聊天机器人彻底改变了企业与客户互动的方式,提供了高效且个性化的帮助。在本教程中,我们将指导您完成由Faunadb和OpenAI GPT-3.5 Turbo模型提供动力的聊天机器人的过程。通过遵循以下概述的步骤,您将能够创建一个智能的聊天机器人,该聊天机器人可以与用户进行有意义的对话。让我们开始!
先决条件
要遵循并充分理解本教程,您将需要:
- python 3.6或一个较新版本。
- 文本编辑器(最好是VS代码)。
- 对动物和电报机器人的理解。
步骤1:设置环境
在开始之前,让我们确保正确建立我们的开发环境。我们需要以下库:
-
telebot:用于与电报bot API互动的Python库。 -
faunadb:FaunadB的Python驱动程序,一个无服务器云数据库。 -
openai:用于访问OpenAi型号的Python库。 -
dotenv:一个用于从.env文件加载环境变量的Python库。 确保已安装这些库。您可以使用pip安装它们:
pip install pyTelegramBotAPI faunadb openai python-dotenv
接下来,在项目目录中创建一个.env文件以存储您的环境变量。我们将使用此文件来存储诸如API键之类的敏感信息。
步骤2:设置Fauna数据库
您需要开始使用动物群的第一件事是在官方网站上创建一个帐户。您可以在此处使用您的电子邮件地址或GITHUB或NETLIFY帐户来执行此操作:https://dashboard.fauna.com/accounts/register
我们需要FAUNA数据库来存储和检索用户的消息,以有效与我们的聊天机器人
创建我们的数据库

使用Fauna创建我们的帐户后,我们将创建一个数据库来存储我们的用户和消息。在这里,我们将被要求提供我们的数据库名称,我们将命名 mychatbot ,我们的地区将设置为 classic ,就像我们创建了我们的区域数据库,易于右。然后,我们应该在下面提供这样的屏幕:

创建我们的收藏
接下来,我们将创建我们的收藏,这基本上是表在SQL世界中,但在我们的背景下有所不同。
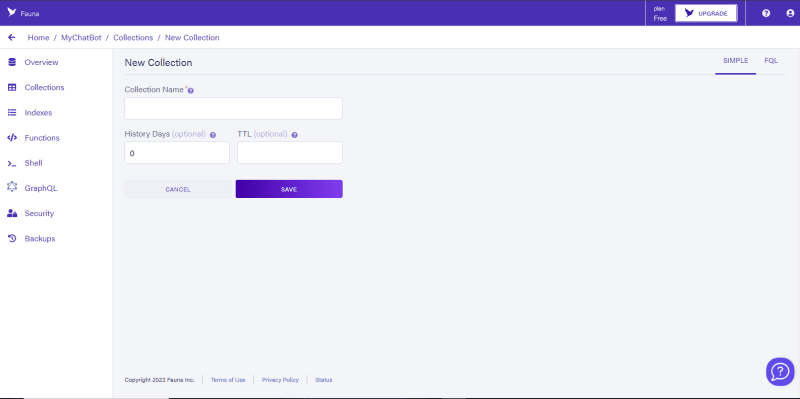
要创建我们的集合,请单击主页上的Create Collection按钮并给它一个名字,但是由于我们要创建两个集合,我们将命名它们用户 和消息。 用户收集是用于从电报中存储我们的用户数据和ID,而消息 Collection则用于将用户的聊天历史记录与机器人存储。您将被要求使用历史记录Days和TTL。历史日用于定义动物区系的数量,应保留该特定集合中任何数据的历史记录,而TTL则是该集合中数据的到期日期。例如,如果将TTL设置为7,则该集合中存储的任何数据将在上次修改日期后7天自动删除,但是对于本教程,我们将不需要它,以便将其保持不变。创建两个集合后,我们应该看到这一点:
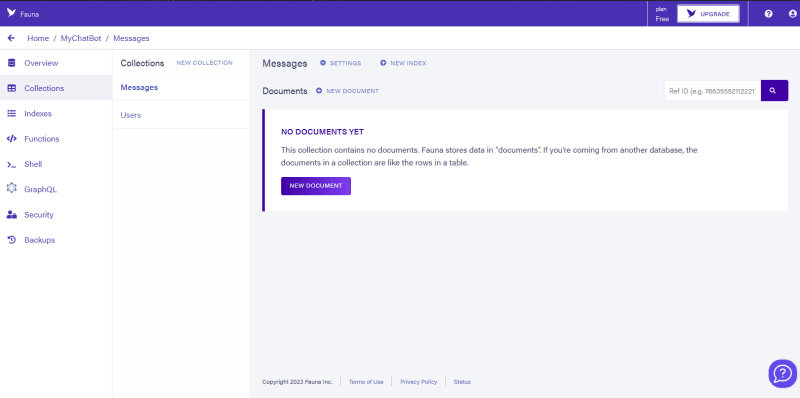
创建我们的索引
想知道什么索引是Ö?嗯,索引只是一种基于特定字段或标准组织的方法,可以更有效地浏览我们集合中的数据,从而可以更快,有针对性地检索信息。要创建我们的索引,我们将导航到索引选项卡,我们应该看到类似的东西:

