在本文中,我们将探讨如何使用pandas.cut()方法创建数据分析的数字和日期间隔。
什么是pandas.cut()?
python pandas.cut()是熊猫库中的一种方法,可让您将连续变量拆分为间隔。
此方法基于您指定的垃圾箱创建一个新的分类变量。
可以将垃圾箱指定为数字列表或许多均匀间隔的间隔。
此方法通常用于数据分析中,将连续数据分为类别或垃圾箱。这对于创建用于数据转换,时间序列分析并更有信息的类别很有用。
如果您想对这些主题有更深入的了解,我建议这本书 Python for Data Analysis ,这是有关如何使用Python处理数据的权威指南。您可以找到它 here 。
现在,让我们转到有关如何使用 pandas.cut() method的第一个示例。
使用pandas.cut()创建数字间隔
假设我们有一个学生成绩的数据集,我们希望将它们分类为字母等级(a,b,c,d和f)。
我们可以通过基于等级范围创建垃圾箱来做到这一点。

现在,让我们为成绩创建垃圾箱:

我们想将等级分为以下字母等级:F(60),D(60â69),C(70â79),B(80â89)和A(90â 100)。
我们可以使用 pandas.cut()方法:

结果变量 letter_grades 是一个分类变量,数据集中每个等级的字母等级。

如果您愿意,您也可以对其进行排序和分组:

使用pandas.cut()创建日期间隔
现在让我们看看如何使用pandas.cut()创建日期间隔。
假设我们有一个日常销售数据集,我们希望将它们分为每月的间隔。我们可以通过根据一个月范围创建垃圾箱来做到这一点。
首先,再次,我们需要导入熊猫库并创建一个示例数据集:

现在,让我们为销售创建垃圾箱:

和标签:

我们想将销售分为每月的间隔。我们可以使用 pandas.cut()方法来实现这一目标:

的结果是:
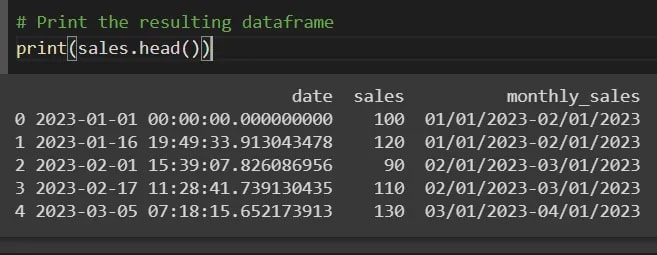
间隔中的数字对绘制简洁图表有用,在这种情况下,使用x轴中的月sales。它使图表更加紧凑,更易于阅读。
呈现数据时至关重要,如 Storytelling with Data 所述,这是有关如何与数据有效通信的确定手册。
找到它 here 。
结论
总而言之, pandas.cut()是PANDAS库中的一种强大方法,可让您将连续变量拆分为间隔。
通过使用此方法,您可以创建用于数据分析的分类变量,并从原始数据中获取见解。
如果您想通过Python了解有关数据分析的更多信息,我强烈建议您以下书籍: