如今,我们拥有各种数据库,旨在满足我们的特定数据要求。尽管通常使用传统的关系数据库,但是NOSQL数据库的灵活性和可扩展性使它们越来越流行。这些数据库有各种类型,包括文档数据库,钥匙值商店和列户商店。在NOSQL数据库中,图数据库的普及正在上升。该博客将深入研究图形数据库和其他NOSQL数据库之间的差异,以检查其工作。此外,我们将讨论Graph和NOSQL数据库的用例,使您更好地了解哪种数据库类型最适合您的项目。
目录
- NoSQL Databases
- When to Use NoSQL Databases?
- How do NoSQL Databases work?
- How to use NoSQL Databases?
- Graph Database
- How do Graph Databases work?
- When to Use Graph Databases?
- How to use Graph Databases?
NOSQL数据库
NOSQL数据库是非关系数据库,不使用结构化查询语言(SQL)进行数据操作。相反,他们使用其他数据模型进行访问和数据存储。 SQL数据库通常用于处理结构化数据,但它们可能不是处理非结构化或半结构化数据的最佳选择。
NOSQL数据库提供了快速有效地存储和检索大量数据的能力。它们支持多种数据类型,例如层次数据,文档,图形和键值对。 NOSQL数据库的常见示例包括文档数据库和键值商店。
什么时候使用NOSQL数据库?
NOSQL数据库适用于传统SQL数据库可能不是最合适的特定用例。在某些情况下,NOSQL数据库可能是有益的:
处理大规模数据
NOSQL数据库最适合处理非结构化或半结构化的大规模数据。这可能是不遵循严格格式的数据,例如社交媒体帖子,用户生成的内容,物联网设备数据或机器日志。 NOSQL数据库旨在处理大量数据,并且具有高度可扩展的数据。
高可伸缩性
当您必须处理需要处理数千个或更多并发连接的数据库,或者需要处理和存储迅速流动和更改的数据时,NOSQL数据库的运行良好。它们提供自动分解,复制和其他功能,可帮助扩展数百或数千个商品服务器。
更改数据模式的灵活性
NOSQL数据库具有很高的灵活性,并且可以适应数据模式的更改,因为它们不执行传统关系数据库施加的一致性规则。这意味着,与SQL数据库相比,在NOSQL数据库中更新或添加新字段在数据模型中要容易得多。这使NOSQL数据库成为需要快速调整其数据模型以适应新类型的数据或不断变化业务需求的企业的绝佳选择。
成本效益的缩放
使用NOSQL数据库的另一个重要原因是节省与扩展相关的成本。由于NOSQL数据库可以在多个商品服务器上水平扩展,因此与需要垂直缩放的传统SQL数据库相比,它们通常是更具成本效益的解决方案,该数据库涉及购买更强大的硬件。随着数据的增长,您可以轻松地在NOSQL群集中添加更多服务器以满足需求。
NOSQL数据库如何工作?
NOSQL数据库,也称为non-relational databases,旨在处理大量非结构化或半结构化数据。术语“ NOSQL”不仅代表“ SQL”,它指的是NOSQL数据库不仅限于传统关系数据库使用的结构化查询语言(SQL)。
NOSQL数据库使用多种数据模型来存储和访问数据。一些常见的数据模型包括:
-
文档数据库:将数据存储在半结构化文档中,通常采用JSON或XML格式。文档数据库的示例包括MongoDB和Couchbase。
-
键值数据库:将数据存储为键值对的集合,其中键是数据的唯一标识符。键值数据库的示例包括Riak和Redis。
-
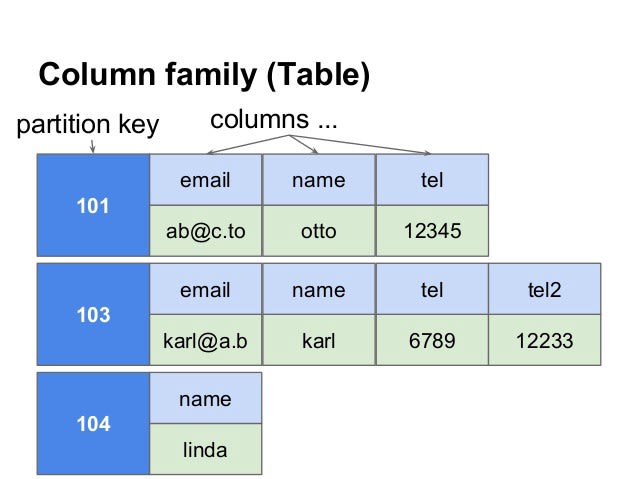
列 - 家庭数据库:将数据存储为列族,其中每个列族包含一组相关的列。柱家庭数据库的示例包括Apache Cassandra和HBase。
-
图形数据库:将数据存储为节点和边缘,其中节点代表实体和边缘代表实体之间的关系。图形数据库的示例包括Neo4J和OrientDB。
NOSQL数据库具有高度可扩展性,可以在多个服务器上处理大量数据。它们通常在大数据应用程序中用于存储和处理大量非结构化数据,例如社交媒体供稿,用户生成的内容和点击流数据。
如何使用NOSQL数据库?