要创建我们的索引,我们首先需要选择一个集合,然后指定我们的术语,这是该索引仅允许浏览的特定数据。但是对于本教程,我们将创建两个索引, users_by_id 将在我们的用户收集收集到注册用户和 users_messages_by_username 它将过滤我们的用户的消息通过用户名。 术语对于用户_by_id 将设置为data.user_id,而术语 users_messages_by_username 将设置为data.username,然后单击SAVE继续。
获取我们的数据库密钥
在我们开始构建使用Fauna的Python应用程序之前,我们需要创建一个API密钥,该键可以使我们的应用程序轻松地与数据库通信。要创建一个API键,我们需要导航到FAUNA侧边栏上的“安全”选项卡(在屏幕的左侧)。

接下来,我们将单击将我们导航到下面的页面的NEW KEY按钮:
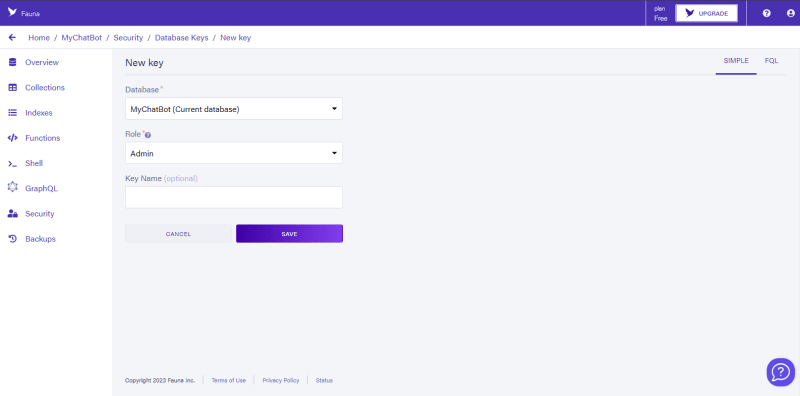
在这里,我们将关键角色设置为 server 而不是 admin ,并将我们的密钥名称设置为可选的数据库名称,然后单击SAVE,我们将被导航。到将显示我们的数据库密钥并要立即复制的页面。我们应该看到这样的东西:

获得API KEY后,将其存储在我们之前在FAUNA_SECRET_KEY变量中创建的.env文件中。
步骤3:创建我们的电报bot
电报机器人是在电报消息平台内运行的自动化程序。它旨在与用户互动并执行各种任务,例如提供信息,提供更新,回答查询和执行命令。这些机器人是使用Telegram的机器人API创建的,可以集成到组聊天中或一对一的对话中。
与Botfather的对话
Botfather 是电报开发人员创建和管理电报平台上其他机器人的必不可少的机器人。要与 botfather 互动,我们需要有一个电报帐户。我们可以在Telegram应用中搜索“ @botfather” 来启动对话。

