在当今的数字时代,搜索引擎已成为个人毫不费力,迅速地访问任何主题的信息。
本文旨在提供逐步指南,以使用文本嵌入在Python中构建搜索引擎。单词嵌入式将文本编码为数值格式,以测量两个文本之间的相似性。
通过遵循本教程,您将能够使用Eden AI嵌入来构建自己的搜索API,然后轻松将其部署为烧瓶。
先决条件:
- python的基本知识
- 熟悉API
- abiaoqian 0(api键)
步骤1.准备数据集
首先,准备数据集。出于本教程的目的,我们将使用40个AI功能的数据集,其中每个功能都用简短的文本描述描述。数据集可以以任何格式使用,但是为简单起见,我们将使用CSV文件。这是数据集可能外观的示例:
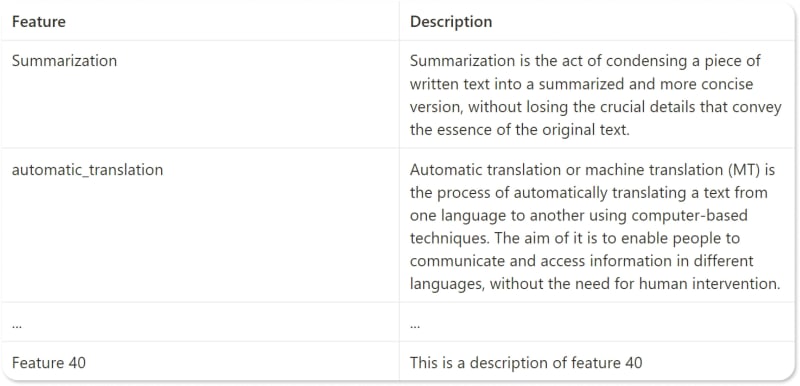
edenai_dataset = pd.read_csv('edenai_dataset.csv')
步骤2。使用Eden AI API生成嵌入。
Eden AI提供了广泛的API集合,其中包含预训练的嵌入方式。对于本教程,我们将使用Open AI将文本描述转换为数值表示。本教程适用于其他提供商,例如Cohere(也可在Eden AI上使用)。但是,请记住,当将您的文本表示为嵌入式时,您只能使用一个提供商,而不是合并来自多个提供商的嵌入。
# Load your dataset
edenai_dataset = pd.read_csv('edenai_dataset.csv')
# Apply embeddings to your dataset
subfeatures_description['description-embeddings'] = subfeatures_description.apply(lambda x: edenai_embeddings(x['Description'], “openai”), axis=1)
在上面的代码中,我们将Eden AI的嵌入式API应用于数据集中的“描述”列的每一行,并将结果嵌入在一个新列中保存在称为“ Description-embeddings”的新列中。
这是使用Eden AI API生成嵌入的代码:
def edenai_embeddings(text : str, provider: str):
"""
This function sends a request to the Eden AI API to generate embeddings for a given text using a specified provider.
"""
url = "https://api.edenai.run/v2/text/embeddings"
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer YOUR_API_KEY"
}
payload = {
"response_as_dict": True,
"attributes_as_list": False,
"texts": [text],
"providers": provider
}
response = requests.post(url, json=payload, headers=headers).json()
try:
return response[provider]['items'][0]['embedding']
except:
return None
注意:不要忘记用实际的伊甸AI API键代替。
步骤3.用烧瓶构建搜索API
现在,我们已经对数据集的每个描述进行了嵌入,我们可以使用烧瓶构建REST API,允许用户根据其查询搜索数据集中的功能。
为烧瓶项目创建虚拟环境
首先,您需要为烧瓶项目创建虚拟环境并安装所需的依赖项。完成以下步骤:
-
打开命令行界面并导航到要创建烧瓶项目的目录。
-
使用命令 python3 -m venv 创建一个新的虚拟环境。用您选择的名称替换 ,它将用自己的python解释器和安装软件包创建一个新的虚拟环境,与系统的python安装分开。
-
通过运行命令源/bin/activate 。
来激活虚拟环境
-
通过运行以下命令安装项目所需的依赖项:
pip install flask
pip install pandas
pip install requests
pip install numpy
pip install flask-api
5.在您的项目中导入数据集并创建两个Python文件搜索。Py将具有我们的搜索逻辑和app.py for Rest API。这是我们项目的结构:

6.在“ search.py”文件中,我们将实施调用伊甸AI嵌入式API的过程(该过程已显示为前面),并计算余弦相似性。
def cosine_similarity(embedding1: list, embedding2: list):
"""
Computes the cosine similarity between two vectors.
