您是否想知道编译器是如何编写的?您想学习如何使用Lex和Yacc编写编译器吗?很棒的时机!
关于这个系列
在这一系列帖子中,我们将创建一个编译C子集的小型编译器,然后我们将构建一个虚拟机,以执行编译指令。
我将尝试在帖子中包含所有详细信息,但是如果某些内容不起作用或错误地遗漏了,请检查GitHub repository中的完整代码。
迷你C,我们的语言
在构建编译器之前,让我们确定语言是什么。这是一个可以编译和运行的示例程序:
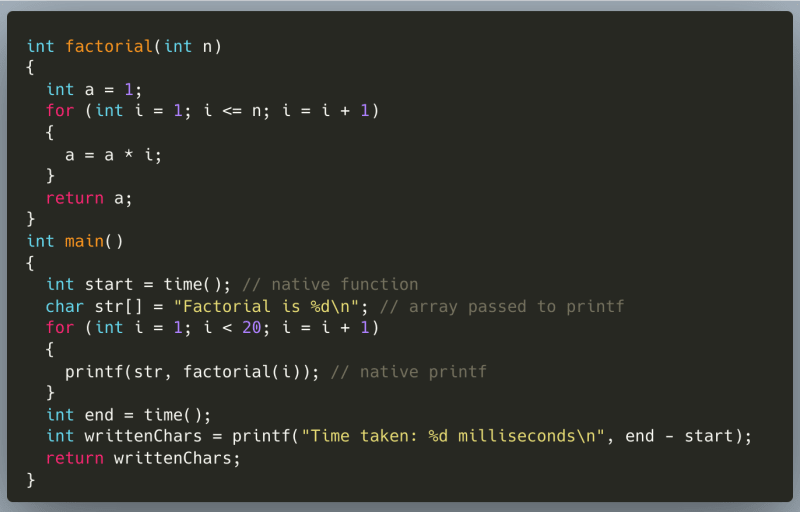
我们将通过实现函数调用,添加本机函数printf()和time(),多维数组和浮点数。
令人兴奋?好吧,鞭打您喜欢的编辑,在播放列表上打耳光,然后填充咖啡杯。您知道,设置心情。
先决条件
好吧,在我们开始之前,请确保我们都在同一页面上。这是您应该熟悉的几件事:
首先,编译器的一般阶段,即词汇分析,语法分析,语义分析,代码生成和优化。您可以阅读有关这些here.
的更多信息第二,正则表达式和语法。阅读什么是编程语言语法是on this page和regular expressions here.
Lex和Yacc
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--EfcvKmkJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/11232/0%2AjSNKHS3Sc6R5tb2U)
您的操作系统还需要安装LEX和YACC。可以在此处阅读有关使用这些工具的简短指南:https://arcb.csc.ncsu.edu/~mueller/codeopt/codeopt00/y_man.pdf。
流
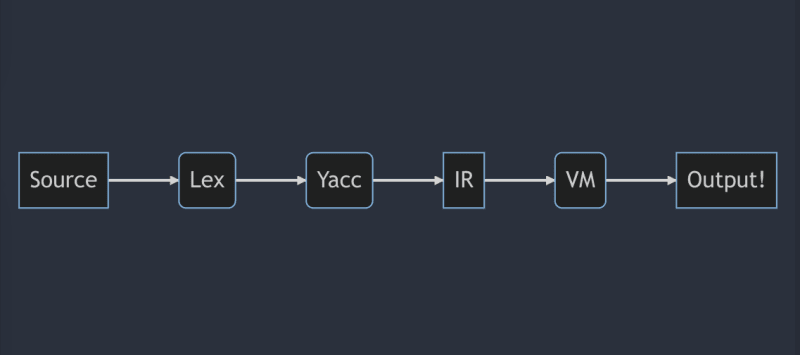
这是编译器的结构。前端阶段包含LEX和YACC,该LEX和YACC以三个地址代码的形式生成中间表示形式,并将其传递给后端。然后,后端阶段将IR进行并执行。我们可以在此处放置优化和机器代码生成阶段。
实际上,YACC呼吁Lex生成的Lexer对输入流进行象征。
yylex()被yyparse反复调用,以获取下一个令牌,并根据语法确定要执行的操作。我们将在系列的下一部分中深入研究此过程。
Lex
LEX是一个生成扫描仪(也称为Tokenizers)的程序,可以识别文本词汇模式。 LEX通常与YACC解析器发生器一起使用。
您可以说Lex是一款光荣的正则发动机。 Lex有点幻想,是正则发动机世界中的精湛技艺的典范,但其实力远远超出了单纯的模式匹配。实际上,该强大的工具具有许多其他功能,使其成为词汇分析领域中的尊敬的资产。
现在还有其他LEX和YACC的替代方案,例如Antlr或其他解析器的发电机和解析器组合器。 This stackoverflow answer描述了两者之间的差异。
LEX列入规范文件,并产生与输入文件中的Regexes匹配并根据匹配的字符串执行操作的C代码。您可以在输入文件中编写C代码,该文件将直接复制到输出文件。
规范文件定义了匹配输入文本的规则。该文件由三个部分组成:定义,规则和用户代码。您可以在“定义”部分中声明变量,宏和正则表达式。规则部分是您指定要匹配的模式以及找到匹配时要执行的操作的地方。在“用户代码”部分中,您可以编写扫描仪所需的任何其他C代码。
definitions
%%
rules
%%
user code
由于这不是Lex指南,因此我会介绍Lex的更多细节和功能。查看this flex manual;它有很好的例子和解释。
令牌
我们需要令牌,但是是什么??

