我必须进行一些调试才能正确解决这个问题。一种简单的方法是导入打印值的小功能:
const { instance: matInstance } = await WebAssembly.instantiate(wasm, {
lib: {
print_int: function(num){
console.log(num);
},
print_float: function(num){
console.log(num);
},
print_brk: function(){
console.log("---")
}
}
});
(import "lib" "print_int" (func $print_int (param i32)))
(import "lib" "print_float" (func $print_float (param f32)))
(import "lib" "print_brk" (func $print_brk))
;;---stuff
(call $print_int (local.get $offset)) ;;print offset
(call $print_int (local.get $i)) ;;print $i
(call $print_brk) ;;at a visual barrier between element logs
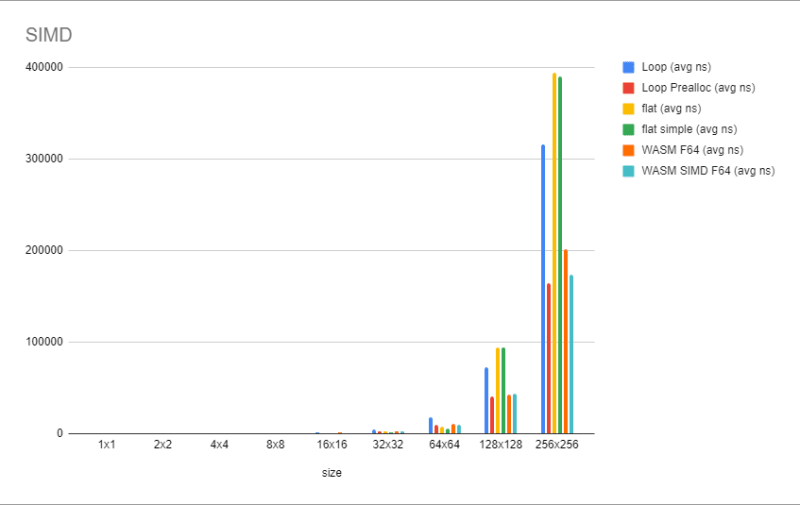
我们进一步抓住了后者。我们仍然没有在256x256击败预设的环路。所以仍然不是很可用。
Simd F32和I32
我们仍然可以弄乱精度。 32位值将使我们能够一次添加4个。我们还知道整数通常工作速度更快。
(func $matrix_add_simd_f32 (param $lhs_ptr i32) (param $rhs_ptr i32) (param $length i32) (param $out_ptr i32)
(local $i i32)
(local $offset i32)
(local.set $i (i32.const 0))
(block
(loop
(local.set $offset (i32.mul (local.get $i) (i32.const 8))) ;;moving in 128-bit blocks
(i32.add (local.get $out_ptr) (local.get $offset)) ;;out addr on stack
(f32x4.add
(v128.load (i32.add (local.get $lhs_ptr) (local.get $offset)))
(v128.load (i32.add (local.get $rhs_ptr) (local.get $offset)))) ;;result on stack
(v128.store)
(local.set $i (i32.add (local.get $i) (i32.const 2)))
(br_if 1 (i32.ge_u (local.get $i) (local.get $length)))
(br 0)
)
)
)
(func $matrix_add_simd_i32 (param $lhs_ptr i32) (param $rhs_ptr i32) (param $length i32) (param $out_ptr i32)
(local $i i32)
(local $offset i32)
(local.set $i (i32.const 0))
(block
(loop
(local.set $offset (i32.mul (local.get $i) (i32.const 8))) ;;moving in 128-bit blocks
(i32.add (local.get $out_ptr) (local.get $offset)) ;;out addr on stack
(i32x4.add
(v128.load (i32.add (local.get $lhs_ptr) (local.get $offset)))
(v128.load (i32.add (local.get $rhs_ptr) (local.get $offset)))) ;;result on stack
(v128.store)
(local.set $i (i32.add (local.get $i) (i32.const 2)))
(br_if 1 (i32.ge_u (local.get $i) (local.get $length)))
(br 0)
)
)
)
export function addMatrixWasmSimdF32(a, b) {
const lhsElementOffset = 0;
const rhsElementOffset = lhsElementOffset + a.data.length;
const rhsByteOffset = rhsElementOffset * 4;
const resultElementOffset = lhsElementOffset + a.data.length + b.data.length;
const resultByteOffset = resultElementOffset * 4;
const elementLength = a.data.length;
//grow memory if needed
// const spaceLeftover = matInstance.exports.memory.buffer.byteLength - (a.data.length * 3 * 8)
// if (spaceLeftover < 0){
// const pagesNeeded = Math.ceil((a.data.length * 3 * 8) / (64 * 1024));
