这是一些最佳实践,可以纳入您的lambda功能设计标准。
1.本地存储和参考依赖性
如果您的代码检索任何外部配置或依赖项,请确保在执行初始执行后在本地存储和引用它们。例如,如果您的功能从关系数据库或AWS Systems Manager参数存储中从外部源检索信息,则应将其保存在功能处理程序之外。通过这样做,查找最初运行时会发生查找。随后的温暖起诉将不需要执行查找。


如果您在第3行上看到Handler.js,我们将定义全局值。然后,在第6行上,我们正在检查该值是否存在,如果是的,那么我们将获得值并分配回变量value。这样,在lambda的下一个调用中,如果lambda仍然温暖,我们不需要再次获得相同的参数值。
2.限制变量的重新定位
您还应限制每个调用中变量或对象的重新定位。调用函数时,您的lambda功能代码中的任何声明(在处理程序代码之外)仍将初始化。
为了提高性能,请限制AWS lambda函数中变量或对象的重新定位。当调用lambda函数时,处理程序函数以外的任何代码在函数的启动或冷启动期间仅运行一次。包括可变声明和对象初始化。
在每个调用上重新定位变量或对象表明,该代码正在执行冗余操作,这些操作可能在启动期间仅执行一次。这可能会导致更长的执行时间和lambda功能的性能下降。
限制变量或对象重新定位确保仅在冷启动过程中执行一次这些活动。然后随后的lambda函数调用(温暖的调用)可以重复使用初始变量。
3.检查并重用现有连接
将逻辑添加到您的代码中,以检查在创建连接之前是否已经存在连接。如果存在,只需重复使用即可。
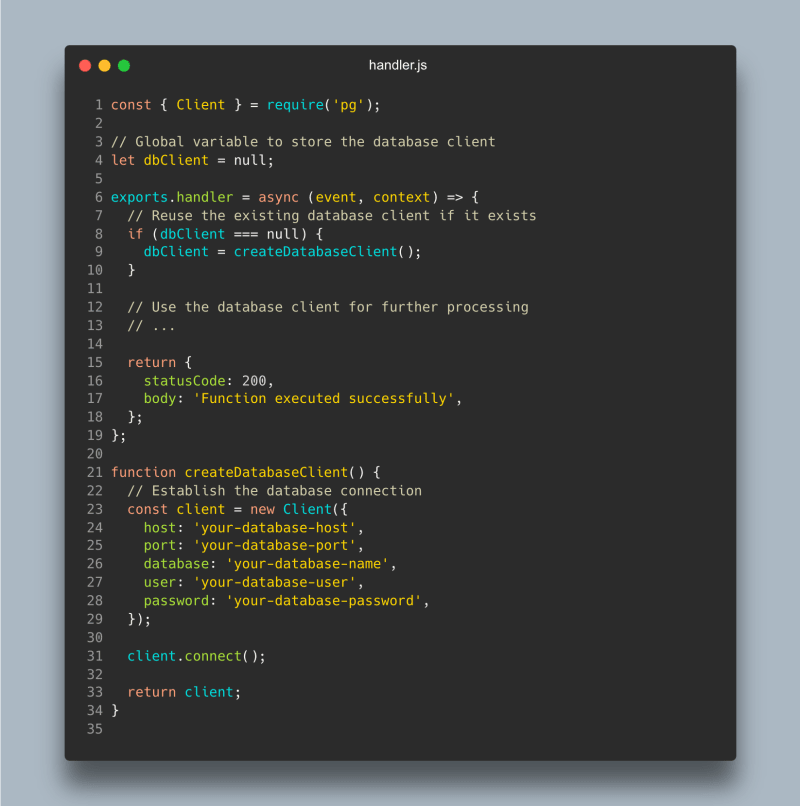
在此示例中,数据库客户端存储在全局变量DBClient中。在初始调用(冷启动)期间,代码检查以查看dbclient是否为null。如果是null,则使用辅助函数创建的atabaseclient生成新的数据库客户端。如果dbClient不是null,则表明客户端已经存在,并且该函数将重新使用现有客户端。
按照lambda函数的调用(热起诉),可能会节省生成新的数据库连接和客户端设置的开销,这可能很耗时。重用客户端辅助Lambda功能的性能和效率。
注意:为了确保维护数据库连接的最佳实践,必须在现实世界中管理错误方案,连接池和适当的客户端关闭。提供的示例简化了出于指示目的。
4.使用 /TMP空间作为瞬态缓存
添加代码以检查本地高速缓存是否具有您之前存储的数据。每个执行上下文在 /TMP目录中都提供了保留在重用环境中的其他磁盘空间。< /p>

该代码使用fs.existsync检查 /tmp目录中是否存在缓存文件。如果文件存在,它将使用fs.ReadFilesync读取从缓存文件中的数据,并将其解析为用于进一步处理的JSON。
如果缓存文件不存在,它将从外部源检索数据,对其进行处理,然后使用fs.writefilesync将其存储在位于 /tmp目录中的缓存文件中。< /p>。< /p>
通过将 /TMP空间作为JavaScript中的瞬态缓存,您可以减少从外部源反复检索相同数据的需求,从而改善性能并减少lambda函数的执行时间。< /p> < /p>
5.检查背景过程已经完成
最后,确保在代码退出之前完成任何背景过程(或node.js的回调)。如果您获得温暖的起点,该功能将恢复时,该功能会启动的背景过程或回调。
概括
通过使用上述最佳实践,您将能够降低延迟,优化成本,提高性能并减少AWS Lambda外部资源的负载。
要阅读更多信息,您可以去AWS Lambda Documentation以获取更多最佳实践。
保持饥饿,保持愚蠢并继续学习!
感谢您的阅读:D
PSSTT pstt:P
请考虑喜欢这篇文章 - ……然后跟随我!为什么不对呢?它是免费的〜
我真的很感激ð»âð»
将在与AWS,JavaScript,无服务器等有关的内容上发布更多信息!