这篇文章是我最初发表的in the Orchest blog的改编。自从我写它以来,VAEX项目已经变得不活跃,更现代的替代品(如Polars)已获得了对核心外处理的支持。我仍然想在这里复制它以出于历史目的并为该系列提供连续性。
VAEX:一种新的数据范围方法
Vaex是一个开源python库,提供了懒惰的,较不间断的数据范围“可视化和探索大型表格数据集”。最初,它是为可视化巨大的盖亚星目录而创建的GUI工具,后来又演变为一个强大的数据操纵库。但是,在这种情况下,“懒惰”和“核心外”是什么意思?
- “ Lazy” 表示某些操作不会立即完全执行:相反,他们的评估被延迟或推迟,直到明确要求或进行聚合进行汇总。 。
- “核心外” 是指a set of techniques,它允许用户通过从磁盘中读取块来操纵比可用RAM大的数据。这是透明的。
vaex并不是唯一的懒惰的,核心的数据帧库:诸如Dask之类的其他项目也应用了这些概念,尽管以截然不同的方式。我们将在以后的帖子中介绍Dask!
(如果您不确定发音,维护者称其为/vəks/,因此具有短而中性的元音声音)
![]()
VAEX的第一步
对于此示例,我们将使用从Kaggle获得的2009年至2018年的Airline Delay and Cancellation Data数据集,该数据本身源自U.S. Department of Transportation。
您可以使用Conda/Mamba或Pip安装VAEX:
mamba install -y "vaex=4.9"
# Or, alternatively
pip install "vaex==4.9"
vaex实际上是一个元数据,因此您可能需要确切选择您感兴趣的哪些部分。对于本教程,您只需要VAEX-CORE和VAEX-VIZ:
mamba install -y "vaex-core=4.9" vaex-viz
# Or, alternatively
pip install "vaex-core==4.9" vaex-viz
您有更多详细的安装说明in the official documentation。
让我们通过执行
首先加载数据集的最后一个.parquet文件
import vaex
df_2018 = vaex.open("/data/airline-delays/2018.parquet")
返回对象的类型是vaex.dataframe.dataframeLocal,它是“与本地文件/数据一起使用的数据框架的基类”(docs)。您会注意到,即使数据框架的行超过700万行:
,公开通话几乎立即完成。
In [2]: len(df_2018)
Out[2]: 7213446
原因是,使用二进制文件格式,VAEX使用内存映射,因此您可以操纵大于RAM的数据集(类似于Pyarrow所做的,as covered in the first part of the series)。
vaex支持几种二进制文件格式(羽毛,镶木,以及一些特定领域的格式,例如HDF5和FITS)以及基于文本的格式(CSV,JSON,ASCII)。但是,后者不能进行内存映射,因此使用它们时需要更加小心:
- 如果数据适合内存,请考虑到整个数据集将加载。。
- 如果数据不适合内存,请通过convert = true和一个chunk_size –打开参数,以便vaex将数据转换为幕后二进制格式,在过程中使用额外的磁盘空间 >。
现在,返回我们的数据框:要显示有关它的更多信息,您可以调用.info()方法,该方法将显示:
- 行数
- 列的名称和类型信息
- DataFrame的前五和最后五行
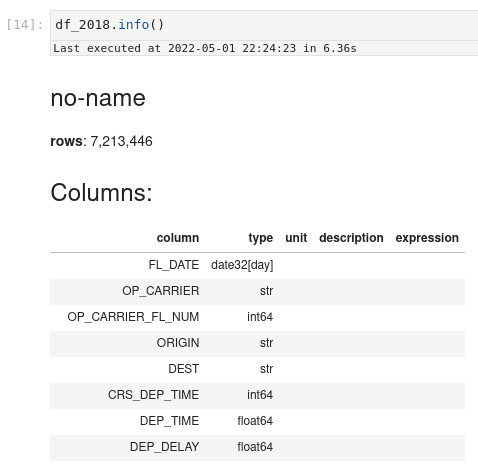
.info()结果的开始
此外,.describe()将像熊猫一样工作,并显示每列统计信息的摘要:

.describe()结果的输出
您可以看到,vaex,例如熊猫,也利用jupyter的交互功能以视觉上吸引人的方式显示信息。
表达力的力量
喜欢在熊猫中,您可以使用索引:
索引VAEX数据框的特定列
In [10]: df_2018["OP_CARRIER"] # Or df_2018.col.OP_CARRIER
Out[10]: Expression = OP_CARRIER
Length: 7,213,446 dtype: string (column)
----------------------------------------
0 UA
1 UA
2 UA
3 UA
4 UA
...
7213441 AA
7213442 AA
7213443 AA
7213444 AA
7213445 AA
但与熊猫不同,这返回一个表达式:尚未评估的计算步骤的表示。表达式是VAEX的力量功能之一,因为它们允许您以懒惰的方式链接多个操作,因此无需实际计算它们:
# Normal subtraction of two columns
df_2018["ACTUAL_ELAPSED_TIME"] - df_2018["CRS_ELAPSED_TIME"]
# Creation of an equivalent expression by using indexing
df_2018["ACTUAL_ELAPSED_TIME - CRS_ELAPSED_TIME"]
# NumPy functions also create expressions
import numpy as np
np.sqrt(df_2018["DISTANCE"])
# Or they can be used inside the indexing itself!
df_2018["sqrt(DISTANCE)"]
有两种完全评估表达式的方法:
- 通过检索.values属性(将返回numpy数组)或调用.TO_PANDAS_SERIES()来请求内存表示。确保数据适合RAM!