// const pagesHave = matInstance.exports.memory.buffer.byteLength / (64 * 1024);
// matInstance.exports.memory.grow(pagesNeeded - pagesHave);
// }
const f32View = new Float32Array(matInstance.exports.memory.buffer);
f32View.set(a.data, lhsElementOffset);
f32View.set(b.data, rhsElementOffset);
matInstance.exports.addMatrixSimdF32(0, rhsByteOffset, elementLength, resultByteOffset);
return {
shape: a.shape,
data: f32View.slice(resultElementOffset, resultElementOffset + elementLength)
};
}
export function addMatrixWasmSimdI32(a, b) {
const lhsElementOffset = 0;
const rhsElementOffset = lhsElementOffset + a.data.length;
const rhsByteOffset = rhsElementOffset * 4;
const resultElementOffset = lhsElementOffset + a.data.length + b.data.length;
const resultByteOffset = resultElementOffset * 4;
const elementLength = a.data.length;
//grow memory if needed
// const spaceLeftover = matInstance.exports.memory.buffer.byteLength - (a.data.length * 3 * 8)
// if (spaceLeftover < 0){
// const pagesNeeded = Math.ceil((a.data.length * 3 * 8) / (64 * 1024));
// const pagesHave = matInstance.exports.memory.buffer.byteLength / (64 * 1024);
// matInstance.exports.memory.grow(pagesNeeded - pagesHave);
// }
const i32View = new Int32Array(matInstance.exports.memory.buffer);
i32View.set(a.data, lhsElementOffset);
i32View.set(b.data, rhsElementOffset);
matInstance.exports.addMatrixSimdI32(0, rhsByteOffset, elementLength, resultByteOffset);
return {
shape: a.shape,
data: i32View.slice(resultElementOffset, resultElementOffset + elementLength)
};
}
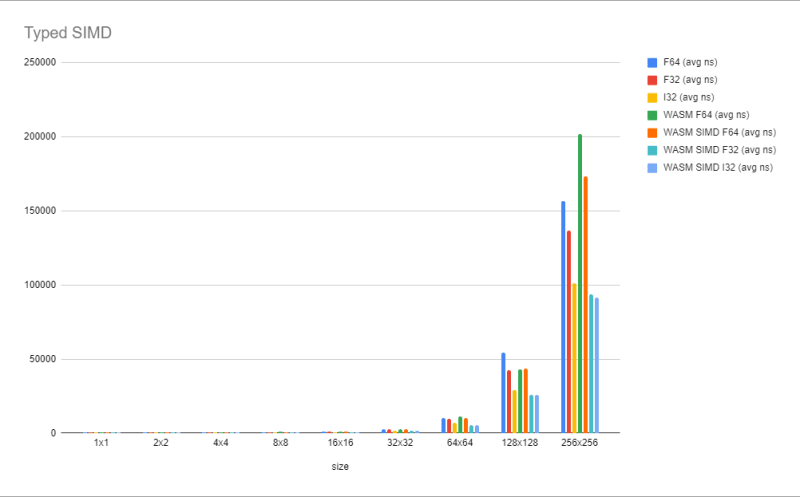
这些只是原始代码的基本替换,但具有4字节大小的元素。 WASM仍然跳到128位值,它只是将它们视为4个值,而不是2个值。对于大于32x32 i32和F32的数组几乎相等,而新的速度国王!尽管如此,与普通JavaScript(〜+10%)中的I32Array相比,这并不是一个巨大的差异,因此这是很复杂的。
结论
我们这次观察到的是,WASM本身不会产生巨大的性能增长,直到它实际克服了内存副本的开销,在我们的情况下,这是左右的64x64元素标记。在这些情况下,使用打字阵列仍然可以通过不引入这种复杂性来击败它,编译器似乎足够聪明,可以优化这些复杂性。但是,一旦我们开始向Simd介绍图片,WASM就可以超过64x64的普通JS,并随着尺寸变大而拉开。
。代码
https://github.com/ndesmic/fast-mat/tree/v1.1
数据
| 名称 | 最低 | max | avg | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| 添加1x1(func) | 61NS | 198NS | 70ns | 66ns | 168ns | 171ns |
| 添加1x1(loop) | 40ns | 141ns | 57NS | 62ns | 113ns | 119ns |
| 添加1x1(loop prealloc) | 13ns | 56ns | 15ns | 15ns | 35ns | 40ns |
| 添加1x1(展开) | 8NS | 47ns | 8NS | 8NS | 21ns | 22ns |
| 添加1x1(展开的动态) | 6ns | 37ns | 7ns | 7ns | 19NS | 21ns |
| 添加1x1(flat) | 8NS | 39ns | 9NS | 9NS | 21ns | 22ns |
| 添加1x1(平面Col Major) | 8NS | 36ns | 9NS | 9NS | 21ns | 22ns |
| 添加1x1(平面简单) | 6ns | 39ns | 7ns | 7ns | 18NS | 19NS |
