通过在YouTube上观看问题的艺术,我受到了它的启发,并想创建有关此主题的博客文章。因此,在这里,我们将致力于如何使用图形数据库创建推荐系统。为此,我们将使用Apache Age,这是PostgreSQL的开源扩展,使我们能够创建节点和边缘。
创建图形
鉴于对用户过去活动的观察,我们需要预测用户可能喜欢的其他内容。我们可以将用户偏好以图形方式表示为People之间的连接以及他们对Movies等评级或意见的事物。我们要使用的方法称为内容过滤,它使用我们知道的有关人员和事物作为结缔组织的信息进行建议。
-- Creating the graph.
SELECT create_graph('RecommenderSystem');
-- Adding user.
SELECT * FROM cypher('RecommenderSystem', $$
CREATE (:Person {name: 'Abigail'})
$$) AS (a agtype);
-- Adding movies.
SELECT * FROM cypher('RecommenderSystem', $$
CREATE (:Movie {title: 'The Matrix'}),
(:Movie {title: 'Shrek'}),
(:Movie {title: 'The Blair Witch Project'}),
(:Movie {title: 'Jurassic Park'}),
(:Movie {title: 'Thor: Love and Thunder'})
$$) AS (a agtype);
-- Adding categories.
SELECT * FROM cypher('RecommenderSystem', $$
CREATE (:Category {name: 'Action'}),
(:Category {name: 'Comedy'}),
(:Category {name: 'Horror'})
$$) AS (a agtype);
我们可以在用户和类别之间的边缘以及电影和categoires之间的边缘上与称为rating的属性的连接强度。该评分在0到4之间的变化,其中0表示用户讨厌电影,而4表示用户喜欢这部电影。这也适用于类别和电影,其中0的可能性较小,而4最有可能拥有。
假设Abigail具有3的评级为Comedy,1 for Action和0 for Horror。
-- User preferences.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (a:Person {name: 'Abigail'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (a)-[:RATING {rating: 3}]->(C),
(a)-[:RATING {rating: 1}]->(A),
(a)-[:RATING {rating: 0}]->(H)
$$) AS (a agtype);
每个电影也以相同的方式映射到每个类别。例如,矩阵没有喜剧,动作很多,也没有恐怖。
-- The Matrix and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (matrix:Movie {title: 'The Matrix'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (matrix)-[:RATING {rating: 0}]->(C),
(matrix)-[:RATING {rating: 4}]->(A),
(matrix)-[:RATING {rating: 0}]->(H)
$$) AS (a agtype);
-- Shrek and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (shrek:Movie {title: 'Shrek'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (shrek)-[:RATING {rating: 4}]->(C),
(shrek)-[:RATING {rating: 2}]->(A),
(shrek)-[:RATING {rating: 0}]->(H)
$$) AS (a agtype);
-- The Blair Witch Project and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (witch:Movie {title: 'The Blair Witch Project'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (witch)-[:RATING {rating: 0}]->(C),
(witch)-[:RATING {rating: 0}]->(A),
(witch)-[:RATING {rating: 4}]->(H)
$$) AS (a agtype);
-- Jurassic Park and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (jurassic:Movie {title: 'Jurassic Park'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (jurassic)-[:RATING {rating: 1}]->(C),
(jurassic)-[:RATING {rating: 3}]->(A),
(jurassic)-[:RATING {rating: 0}]->(H)
$$) AS (a agtype);
-- Thor: Love and Thunder and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $$
MATCH (thor:Movie {title: 'Thor: Love and Thunder'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (thor)-[:RATING {rating: 4}]->(C),
(thor)-[:RATING {rating: 2}]->(A),
(thor)-[:RATING {rating: 0}]->(H)
$$) AS (a agtype);
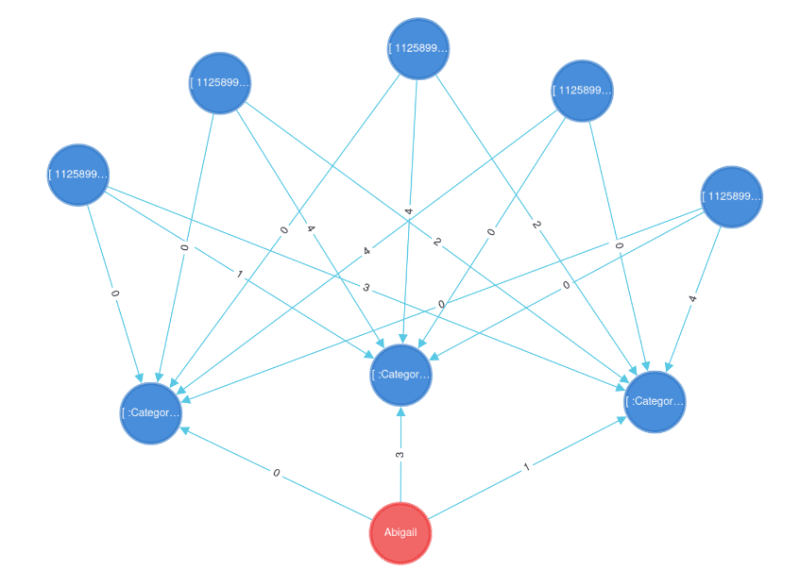
内容过滤方法
要确定某人会喜欢电影的人,我们需要将这些因素乘以将其乘以44的类别数量。
-- The Matrix estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $$
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'The Matrix'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$$) AS (e1 float, ct agtype);
factor
-------------------
0.333333333333333
(1 row)
我们可以表示Abigail和矩阵之间连接的强度为:[(3 x 0) +(1 x 4) +(0 x 0)] / 12 = 0.3。我们的估计是她不会那么喜欢这部电影。现在,我们需要收集所有其他电影的数据,以便向最适合她兴趣的数据显示。
-- Shrek's estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $$
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Shrek'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$$) AS (e1 float, ct agtype);
factor
------------------
1.16666666666667
(1 row)
-- The Blair Witch Project estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $$
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'The Blair Witch Project'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$$) AS (e1 float, ct agtype);
factor
--------
0.0
(1 row)
-- Jurassic Park estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $$
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Jurassic Park'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$$) AS (e1 float, ct agtype);
factor
--------
0.5
(1 row)
-- Thor: Love and Thunder estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $$
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Thor: Love and Thunder'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$$) AS (e1 float, ct agtype);
factor
------------------
1.16666666666667
(1 row)
尽管她的茶水不多,但史瑞克和雷神将是我们列表中的电影,根据我们的图形分析,阿比盖尔更喜欢观看。
结论
我们展示了如何使用Apache Age创建图形数据库的推荐系统。可以扩展此方法以适应更复杂的方案,例如合并用户人口统计,搜索历史记录或社交网络连接。图形数据库非常适合推荐系统,因为它们可以轻松地表示用户与项目之间的关系以及这些实体的属性。此外,使用SQL和Cypher查询语言使使用大型数据集并执行复杂的查询变得更加容易。总体而言,我们希望这篇文章为那些有兴趣使用图形数据库构建推荐系统的人提供了一个起点。
如果您想了解有关Apache Age的更多信息,请查看下面的链接: