实时数据在当今快节奏的商业世界中变得越来越重要,因为公司试图根据可用的最新信息获得有价值的见解并做出明智的决策。但是,处理和分析实时数据可能是一个挑战,尤其是在实时连接多个数据流时。在本文中,我们将探讨多流连接的概念在SQL 中,并讨论了使用streaming database有效地执行这些加入的一些技巧和技术。
多流连接:他们是什么?
多流连接涉及将两个或多个数据流组合在一起,以创建一个反映数据当前状态的单个输出流。这可能是一种强大的技术,用于分析来自多个来源的实时数据,例如物联网设备,社交媒体供稿,电子商务应用程序或金融市场。
在SQL中,通常使用指定input streams,联接条件以及任何其他所需的filtering或aggregation函数的查询进行连接。这些查询的确切语法可以根据所使用的数据库系统而有所不同,但是基本原理是相同的。
想象一下,您在的乘车共享公司工作,例如在多个城市运作的Uber。您有来自驱动程序的GPS设备的数据流,其中包括其位置,速度和其他相关信息。您还拥有来自客户移动应用程序的数据流,其中包括其位置,目的地和其他相关详细信息。
为了提高客户体验并优化驾驶员效率,您想实时加入这两个数据流,以更好地了解驾驶员的位置,客户正在等待乘车以及哪些路线是最有效。请参阅下面的几个方案。
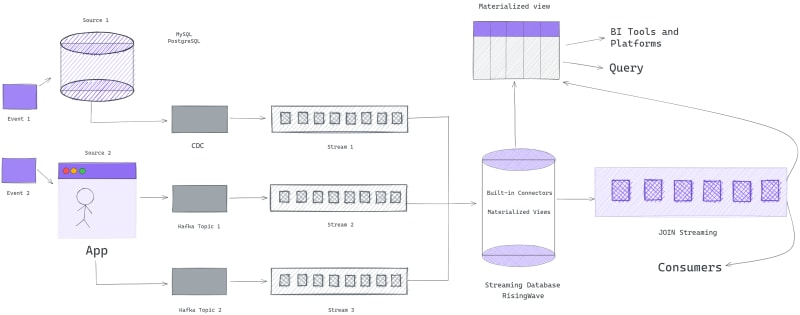
多流连接的流数据库
如果您想在SQL中执行流到流的连接,则流数据库可以帮助您充分利用数据。通过使用流数据库,您可以在单流> 上连续运行SQL查询,然后连接两个或多个流。与其他流行的RDBMS(关系数据库管理系统)一样,流数据库可以使用各种sources或materialized views10的任何两个数据集/表表达式将任何两个数据集/表格连接在一起。与流数据库和传统数据库一起加入的主要区别在于正在处理的数据的性质。在传统数据库中,数据通常存储在表中,并且在该存储的数据上进行查询。另一方面,在流数据库中,数据在生成时进行实时处理,并且随着数据流以数据的形式运行,在此实时数据流上进行查询。不同的message brokers(如Kafka)。您可以阅读有关how a streaming database differs from a traditional database?的更多信息。
在下一部分中,我使用RisingWave作为流数据库,并提供了一些示例,说明了如何使用SQL执行多流连接。您可以找到有关如何选择right streaming database的更多信息。
RisingWave 使用Postgres兼容SQL作为接口来管理和查询数据。 This guide将带您浏览Risingwave中一些最常用的SQL命令。
加入溪流
想象一下,您要分析乘车共享数据,您可能会选择根据位置字段加入驱动程序数据流和客户数据流,因为这将使您可以跟踪哪些驱动程序最接近哪些客户并确保确保您正在有效地派遣驱动程序。

下面的示例数据演示了乘车共享应用程序生成的典型数据流:
驱动程序数据流
| 驱动程序_id | 位置 | 速度 | 评分 | event_timestamp |
|---|---|---|---|---|
| 101 | 旧金山 | 60 | 4 | 2023-04-01 10:30:00 |
| 102 | 纽约 | 50 | 5 | 2023-04-01 10:33:00 |
| 103 | 洛杉矶 | 45 | 1 | 2023-04-01 10:31:00 |
| ... | ... | ... | ... | ... |
客户数据流
| customer_id | pickup_location | 目的地 | event_timestamp |
|---|---|---|---|
| 201 | 旧金山 | 帕洛阿尔托 | 2023-04-01 10:30:00 |
| 202 | 纽约 | 布鲁克林 | 2023-04-01 10:33:00 |
| 203 | 洛杉矶 | 圣莫尼卡 | 2023-04-01 10:31:00 |
| ... | ... | ... | ... |
为流源创建来源
您要做的第一件事是将流数据库连接到流源。来源是Risingwave可以从中读取数据的资源。流源可以是关系数据库中的两个表(MySQL,PostgreSQL或另一个),您可以是ingest data using Change Data Capture(CDC)和Risingwave built-in connector。或源可以是Kafka broker。您可以使用CREATE SOURCE命令在RisingWave中创建一个源。例如,drivers kafka主题的映射到RisingWave来源可能看起来像:
CREATE SOURCE driver_data (
driver_id BIGINT,
location VARCHAR,
speed BIGINT,
) WITH (
connector = 'kafka',
topic = 'driver_topic',
properties.bootstrap.server = 'message_queue:29092',
scan.startup.mode = 'earliest'
) ROW FORMAT JSON;
您也将有第二个来源。
流上的连续查询
之后,您可以像在普通的关系数据库中查询SQL一样查询它们,但是在流数据库中,随着新数据添加到源,数据是实时显示的。这个简单的 equijoin 查询将从两个数据流中选择所有字段,并根据位置字段加入它们。
SELECT driver_data.*, customer_data.*
FROM driver_data
JOIN customer_data
ON driver_data.location = customer_data.pickup_location