| 添加1x1(平面展开) | 5NS | 28ns | 6ns | 6ns | 17ns | 18NS |
| 添加1x1(f64) | 320NS | 441NS | 354NS | 364ns | 406ns | 441NS |
| 添加1x1(f32) | 304NS | 398NS | 349NS | 360NS | 398NS | 398NS |
| 添加1x1(i32) | 302NS | 532NS | 351NS | 360NS | 469NS | 532NS |
| 添加1x1(f64 flat) | 309NS | 696ns | 365ns | 369ns | 555NS | 696ns |
| 添加1x1(F32平面) | 299ns | 544ns | 348NS | 359NS | 411NS | 544ns |
| 添加1x1(i32平面) | 305ns | 601ns | 353NS | 364ns | 585ns | 601ns |
| 添加1x1(flat func) | 56ns | 87NS | 59ns | 58NS | 79ns | 85ns |
| 添加1x1(WASM F64) | 463ns | 818NS | 500NS | 507ns | 546ns | 818NS |
| 添加1x1(WASM SIMD F64) | 461NS | 780NS | 513ns | 516ns | 751NS | 780NS |
| 添加1x1(WASM SIMD F32) | 444ns | 555NS | 491NS | 503NS | 551NS | 555NS |
| 添加1x1(WASM SIMD I32) | 441NS | 734ns | 499ns | 513ns | 644ns | 734ns |
| 添加2x2(func) | 128ns | 184ns | 136ns | 139ns | 168ns | 173ns |
| 添加2x2(loop) | 59ns | 168ns | 72NS | 76ns | 115ns | 128ns |
| 添加2x2(loop prealloc) | 23ns | 70ns | 26ns | 25ns | 44ns | 48ns |
| 添加2x2(展开) | 10ns | 34NS | 11ns | 11ns | 23ns | 24ns |
| 添加2x2(展开的动态) | 10ns | 37ns | 11ns | 11ns | 23ns | 25ns |
| 添加2x2(flat) | 13ns | 43ns | 14NS | 14NS | 26ns | 27ns |
| 添加2x2(平面Col Major) | 12ns | 39ns | 13ns | 13ns | 26ns | 27ns |
| 添加2x2(平面简单) | 8NS | 49ns | 9NS | 9NS | 21ns | 23ns |
| 添加2x2(平面外) | 7ns | 41NS | 8NS | 7ns | 19NS | 21ns |
| 添加2x2(f64) | 300NS | 457ns | 356NS | 374NS | 425ns | 457ns |
| 添加2x2(f32) | 300NS | 570NS | 362NS | 377ns | 568ns | 570NS |
| 添加2x2(i32) | 296ns | 412NS | 348NS | 367ns | 404NS | 412NS |
| 添加2x2(F64平面) | 292NS | 487ns | 339ns | 360NS | 393NS | 487ns |
| 添加2x2(f32 flat) | 295ns | 420NS | 343NS | 366ns | 414ns | 420NS |
| 添加2x2(i32 flat) | 293ns | 445ns | 343NS | 362NS | 401NS | 445ns |
| 添加2x2(flat func) | 64ns | 113ns | 67ns | 66ns | 91NS | 95NS |
| 添加2x2(WASM F64) | 434ns | 685ns | 494ns | 510ns | 678NS | 685ns |
| 添加2x2(WASM SIMD F64) | 427ns | 551NS | 480NS | 500NS | 538NS | 551NS |
| 添加2x2(WASM SIMD F32) | 434ns | 812NS | 482ns | 492NS | 768ns | 812NS |
| 添加2x2(wasm simd i32) | 433ns | 672NS | 475ns | 487ns | 622NS | 672NS |
| 添加4x4(func) | 280NS | 341NS | 293ns | 299ns | 329NS | 341NS |
| 添加4x4(loop) | 113ns | 199NS | 126ns | 130ns | 168ns | 173ns |
| 添加4x4(loop prealloc) | 58NS | 110NS | 63ns | 70ns | 91NS | 94NS |
| 添加4x4(展开) | 42ns | 115ns | 50ns | 54NS | 78ns | 97ns |
| 添加4x4(展开的动态) | 42ns | 122ns | 50ns | 55ns | 78ns | 89ns |
| 添加4x4(flat) | 28ns | 51NS | 30ns | 29ns | 43ns | 44ns |
| 添加4x4(平面Col Major) | 28ns | 66ns | 31ns | 30ns | 45ns | 50ns |
| 添加4x4(平面简单) | 17ns | 67ns | 20NS | 19NS | 36ns | 40ns |