"""
vect_product = np.dot(embedding1, embedding2)
norm1 = np.linalg.norm(embedding1)
norm2 = np.linalg.norm(embedding2)
cosine_similarity = vect_product / (norm1 * norm2)
return cosine_similarity
- 我们的目标是将用户的搜索查询转换为嵌入,然后读取数据集,以测量查询嵌入和子图描述嵌入之间的余弦相似性。我们的输出将根据其相似性分数的分类列表,从最相似的开始:
def search_subfeature(description: str):
"""
This function searches a dataset of subfeature descriptions and returns a list of the subfeatures
with the highest cosine similarity to the input description.
"""
# load the subfeatures dataset into a pandas dataframe
subfeatures = pd.read_csv('subfeatures_dataset.csv')
# generate an embedding for the input description using the OpenAI provider
embed_description = edenai_embeddings(description, 'openai')
results = []
# iterate over each row in the subfeatures dataset
for subfeature_index, subfeature_row in subfeatures.iterrows():
similarity = cosine_similarity(
ast.literal_eval(subfeature_row['Description Embeddings']),
embed_description)
# compute the cosine similarity between the query and all the rows in the corpus
results.append({
"score": similarity,
"subfeature": subfeature_row['Name'],
})
results = sorted(results, key=lambda x: x['score'], reverse=True)
return results[:5]
- 在app.py中,我们将创建烧瓶项目的实例,并定义数据集中搜索子功能的终点。此端点将调用search_subfeature()函数,该功能将描述(查询)作为输入。
from search import search_subfeature
from flask import Flask, request, jsonify
from flask_api import status
app = Flask(__name__)
@app.route('/search', methods=['GET'])
def search_engine():
search_result = search_subfeature(request.args.get('description'))
return jsonify(search_result), status.HTTP_200_OK
if __name__ == "__main__":
app.run(debug=True)
- 最后,通过运行命令烧瓶 - app app.py-debug run 。。 来启动烧瓶应用程序
如果一切成功运行,您应该在命令行界面中看到一条消息,上面说“在http://127.0.0.1:5000/上运行”。
要测试我们的搜索engin api,我们可以将get请求发送到带有查询作为有效载荷的端点的 http://127.0.0.1:5000/search 。我们可以轻松发送HTTP请求并查看响应。
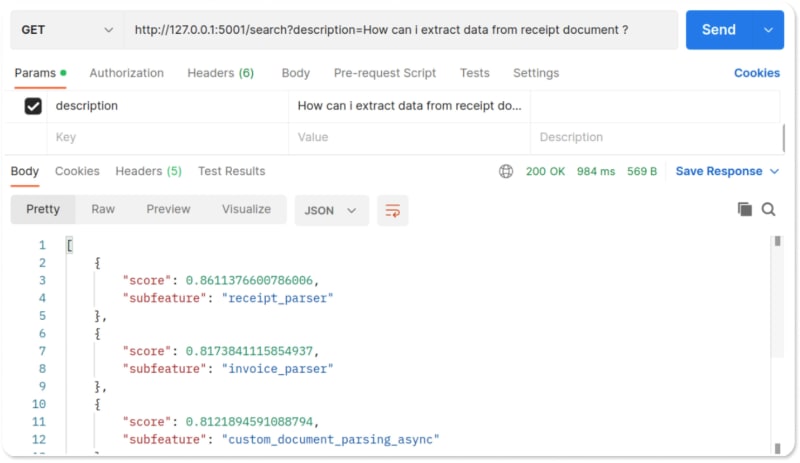
查询“如何从收据文档中提取数据?”的最相关结果?确实是 receipt_parser subfeature。
您可以在此GitHub存储库中访问完整代码:https://github.com/Daggx/embedding-search-engine