与Botfather的对话
要与Botfather创建一个新的机器人,我们将使用/newbot ,然后提供机器人的名称,然后我们将获得bot API KEY,这是图像中的HTTP API访问令牌。我们将在BOT_SECRET变量中将其令牌键存储在我们的.env文件中。现在,我们现在可以完全继续编写Codeðü。


步骤4:导入必要的软件包:
如前所述,我们需要某些软件包来开发机器人。现在,我们将继续导入这些软件包。
import telebot
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
import openai
from dotenv import load_dotenv
import json
import os
load_dotenv()
bot = telebot.TeleBot(os.getenv("BOT_SECRET"))
load_dotenv()是加载我们的环境变量,而bot = telebot.TeleBot(os.getenv("BOT_SECRET"))是为我们的电报bot创建一个bot对象。
步骤5:创建我们的命令:
电报机器人中的命令是触发机器人执行特定操作或提供特定响应的特定关键字或短语。例如,当我们在与Botfather的互动过程中使用/newbot命令时,它启动了一个函数,从而有助于创建新机器人。现在,在下面复制并粘贴代码:
def chat(question, user):
userid = user.from_user.id
username = user.from_user.username
return question
def image(prompt, user):
userid = user.from_user.id
return image
user_state = {}
@bot.message_handler(commands=['start'])
def start_message(message):
user_id = message.from_user.id
username = message.from_user.username
bot.reply_to(message, "Hello")
@bot.message_handler(commands=['chat'])
def chat_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'chat'
bot.reply_to(message, "Hello, how may i help you: ")
@bot.message_handler(commands=['image'])
def image_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'image'
bot.reply_to(message, "What kind of image are you creating today: ")
@bot.message_handler(commands=['reset'])
def reset_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'reset'
bot.reply_to(message, "Resetting chat......... ")
@bot.message_handler(func=lambda message: True)
def echo_all(message):
if message.chat.id in user_state and user_state[message.chat.id] == 'chat':
chat_message = message.text
user = message
bot.reply_to(message, chat(chat_message, user))
elif message.chat.id in user_state and user_state[message.chat.id] == 'start':
user = message
bot.reply_to(message, user)
user_state[message.chat.id] = None
elif message.chat.id in user_state and user_state[message.chat.id] == 'image':
image_prompt = message.text
user = message
bot.reply_to(message, image(image_prompt, user))
user_state[message.chat.id] = 'image'
bot.send_message(message.chat.id, "What Image are you creating again?")
elif message.chat.id in user_state and user_state[message.chat.id] == 'reset':
chat_reset = message.text
bot.reply_to(message, reset())
user_state[message.chat.id] = None
bot.polling()
现在,让我们现在浏览以上代码的功能 步骤4中提供的代码只是我们聊天机器人实现的一小部分。目前,我们将增强我们的代码以开发一个完全操作的聊天机器人。 接下来,我们将通过执行索引查询来检索与用户名关联的先前消息。此查询将从消息集合中检索所有文档,我们将提取每个消息的内容并将它们存储在名为“消息”的列表中。 之后,我们将通过从环境变量配置API键来设置OpenAI API。我们还将在系统消息中定义助手的角色。 然后,我们将通过组合系统消息,用户消息和助理消息来构建对话提示。我们将使用此对话提示来生成GPT-3.5 Turbo模型的响应,然后从API响应中提取生成的答复。 然后,我们将准备助手答复的数据,然后将其插入Faunadb中的消息集合中。最后,我们将作为聊天机器人的输出返回生成的答复。 如果存在用户,则将进行前面的步骤,这就是为什么我们创建一个提示功能来处理此情况的原因。在我们的聊天功能中,如果用户存在,则执行提示功能。但是,如果不存在用户,则将其重定向到 完成了必要的实现,现在该将我们的机器人进行测试并确保其完整功能。 恭喜!您已经成功地使用Faunadb和OpenAI GPT-3.5 Turbo模型构建了智能聊天机器人。通过将FAUNADB集成以进行消息存储和检索,并利用GPT-3.5 Turbo的功能生成响应,您的聊天机器人可以与用户进行有意义的对话。 可以通过添加更多功能,改善对话流或将其与其他平台集成来自定义和增强聊天机器人。可能性是无限的! 记住处理安全考虑因素,例如保护敏感数据和管理对API键的访问,以确保您的聊天机器人的安全操作。 快乐的机器人构建!
该机器人响应用户命令,例如/start,/chat和/image,同时使用user_state dictionary维护每个用户的对话状态。接收/start命令后,该机器人发送a “ Hello” 回复并重置用户的状态。同样,当接收到/chat命令时,机器人询问如何帮助并将用户的状态设置为'chat''。在/image命令的情况下,该机器人提示用户获取图像类型,并将状态设置为'image'。对于任何其他消息,机器人都会检查用户的状态并相应地响应,例如在'chat''状态中呼应该消息,在'image'状态,提供用户信息并在'start'状态中重置状态。使用bot.polling()。
步骤5:更新我们的命令
/start命令