| 添加4x4(平面展开) | 26ns | 80ns | 32ns | 31ns | 53ns | 62ns |
| 添加4x4(f64) | 338NS | 459ns | 381NS | 400NS | 455ns | 459ns |
| 添加4x4(f32) | 330ns | 451NS | 370NS | 393NS | 432ns | 451NS |
| 添加4x4(i32) | 312NS | 548NS | 357NS | 378NS | 485ns | 548NS |
| 添加4x4(F64平面) | 329NS | 560NS | 366ns | 379NS | 441NS | 560NS |
| 添加4x4(F32平面) | 317ns | 605ns | 367ns | 388NS | 568ns | 605ns |
| 添加4x4(i32平面) | 314ns | 550NS | 352NS | 372NS | 421NS | 550NS |
| 添加4x4(flat func) | 95NS | 164ns | 101NS | 107ns | 127ns | 132ns |
| 添加4x4(WASM F64) | 478ns | 610ns | 510ns | 518NS | 586ns | 610ns |
| 添加4x4(WASM SIMD F64) | 466ns | 591NS | 497ns | 512NS | 572NS | 591NS |
| 添加4x4(WASM SIMD F32) | 451NS | 548NS | 481NS | 494ns | 539ns | 548NS |
| 添加4x4(wasm simd i32) | 453ns | 546ns | 478ns | 488ns | 537ns | 546ns |
| 添加8x8(func) | 656ns | 736ns | 679NS | 685ns | 736ns | 736ns |
| 添加8x8(loop) | 326NS | 372NS | 334NS | 333ns | 366ns | 372NS |
| 添加8x8(loop prealloc) | 180ns | 259NS | 194ns | 197NS | 247ns | 254NS |
| 添加8x8(展开) | 106ns | 479NS | 125ns | 127ns | 175ns | 185ns |
| 添加8x8(展开的动态) | 105ns | 480NS | 125ns | 127ns | 190ns | 207ns |
| 添加8x8(flat) | 86ns | 165ns | 94NS | 100ns | 128ns | 149ns |
| 添加8x8(平面Col Major) | 90NS | 150ns | 98NS | 105ns | 127ns | 134ns |
| 添加8x8(平面简单) | 61NS | 124ns | 69ns | 75ns | 97ns | 104ns |
| 添加8x8(平面展开) | 65ns | 155ns | 79ns | 84NS | 131ns | 136ns |
| 添加8x8(f64) | 414ns | 725NS | 477ns | 495ns | 705NS | 725NS |
| 添加8x8(f32) | 434ns | 725NS | 479NS | 497ns | 584ns | 725NS |
| 添加8x8(i32) | 379NS | 583ns | 424ns | 441NS | 547ns | 583ns |
| 添加8x8(F64平面) | 379NS | 2317NS | 672NS | 591NS | 2317NS | 2317NS |
| 添加8x8(F32平面) | 392NS | 712NS | 436ns | 443ns | 667ns | 712NS |
| 添加8x8(i32平面) | 377ns | 544ns | 409NS | 419ns | 475ns | 544ns |
| 添加8x8(flat func) | 223ns | 298NS | 240NS | 244ns | 282NS | 283ns |
| 添加8x8(WASM F64) | 554NS | 2077ns | 802NS | 674ns | 2077ns | 2077ns |
| 添加8x8(WASM SIMD F64) | 527NS | 2345NS | 778ns | 646ns | 2345NS | 2345NS |
| 添加8x8(WASM SIMD F32) | 499ns | 875NS | 544ns | 550NS | 694ns | 875NS |
| 添加8x8(WASM SIMD I32) | 500NS | 882NS | 533ns | 537ns | 601ns | 882NS |
| 添加16x16(func) | 1703ns | 1779ns | 1743ns | 1753ns | 1779ns | 1779ns |
| 添加16x16(loop) | 1016ns | 1099ns | 1044ns | 1052NS | 1099ns | 1099ns |
| 添加16x16(loop prealloc) | 616ns | 689ns | 651NS | 660NS | 689ns | 689ns |
| 添加16x16(展开) | 400NS | 258900NS | 600NS | 500NS | 1500NS | 9600NS |
| 添加16x16(展开的动态) | 600NS | 263200NS | 793NS | 700NS | 9400NS | 9900NS |
| 添加16x16(flat) | 366ns | 609ns | 386ns | 391NS | 432ns | 609ns |