上图显示了语句int arr[] = {1};
简而言之,代币将代码分解为符号,标识符和文字(例如数字和字符串),同时忽略评论和空格。
将以下行分为几个令牌?
char str[5] = "abcd";
答案:8
令牌类型
每个令牌都有令牌类型。此类型代表令牌所属的类。班级可以像关键字一样广泛。令牌代表的源代码的子字符串称为其 lexeme。因此,例如,数字类型令牌的词汇将是字符串1.23。关键字的词汇是关键字本身。
尽管LEX用于代币化源,但令牌在YACC文件中声明。创建一个名为parser.y的文件以编写令牌类型。
如果您不知道YACC,则无需惊慌!坚持下一部分,我们将深入研究更细节。或者,如果您足够大胆且不耐烦,这是一个方便的starting point。
yacc中的每个令牌都有与之关联的 *值 *。对于整数,值是整数值。这存储在LEX文件中声明的Yylval变量中。
由于我们需要处理各种令牌值(整数,浮动,字符,字符串),因此我们将联合定义为Yylval数据类型。这是使用YACC中的%联合命令完成的。
/* File: parser.y */
%{
#include <stdio.h>
#include <stdlib.h>
char *currentFileName;
extern int lineno, col;
int yyerror(char *s);
int yylex();
%}
%union {
int iValue;
float fValue;
char* sValue;
IdStruct id;
char cValue;
};
/* Keywords */
%token <iValue> K_INT K_FLOAT K_CHAR
%token FOR WHILE ELSE IF SWITCH CASE RETURN CONTINUE BREAK DEFAULT
/* Literals */
%token <iValue> INTEGER
%token <fValue> FLOAT
%token <cValue> CHARACTER
%token <sValue> STRING
/* Variables and functions */
%token <id> IDENTIFIER
/* Operators && || >= <= == != */
%token AND OR GE LE EQ NE
/* Other operators are returned as ASCII */
/* End of file token */
%token EOF_TOKEN
%%
/* Dummy grammar */
program: IDENTIFIER;
%%
// Error routine
int yyerror(char *s){
exit(1);
return 1;
}
尽可能明显,%token在解析器中定义了令牌。令牌类型在角度支架中指定,指的是%union声明中的一个变量。
yacc在遇到解析错误时调用函数
yyerror。您可以阅读有关这些yy-函数的更多信息。
您应该注意到标识符变量是带有类型IdStruct的ID。该结构在symbol.h文件中定义,看起来像这样:
// File: symbol.h
#ifndef __SYMBOL
#define __SYMBOL
// Stores the coordinate in source file
typedef struct
{
// Length is for an expression
unsigned int line, col, length;
} Coordinate;
// Token type for an identifier
typedef struct
{
Coordinate src; // used for error reporting
char *name; //copied string (pointer)
} IdStruct;
#endif
yacc生成了一个名为y.tab.h的标头文件,将令牌作为枚举成员。要生成此标头文件,请运行yacc -d parser.y。
tokenizer.l
让我们开始使用令牌。这将使我们的源代码将其切成以前定义的代币并将其传递给解析器。然后,解析器使用这些令牌根据语法生成解析树。
首先,我们从规范文件的定义部分开始。
/* tokenizer.l */
%{
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <stdlib.h>
#include "symbol.h"
#include "y.tab.h"
#define MAX_STR_CONST 1000
#define yyterminate() return EOF_TOKEN
/* YY_USER_ACTION is called after
matching a pattern and before executing the action */
#define YY_USER_ACTION \