- 执行聚合(例如.mean(),.max(),等等),例如:
In [12]: df_2018["CANCELLED"].sum()
Out[12]: array(116584.)
对于更复杂的表达式和过滤器,VAEX支持显示交互式progress bars:
In [15]: # We exclude "CANCELLED" flights and ones that arrived on time
...: # to compute the mean delay time
...: delayed = df_2018[(df_2018["CANCELLED"] == 0.0) & (df_2018["DEP_DELAY"] > 0)]
...: delayed["DEP_DELAY"].mean(progress="rich") # Fancy progress bar!
mean ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 01.05s
└── vaex.agg.mean('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 01.05s
├── vaex.agg.sum('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 01.04s[1]
└── vaex.agg.count('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 01.04s[1]
Out[15]: array(38.18255826)
现在您知道了它是如何完成的,让我们一次读取所有.parquet文件并执行相同的计算:
In [16]: df = vaex.open("/data/airline-delays/\*.parquet")
In [17]: len(df)
Out[17]: 61556964
In [18]: delayed = df[(df["CANCELLED"] == 0.0) & (df["DEP_DELAY"] > 0)]
In [19]: delayed["DEP_DELAY"].mean(progress="rich")
mean ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 09.03s
└── vaex.agg.mean('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 09.03s
├── vaex.agg.sum('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 09.03s[1]
└── vaex.agg.count('DEP_DELAY') ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 09.03s[1]
Out[19]: array(32.15845342)
vaex在不到10秒内将超过6000万行的弯管ð¥
最后,vaex有一些built-in visualization capabilities,可以智能包装其聚合和包装功能,以提供更高级别的接口:

60+百万行的快速直方图
熊猫有一些差异
VAEX和PANDAS之间有趣的区别之一是,该索引的概念不存在。这意味着,当使用vaex.from_pandas从熊猫转换数据时,您将需要确定是否将索引作为正常列(传递copy_index = true)或将其完全丢弃(copy_index = false,默认行为)。
另一方面,VAEX不等同于.loc访问者,因此,要通过行和列过滤,您将不得不链接多个索引操作。但是,这不是问题,因为VAEX不复制数据。
表演的注释
如果您在交互式设置(例如,在Jupyterlab上)在you might observe that sometimes Vaex is slightly slower上比较VAEX和PANDAS运行时间。但是,如果您执行适当的微基准测试,您会注意到VAEX实际上比Pandas快,甚至适用于RAM的数据:
In [20]: %%timeit -n1 -r1
...: df = vaex.open("/data/airline-delays/2018.parquet")
...: delayed = df[(df["CANCELLED"] == 0.0) & (df["DEP_DELAY"] > 0)]
...: mean_delayed = delayed["DEP_DELAY"].mean()
...:
1.31 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
In [21]: %%timeit -n1 -r1
...: df_pandas = pd.read_parquet("/data/airline-delays/2018.parquet")
...: delayed_pandas = df_pandas.loc[(df_pandas["CANCELLED"] == 0.0) & (df_pandas["DEP_DELAY"] > 0)]
...: mean_delayed_pandas = delayed_pandas["DEP_DELAY"].mean()
...:3.81 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
这是不可能考虑到在受到束缚环境中使用熊猫阅读所有数据的不可能是不可能的:
# Equivalent of
# df = vaex.open("/data/airline-delays/\*.parquet")
# Jupyter shortcut to read all files
fnames = !ls /data/airline-delays/\*.parquet
# Loads everything in memory,
# and therefore it might blow up!
df = pd.concat([
pd.read_parquet(fname) for fname in fnames
])
故事的寓意:benchmarking is difficult!
您应该使用VAEX吗?
除了我们在简短的介绍中看到的内容外,VAEX具有强大的可视化功能,以及在其他图书馆中找不到的某些功能,如果您正在使用propagation of uncertainties,just-in-time compilation of math-heavy expressions和propagation of uncertainties,以及更多。
如果您已经在磁盘上具有支持的二进制格式的数据,或者它的数据是基于文本的格式并且有足够的空间将其转换,则VAEX是以有效方式处理其的绝佳解决方案。如您所见,VAEX模仿Pandas API,但它不是基于它,并且在某些小地方偏离。另一方面,它是一个年轻的图书馆,用户群较小,并且文档的某些部分可能不那么完整 - 幸运的是,维护者通过快速回应问题和反馈来补偿。
总结:
- 如果您在磁盘上有大量数据不适合记忆的数据,如果您想利用快速的可视化功能,如果您有科学用例与熊猫不同。
- 如果您正在寻找解决方案来快速迁移大型PANDAS代码库,或者如果您在存储约束的环境中,请从网络或CSV格式读取大量数据。
在本系列的即将到来的文章中,我们将描述您可能会发现有趣的一些替代方案。敬请期待!