| 添加16x16(平面Col Major) | 380NS | 489ns | 403ns | 410ns | 482ns | 489ns |
| 添加16x16(平面简单) | 260NS | 348NS | 281NS | 285ns | 339ns | 348NS |
| 添加16x16(平面展开) | 326NS | 4014NS | 366ns | 347ns | 387ns | 4014NS |
| 添加16x16(f64) | 773ns | 1185ns | 869NS | 906ns | 1185ns | 1185ns |
| 添加16x16(f32) | 830ns | 996ns | 879NS | 905NS | 996ns | 996ns |
| 添加16x16(i32) | 617NS | 989NS | 675NS | 688ns | 989NS | 989NS |
| 添加16x16(F64平面) | 676ns | 1359NS | 777NS | 800NS | 1359NS | 1359NS |
| 添加16x16(F32平面) | 673NS | 1072NS | 738ns | 762NS | 1072NS | 1072NS |
| 添加16x16(i32 flat) | 617NS | 932NS | 663ns | 685ns | 932NS | 932NS |
| 添加16x16(flat func) | 773ns | 853NS | 805ns | 820NS | 853NS | 853NS |
| 添加16x16(WASM F64) | 867ns | 1649ns | 971NS | 1002NS | 1649ns | 1649ns |
| 添加16x16(WASM SIMD F64) | 783ns | 951NS | 844ns | 874NS | 951NS | 951NS |
| 添加16x16(WASM SIMD F32) | 654NS | 1054NS | 705NS | 720ns | 1054NS | 1054NS |
| 添加16x16(WASM SIMD I32) | 658NS | 792NS | 701NS | 723NS | 792NS | 792NS |
| 添加32x32(func) | 4961NS | 5128NS | 5038NS | 5052NS | 5128NS | 5128NS |
| 添加32x32(loop) | 4431NS | 4549NS | 4490NS | 4511NS | 4549NS | 4549NS |
| 添加32x32(循环prealloc) | 2411ns | 2465ns | 2431ns | 2441NS | 2465ns | 2465ns |
| 添加32x32(展开) | 72200NS | 478500NS | 79994ns | 81900NS | 125100NS | 155100NS |
| 添加32x32(展开的动态) | 72000NS | 1280700NS | 82065NS | 82600NS | 137600NS | 176500NS |
| 添加32x32(flat) | 1720ns | 2557NS | 1998ns | 2053ns | 2557NS | 2557NS |
| 添加32x32(平面Col Major) | 1772NS | 2037ns | 1827ns | 1845ns | 2037ns | 2037ns |
| 添加32x32(平面简单) | 1217ns | 1616ns | 1276ns | 1287ns | 1616ns | 1616ns |
| 添加32x32(平面展开) | 1200NS | 492700NS | 9236ns | 1900NS | 75800NS | 84200NS |
| 添加32x32(f64) | 2494ns | 2927NS | 2606ns | 2642NS | 2927NS | 2927NS |
| 添加32x32(F32) | 2499ns | 2695NS | 2593NS | 2630ns | 2695NS | 2695NS |
| 添加32x32(i32) | 1665ns | 1891ns | 1734ns | 1763ns | 1891ns | 1891ns |
| 添加32x32(F64平面) | 2129NS | 2429ns | 2246ns | 2281NS | 2429ns | 2429ns |
| 添加32x32(F32平面) | 1917ns | 2107NS | 1987ns | 2015NS | 2107NS | 2107NS |
| 添加32x32(i32平面) | 1650ns | 1853ns | 1723ns | 1735ns | 1853ns | 1853ns |
| 添加32x32(Flat Func) | 3215NS | 3515NS | 3314NS | 3380NS | 3515NS | 3515NS |
| 添加32x32(WASM F64) | 2737ns | 3032NS | 2864ns | 2903NS | 3032NS | 3032NS |
| 添加32x32(WASM SIMD F64) | 2372NS | 3883NS | 2588ns | 2500NS | 3883NS | 3883NS |
| 添加32x32(WASM SIMD F32) | 1483ns | 1783ns | 1560NS | 1589ns | 1783ns | 1783ns |
| 添加32x32(WASM SIMD I32) | 1499ns | 1645ns | 1555ns | 1584ns | 1645ns | 1645ns |