col += yyleng;
extern char *currentFileName;
int col = 1; //track the current column
int lineno = 1;
int yyerror(char* s);
%}
max_str_const是mini C. yyterminate()中字符串文字的最大长度,定义了终止Lexer的函数。这返回文件令牌的末尾。
接下来,定义一些助手正则表达式:
%}
alpha [a-zA-Z]
alphanum [a-zA-Z0-9]
digit [0-9]
nonzero [1-9]
%%
这完成了定义部分。我们将返回这里添加更多内容来处理字符串和评论,但这是以后的。
关键字和符号
欢迎使用规则部分!在这里,我们布置了砖块的令牌建筑砖。
由于yylval是%union在parser.y中定义的联盟,因此我们必须小心地设置union的正确字段。
关键字和符号非常简单:只需返回匹配的内容即可。这是匹配模式:
%%
char string_buf[MAX_STR_CONST]; /* to store strings */
char *string_buf_ptr;
/* Keywords */
"int" {return K_INT;}
"float" {return K_FLOAT;}
"char" {return K_CHAR;}
"for" {return FOR;}
"while" {return WHILE;}
"else" {return ELSE;}
"if" {return IF;}
"switch" {return SWITCH;}
"case" {return CASE;}
"return" {return RETURN;}
"continue" {return CONTINUE;}
"break" {return BREAK;}
"default" {return DEFAULT;}
/* Symbols
Return the first character of the matched string
*/
[-+*/%] return *yytext;
[;,:()] return *yytext;
[\{\}\[\]] return *yytext;
[=!<>] return *yytext;
/* Lex always executes the longest match action */
"==" {return EQ;}
">=" {return GE;}
"<=" {return LE;}
"!=" {return NE;}
"&&" {return AND;}
"||" {return OR;}
在调用yylex()时,lex将通过这些模式进行这些模式,并执行与最长字符串匹配的模式的动作。
数字和字符
这是匹配整数和浮动数字的正则方式:
/* Integers */
0 {yylval.iValue = 0; return INTEGER;}
{nonzero}({digit})*([eE][-+]?[0-9]+)? {
yylval.iValue = (int)round(atof(yytext)); return INTEGER;}
/* Floats */
{nonzero}({digit})*"."({digit})*([eE][-+]?[0-9]+)? {
yylval.fValue = atof(yytext); return FLOAT;}
/* Characters */
"\'"({alpha}|{digit})"\'" {yylval.cValue = yytext[1]; return CHARACTER;}
操作零件相应地设置了iValue或fValue字段,并返回令牌(INTEGER或FLOAT)的类型
将其解析为整数或浮点数号
yytext指向源字符串的当前匹配子字符串。它必须使用标准库函数atoi(参数为int)和atof
身份标识
标识符令牌将捕获标识符字符串并将其传递给解析器。该捕获的字符串将在编译器的整个生命周期中粘贴。
/* Identifiers */
(_|{alpha})((_|{alphanum}))* {
yylval.id.name = malloc(strlen(yytext)+1);
yylval.id.src.line = lineno;
yylval.id.src.col = col - yyleng;
// yylval.name = malloc(strlen(yytext)+1);
strcpy(yylval.id.name, yytext);
// strcpy(yylval.name, yytext);
return IDENTIFIER;
}
字符串
对于字符串,我们在Lex中使用起始条件。要定义起始条件,请将定义放置在“定义”部分中。
%x str
%x comment single_line_comment /* for comments */