/start命令将作为我们聊天机器人的初始入口点。它将验证使用我们之前创建的users_by_id索引中的faunadb 用户中是否存在一个用户,如果没有,它将将用户添加到 user 集合中,然后发送发送。一条消息将将用户重定向到我们的/chat,该消息处理我们的聊天功能。此过程涉及从我们的Telegrambot API中检索用户的用户名和ID。更新的代码:
@bot.message_handler(commands=['start'])
def start_message(message):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
user_id = message.from_user.id
username = message.from_user.username
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), user_id)))
if not user_exists:
client.query(
q.create(
q.collection("Users"),
{
"data": {
"user_id": user_id,
"username": username
}
}
)
)
bot.reply_to(message, "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nTo begin, type /chat or click on it")
/chat命令
为了创建我们的聊天机器人,我们将使用FaunAclient类和环境变量中的秘密键创建一个FaunADB客户端。然后,我们将准备一个包含用户名和用户问题的数据对象,然后将其插入消息集合中。
def prompt(username, question):
# Create a FaunaDB client
client = FaunaClient(secret=os.getenv('FAUNA_SECRET_KEY'))
data = {
"username": username,
"message": {
"role": "user",
"content": question
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": data
}
)
)
index_name = "users_messages_by_username"
username = username
# Paginate over all the documents in the collection using the index
result = client.query(
q.map_(
lambda ref: q.get(ref),
q.paginate(q.match(q.index(index_name), username))
)
)
messages = []
for document in result['data']:
message = document['data']['message']
messages.append(message)
# Set up OpenAI API
openai.api_key = os.getenv('OPENAI_SECRET_KEY')
# Define the assistant's persona in a system message
system_message = {"role":"system", "content" : "A helpful assistant that provides accurate information."}
# Construct the conversation prompt with user messages and the system message
prompt_with_persona = [system_message] + [
{"role": "user", "content": message["content"]} if message["role"] == "user"
else {"role": "assistant", "content": message["content"]} for message in messages
]
# Generate a response from the model
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=prompt_with_persona
)
# Extract the generated reply from the API response
generated_reply = response["choices"][0]["message"]["content"]
newdata = {
"username": username,
"message": {
"role": "assistant",
"content": generated_reply
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": newdata
}
)
)
return generated_reply
/start命令以注册它们。更新的聊天功能:
def chat(question, user):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
global chat_list
userid = user.from_user.id
username = user.from_user.username
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), userid)))
if user_exists:
reply = prompt(username, question)
return reply
else:
return "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nThis user is not logged in , type /start or click on it to login"
/image命令
/image命令用于将用户文本转换为图像。以下是其操作的方式:首先,它验证用户是否存在数据库中。如果用户存在,它将使用OpenAi Dall-E 2模型生成并返回图像URL输出。更新的代码:
def image(prompt, user):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
userid = user.from_user.id
openai.api_key = os.getenv('OPENAI_SECRET_KEY')
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), userid)))
if user_exists:
generated_image = openai.Image.create(
prompt=prompt,
n=1,
size="1024x1024"
)
image_url = generated_image['data'][0]['url']
return image_url
else:
return "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nThis user is not logged in , type /start or click on it to login"

结论