| 添加64x64(func) | 13200NS | 346600NS | 17719ns | 16700ns | 34600NS | 84700NS |
| 添加64x64(loop) | 13300NS | 246700NS | 18280NS | 17300NS | 39600NS | 97300NS |
| 添加64x64(循环prealloc) | 8600NS | 337000NS | 9713NS | 9100NS | 21900NS | 27700NS |
| 添加64x64(展开) | 318700NS | 640900NS | 339704NS | 339600NS | 498500NS | 513100NS |
| 添加64x64(展开的动态) | 316900NS | 688100NS | 341144NS | 340000NS | 504500NS | 519200NS |
| 添加64x64(flat) | 7324NS | 7669ns | 7461ns | 7476ns | 7669ns | 7669ns |
| 添加64x64(平面Col Major) | 8030ns | 9241NS | 8222ns | 8239NS | 9241NS | 9241NS |
| 添加64x64(平面简单) | 5529NS | 5990NS | 5648NS | 5706NS | 5990NS | 5990NS |
| 添加64x64(平面展开) | 241000NS | 645600NS | 266799NS | 266000NS | 437800NS | 446800NS |
| 添加64x64(f64) | 5500NS | 1690200NS | 9949NS | 9300NS | 22700NS | 27100NS |
| 添加64x64(F32) | 9501NS | 9758NS | 9609NS | 9634NS | 9758NS | 9758NS |
| 添加64x64(i32) | 6333ns | 8882NS | 6713NS | 6585ns | 8882NS | 8882NS |
| 添加64x64(F64平面) | 5000NS | 3709000NS | 12755ns | 13900ns | 27900NS | 32800NS |
| 添加64x64(F32平面) | 5500NS | 4133600NS | 8915NS | 7800NS | 27300NS | 33300NS |
| 添加64x64(i32平面) | 6460NS | 8540NS | 6917NS | 6982NS | 8540NS | 8540NS |
| 添加64x64(flat func) | 9900NS | 254800NS | 13897ns | 13200NS | 27200NS | 69400NS |
| 添加64x64(WASM F64) | 7600NS | 272000NS | 11090NS | 10800NS | 19100ns | 27000NS |
| 添加64x64(WASM SIMD F64) | 6200NS | 2670300NS | 10132ns | 9400NS | 23100NS | 27900NS |
| 添加64x64(WASM SIMD F32) | 5154NS | 6094ns | 5360NS | 5378NS | 6094ns | 6094ns |
| 添加64x64(WASM SIMD i32) | 5188NS | 5973NS | 5396ns | 5433ns | 5973NS | 5973NS |
| 添加128x128(func) | 45800NS | 271300NS | 60844ns | 61900NS | 185300NS | 195600NS |
| 添加128x128(loop) | 55200NS | 390500NS | 72186ns | 74300NS | 205700NS | 213500NS |
| 添加128x128(loop prealloc) | 35100NS | 248300NS | 40496NS | 38600NS | 114200NS | 160200NS |
| 添加128x128(展开) | 1278700NS | 1828300NS | 1343788NS | 1344500NS | 1620500NS | 1723800NS |
| 添加128x128(展开的动态) | 1274000NS | 1792100NS | 1336337NS | 1334900NS | 1586600NS | 1627400NS |
| 添加128x128(flat) | 67700NS | 1414500NS | 94394NS | 83300NS | 393000NS | 485100NS |
| 添加128x128(平面Col Major) | 119700NS | 4007600NS | 148592NS | 132900NS | 471900NS | 519400NS |
| 添加128x128(平面简单) | 59900NS | 508700NS | 93954NS | 105200NS | 272900NS | 299900NS |
| 添加128x128(平面展开) | 1202000NS | 1744700NS | 1291079NS | 1326300NS | 1670100NS | 1682700NS |
| 添加128x128(f64) | 26500NS | 3763100NS | 54327NS | 62100NS | 131800NS | 268700NS |
| 添加128x128(F32) | 27700NS | 3320900NS | 42542NS | 40700NS | 73400NS | 88700NS |