这些是独家开始条件,这意味着当这些条件处于活动状态时,其他规则将匹配。为了解析字符串,我们BEGIN str看到第一个"并继续向缓冲区添加字符,直到看不到关闭的"。
/* Strings*/
\" { string_buf_ptr = string_buf; BEGIN(str);}
<str>\" {
BEGIN(INITIAL);
*string_buf_ptr = '\0';
yylval.sValue = (char*)malloc(strlen(string_buf)+1);
strcpy(yylval.sValue, string_buf);
return STRING;
}
<str>\n {yyerror("Unterminated string.\n"); return ERROR;}
<str>\\n {*string_buf_ptr++ = '\n';}
<str>[^\n] {
*string_buf_ptr++ = *yytext;
}
除了
\n之外,没有支持逃生角色,但是如果您感觉足够冒险,请添加其他逃生序列,例如\"
评论
评论被视为白道,并被令牌忽略。同样,我们使用起始条件忽略评论中的字符。
/* Comments*/
"//" BEGIN(single_line_comment);
<single_line_comment>"\n" {col = 1; lineno++; BEGIN(INITIAL);}
<single_line_comment><<EOF>> {BEGIN(INITIAL); return EOF_TOKEN;}
<single_line_comment>[^\n]+ ;
"/*" BEGIN(comment);
<comment>"\n" {col = 1; lineno++;}
<comment>"*/" {BEGIN(INITIAL);}
<comment><<EOF>> {yyerror("Unclosed comment found\n");}
<comment>. ;
空格
这很可悲,但我们必须这样做。忽略空格。并在任何其他角色上提出错误。
/* Whitespace */
[ \t\r] ;
\n {col = 1; lineno++;}
. {yyerror("Error: Invalid character"); return ERROR;}
与Main结束
几乎完成了!通过像这样结束规则部分来结束令牌:
%%
int yywrap(){
yyterminate();
return EOF_TOKEN;
}
并创建一个文件main.c,该文件将从文件中读取令牌:
//File main.c
#include <stdio.h>
#include <stdlib.h>
#include "symbol.h"
#include "y.tab.h"
// The current line number.
// This is from tokenizer.l.
extern int lineno;
extern FILE *yyin;
// Current token's lexeme
extern char *yytext;
// The source file name
extern char *currentFileName;
// From lex.yy.c, returns the next token.
// Ends with EOF
int yylex();
int main()
{
yyin = fopen("input.txt", "r");
int token;
while ((token = yylex()) != EOF_TOKEN)
{
printf("Token: %d: '%s'\n", token, yytext);
}
return 0;
}
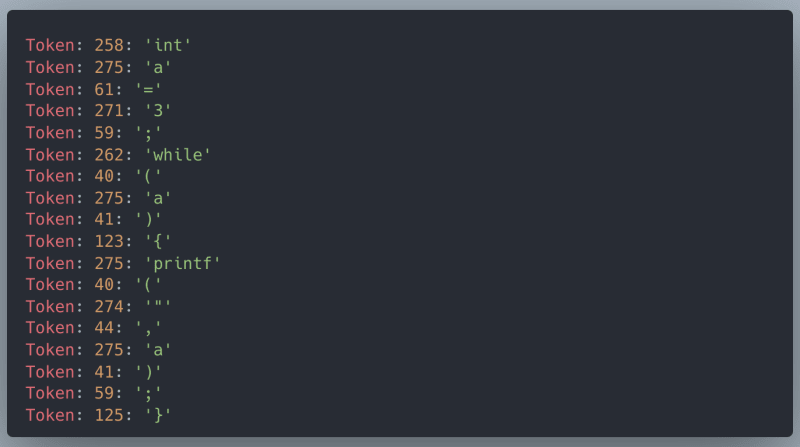
创建一个文件input.txt并输入您的示例程序。
// input.txt
int a = 3;
while(a){
printf("%d", a);
}
通过运行:
编译
> yacc -d parser.y
> lex tokenizer.l
> gcc y.tab.c lex.yy.c main.c -ll -lm
> ./a.out
和您的输出!
结论
很棒的工作,您现在拥有自己的令牌!
尽管我几乎没有使用Lex提供的内容,但值得浏览上面的一个链接(找到它们!ð),并且可能会添加或修改一些令牌。
在下一部分中,我们将编写语法,并能够确定给定程序是否具有有效的语法。直到那时,愉快的编码!
我希望您喜欢这篇文章,并学到了一些新的东西。如果这样做,请显示支持并点击该React按钮。这确实有助于我,并激励我继续为您编写更多令人敬畏的内容。感谢您的阅读!
最终代码
编译器的完整源代码可用on GitHub.
我添加了更多功能来报告源程序中的错误。当检测到无效的字符时,yyerror将带有当前列和行号的point_at_in_line函数。这读取源文件并以令人愉悦的方式打印给定的行和列号。