您可能需要在流数据库中持续存在所有与Rides相关的数据。您可以在数据库中创建一个新的表 rides ,其中包含有关每个乘车的信息,包括驱动程序ID,客户ID,拾取位置,下车位置和票价金额。在这种情况下,您希望使用基于驱动程序ID的 rides 表加入传入的连续 drivers 数据流。以下加入查询将使您可以将有关每个驾驶员位置的信息结合在一起,并与他们完成的骑行有关,以识别某些地理位置的最活跃的驾驶员。
SELECT driver_data.driver_id, driver_data.location, driver_data.rating, COUNT(ride_data.ride_id) as total_rides
FROM driver_data
JOIN ride_data
ON driver_data.driver_id = ride_data.driver_id
WHERE driver_data.location = 'San Francisco'
GROUP BY driver_data.driver_id, driver_data.location, driver_data.rating
ORDER BY total_rides DESC
结果:
| 驱动程序_id | 位置 | 评分 | total_rides |
|---|---|---|---|
| 101 | 旧金山 | 4 | 2 |
| ... | ... | ... | ... |
窗口加入Risingwave
有时您对任何时间间隔都对事件感兴趣。 window join是一种JOIN操作,通常用于流数据库中,可让您根据时间窗口加入两个数据流。 RisingWave提供两种类型的窗口:
例如,您可能需要在过去10分钟的滚动窗口上计算与客户接送位置一定距离内的驾驶员的平均速度。在这种情况下,您的SQL查询可能看起来像这样:
SELECT customer_data.*, AVG(driver_data.speed) AS avg_speed
FROM customer_data
JOIN driver_data
ON ST_DISTANCE(driver_data.location, customer_data.pickup_location) < 5
GROUP BY TUMBLE(customer_data.event_time, INTERVAL '10' MINUTE), customer_data.customer_id
结果:
| customer_id | pickup_location | 目的地 | event_time | avg_speed |
|---|---|---|---|---|
| 201 | 旧金山 | 帕洛阿尔托 | 2023-04-01 10:30:00 | 60.0 |
| 203 | 洛杉矶 | 圣莫尼卡 | 2023-04-01 10:31:00 | 45.0 |
| 202 | 纽约 | 布鲁克林 | 2023-04-01 10:33:00 | 50.0 |
此查询将从客户数据流中选择所有字段,并计算客户接收位置5公里以内驱动程序的平均速度。在此查询中, TUMBLE() 功能用于将数据分组为10分钟的翻滚时间窗口。 GROUP BY 子句在每个时间窗口和每个客户中汇总数据。
将合并的流写入实现的视图
使用RisingWave流数据库,您还可以为加入流创建实体视图。实现的视图是将数据库中存储为表格的数据快照。物质化的视图可能特别有用,因为它们允许您将多个流中的数据组合到单个表中,并且流数据库即时计算查询结果,并随着新数据到达而更新虚拟表。这可以简化复杂的查询,提高整体系统性能和响应能力,并提供更全面的数据,更易于使用。
在Risingwave中,您需要使用CREATE MATERIALIZED VIEW语句来创建实体的来源。这是可以通过合并 Driver 和 Rider 流在上面的乘车共享数据示例中创建的实现视图的示例。
CREATE MATERIALIZED VIEW most_active_drivers AS
SELECT drivers.driver_id, drivers.location, drivers.rating, COUNT(rides.ride_id) as total_rides
FROM drivers
JOIN rides
ON drivers.driver_id = rides.driver_id
WHERE drivers.location = 'San Francisco'
GROUP BY drivers.driver_id, drivers.location, drivers.rating
ORDER BY total_rides DESC
实现的视图结果:
| 驱动程序_id | 位置 | 评分 | total_rides |
|---|---|---|---|
| 101 | 旧金山 | 4 | 2 |
| 104 | 旧金山 | 3 | 1 |
要点
- 使用流数据库,您可以通过从不同的数据源摄入两个或多个流。
- 您可以通过表reference,type和表函数加入表。
- 也可以使用“窗口”窗口(例如Tumble或hop)加入多个流。 。
- 所得流将包含来自所有流的组合数据,这意味着此操作执行昂贵的计算。在这种情况下,您可以创建一个实现的视图来加快查询性能。
相关资源
- Shared Indexes and Joins in Streaming Databases
- How Change Data Capture (CDC) Works with Streaming Database.
- Query Real-Time Data in Kafka Using SQL.
建议的内容
社区
1 at 17 Join the Risingwave Community
关于作者
访问我的个人博客:www.iambobur.com