| 添加128x128(i32) | 21200NS | 1250800NS | 29148NS | 26900NS | 54100NS | 68200NS |
| 添加128x128(F64平面) | 22300NS | 4049800NS | 40977ns | 37300NS | 104200NS | 244500NS |
| 添加128x128(F32平面) | 24800NS | 1078300NS | 33077NS | 31000NS | 62400NS | 73600NS |
| 添加128x128(i32平面) | 21000NS | 4687200NS | 29749NS | 26700NS | 60500NS | 69300NS |
| 添加128x128(Flat Func) | 312400NS | 2369600NS | 409509NS | 356500NS | 1593000ns | 1767300NS |
| 添加128x128(WASM F64) | 30100NS | 374300NS | 42977NS | 41900NS | 83300NS | 137000NS |
| 添加128x128(WASM SIMD F64) | 27600NS | 1592700NS | 43336ns | 42700NS | 83900NS | 115400NS |
| 添加128x128(WASM SIMD F32) | 18200NS | 2968600NS | 25829NS | 23300NS | 50000NS | 60700ns |
| 添加128x128(WASM SIMD i32) | 16300NS | 3989800NS | 25720NS | 24100NS | 54400NS | 66100NS |
| 添加256x256(func) | 174800NS | 538100NS | 203033ns | 190800ns | 384200NS | 411800NS |
| 添加256x256(循环) | 282800NS | 707400NS | 315612NS | 300600NS | 526700NS | 596700NS |
| 添加256x256(loop prealloc) | 147400NS | 440400NS | 163873NS | 159600NS | 314000NS | 324800NS |
| 添加256x256(展开) | 5352600NS | 6199900NS | 5632107NS | 5749700NS | 6199900NS | 6199900NS |
| 添加256x256(展开的动态) | 1283700NS | 2213900NS | 1348989ns | 1344300NS | 1629500NS | 2088000NS |
| 添加256x256(flat) | 243200NS | 4196000NS | 393873NS | 402300NS | 1048000NS | 1139200NS |
| 添加256x256(平面Col Major) | 629600NS | 1093900NS | 703013NS | 713100NS | 951000NS | 1000000NS |
| 添加256x256(平面简单) | 318600NS | 882200NS | 390075NS | 394200NS | 604500NS | 636800NS |
| 添加256x256(平面展开) | 4992100NS | 6206500NS | 5352088NS | 5491100NS | 6097200NS | 6206500NS |
| 添加256x256(F64) | 72100NS | 957800NS | 156667ns | 151300NS | 544800NS | 561800NS |
| 添加256x256(F32) | 88900NS | 585400NS | 136578NS | 150000ns | 303100NS | 406400NS |
| 添加256x256(i32) | 65900NS | 468900NS | 101296ns | 100200NS | 241400NS | 376000NS |
| 添加256x256(F64平面) | 69800NS | 724800NS | 148573NS | 132400NS | 540600NS | 554900NS |
| 添加256x256(F32平面) | 80700NS | 676500NS | 116117NS | 114500NS | 270200NS | 388400NS |
| 添加256x256(i32平面) | 67600NS | 3160600NS | 105838NS | 100600NS | 274300NS | 375900NS |
| 添加256x256(Flat Func) | 1254400NS | 5091400NS | 1749203NS | 1452600NS | 5024400NS | 5042400NS |
| 添加256x256(WASM F64) | 116900NS | 1158400NS | 201761ns | 213700NS | 570500NS | 655800NS |
| 添加256x256(WASM SIMD F64) | 90500NS | 715600NS | 173352ns | 157100NS | 551100NS | 559100NS |
| 添加256x256(WASM SIMD F32) | 60700ns | 651400NS | 93714NS | 92100NS | 255200NS | 359800NS |
| 添加256x256(WASM SIMD i32) | 60500NS | 977300NS | 91504NS | 90400NS | 264200NS | 356300NS |