tl; dr
- 如果jvmargs属性指定了垃圾收集器的类型,则不会由Kotlin进程继承
- 将Kotlin过程的平行与G1进行比较时,实验表明:
- 22%kotlin编译了汇总任务时间改进
- 60%垃圾收集器的时间改进Kotlin过程
- 减少Kotlin过程内存使用量的51%使用
- 结果基于短暂剂(CI)的构建。请,在采用这种配置之前,请测量您的构建!
语境
本文的想法是在研究Android构建中Kotlin过程中JVM论点的行为时诞生的。该理论说,如果没有针对Kotlin过程指定任何论点,它将继承Gradle守护程序的论点:
org.gradle.jvmargs=-Xmx500m
我们将检索该过程的PID:
jps | grep KotlinCompileDaemon | sed 's/KotlinCompileDaemon//' | xargs jinfo
结果是:
VM Flags:
-XX:MaxHeapSize=528482304
但是,当我们设置收集器的类型时:
org.gradle.jvmargs=-Xmx3g -XX:+UseParallelGC
为Kotlin过程定义的垃圾收集器是:
-XX:+UseG1GC
在这种情况下,我们需要明确声明Kotlin过程的GC类型:
kotlin.daemon.jvmargs=-Xmx3g -XX:+UseParallelGC
,我注意到我注意到JVM参数优化的参考文献始终集中在Gradle过程上,而无需讨论我们的构建的主要组成部分之一:Kotlin流程。
本文解释了在Gradle/Kotlin过程中测量垃圾收集器不同组合的结果。
实验
环境
- Linux 5.15.0-1035-Zure(AMD64)
- 2 CPU内核
- 2 Gradle工人
- 3 GB内存堆大小
- github动作代理
项目
- nowinandroid(提交67dae0c3c09f22745ccb8c4087a0f2ea69125d9f-04/11)
- JDK 11
- gradle 7.6
- AGP 7.4.1
- kgp 1.8.0
- HILT 2.44.2
实验变体
| id | gradle gc | kotlin gc |
|---|---|---|
| gg_kg | g1 | g1 |
| gp_kg | ParallelGC | g1 |
| gg_kp | g1 | ParallelGC |
| gp_kp | ParallelGC | ParallelGC |
方法
- 每个变体都运行40个Gradle Profiler方案
- 每个场景都有一个热身,五个构建
- 每个场景都应用了一个Gradle Profiler方案,并在模块
core:datastore上具有ABI变化(项目依赖关系图中的最高中间性中心性)。 - 每种情况执行的任务是
clean :app:assembleDebug - 这种类型的方案为每个执行生成:
- 在25个项目中执行的512个任务
- 24个Kotlin编译器任务在12个项目中执行
- 26个Java编译器任务在12个项目中执行
- 我们忽略了热身,并在每个执行的所有结果中首次构建
结果
我们通过:
对结果进行了分组- 建立持续时间
- kotlin编译任务持续时间
- kotlin过程的GC时间
- 使用Kotlin流程
构建
数据是从每个Gradle Profiler执行的输出中提取的数据,以毫秒为单位的持续时间

均值为变体

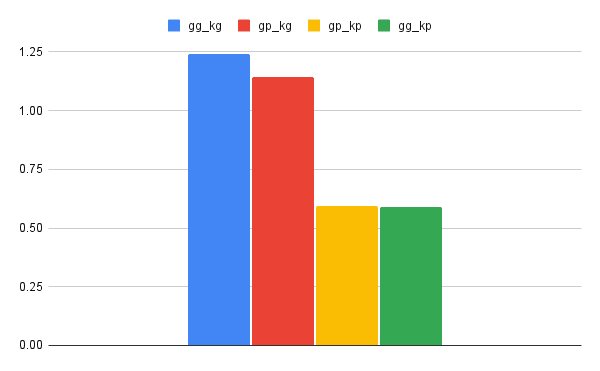
Kotlin编译器
我们使用Gradle Enterprise API,毫秒持续时间汇总了Kotlin编译器任务的构建时间:

均值为变体
Kotlin过程
使用插件InfoKotlin进程,我们检索了Kotlin进程的最后一个构建方案的信息
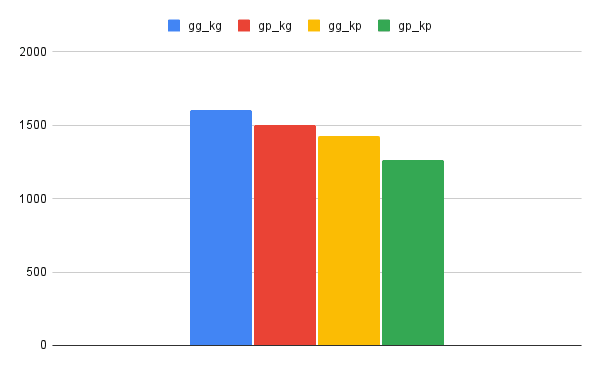
GC时间
垃圾收集器时间为几分钟:

均值为变体
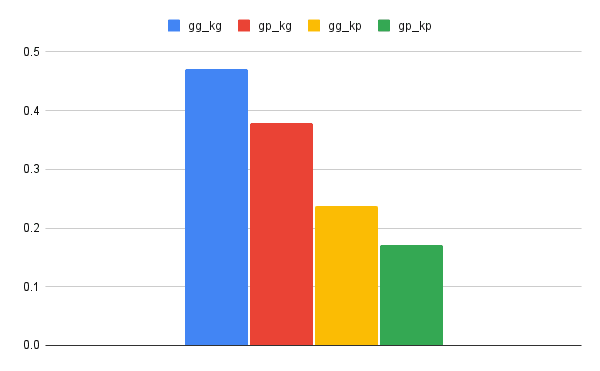
用法
GB中的Kotlin流程使用情况:

均值为变体
最后一句话
在使用kotlin过程中使用平行的实验中,我们显示了与G1相比的好处。
同样,本文的目的不是让您有理由使用ParallealGC创建PR。您需要衡量项目中重要的内容,CI管道可能包含带有R8任务或无尽测试任务的昂贵构建,我们只介绍assembleDebug。
最后,如您所知,使用AGP 8,JDK设置为17。我将发表一篇新文章,涵盖JDK 17垃圾收集器结果。
快乐建筑!