要将NOSQL数据库与代码一起使用,您首先需要选择适合您需求的NOSQL数据库。 NOSQL数据库的一些流行示例是MongoDB,Cassandra,Redis和DynamoDB。这些数据库中的每一个都有自己的API集和驱动程序,可用于与它们进行交互。在这里,我将以MongoDB为例,并解释如何使用Python及其PyMongo软件包执行CRUD操作。
设置MongoDB
首先,您需要在系统上安装mongoDB。您可以参考官方MongoDB documentation,以获取有关如何执行此操作的说明。
安装了mongoDB后,您可以通过在终端中运行以下命令来开始它:
mongod
使用Python连接到MongoDB
接下来,您需要安装pymongo库,这是MongoDB的官方Python客户库。您可以使用PIP安装它:
pip install pymongo
安装pymongo后,您可以使用以下代码连接到MongoDB实例:
import pymongo
# Create a MongoClient
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Create a database
db = client["your_datebase_name"]
此代码创建一个MongoClient对象,该对象代表系统上的mongoDB实例,而MongoDatabase对象则代表该实例中的数据库。
创建一个集合和插入文档
连接到数据库后,您可以使用以下代码在该数据库中创建集合:
# Create a collection
collection = db["mycollection"]
此代码创建一个MongoCollection对象,该对象代表数据库中的集合。然后,您可以使用此对象使用insert_one或insert_many方法将文档插入集合中:
# Insert a single document
document = {"name": "John", "age": 30}
result = collection.insert_one(document)
print(result.inserted_id)
# Insert multiple documents
documents = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 35},
{"name": "Charlie", "age": 45}
]
result = collection.insert_many(documents)
print(result.inserted_ids)
insert_one方法将单个文档插入集合中,并返回包含有关操作信息的InsertOneResult对象。该对象的inserted_id属性包含插入文档的_id。
insert_many方法将多个文档插入集合中,并返回包含有关操作信息的InsertManyResult对象。此对象的inserted_ids属性包含插入文档的_id值的列表。
从收藏中读取文档
要从集合中检索一个或多个文档,您可以使用find方法:
# Find a single document
query = {"name": "John"}
document = collection.find_one(query)
print(document)
# Find multiple documents
query = {"age": {"$gt": 30}}
documents = collection.find(query)
for document in documents:
print(document)
find_one方法从集合中检索一个文档,该文档与查询匹配并返回代表文档的dict对象。
find方法从匹配查询的集合中检索多个文档,并返回一个可以用来迭代文档的Cursor对象。 query参数是指定查询条件的dict对象。在第二个示例中,查询检索了age字段大于30的所有文档。
更新集合中的文档
要更新集合中的一个或多个文档,您可以使用update_one或update_many方法:
# Update a single document
query = {"name": "John"}
new_value = {"$set": {"age": 32}}
result = collection.update_one(query, new_value)
print(result.modified_count)
# Update multiple documents
query = {"age": {"$lt": 30}}
new_value = {"$inc": {"age": 1}}
result = collection.update_many(query, new_value)
print(result.modified_count)
第一个示例使用update_one方法更新与查询相匹配的集合中的单个文档。 query参数指定了选择要更新文档的条件,并且new_value参数指定了对文档进行的更改。在这里,$set操作员用于将age字段设置为32。
第二个示例使用update_many方法更新匹配查询的集合中的多个文档。在这种情况下,$lt操作员用于选择age字段小于30的文档,并且使用$inc运算符将age字段递增为1。
从集合中删除文档
要从集合中删除一个或多个文档,您可以使用delete_one或delete_many方法:
# Delete a single document
query = {"name": "John"}
result = collection.delete_one(query)
print(result.deleted_count)
# Delete multiple documents
query = {"age": {"$gt": 40}}
result = collection.delete_many(query)
print(result.deleted_count)
第一个示例使用delete_one方法从与查询匹配的集合中删除单个文档。该方法返回的DeleteResult对象的deleted_count属性指示已删除的文档数量。
第二个示例使用delete_many方法从与查询匹配的集合中删除多个文档。在这里,$gt操作员用于选择age字段大于40的文档。
优点
-
NOSQL数据库具有高度可扩展性,设计用于处理大量数据和复杂的查询。
-
他们提供了一个灵活的数据模型,该模型可以轻松添加或删除字段而不更改数据库模式。
-
NOSQL数据库可以比关系数据库更快地处理大量的交易。
-
它们通常比关系数据库便宜,因为它们可以在低成本商品硬件上运行。
缺点:
-
NOSQL数据库可能无法提供像连接或酸性交易之类的功能,这对于某些用例而言可能是一个问题。
-
与关系数据库不同,NOSQL数据库没有明确的标准,这可能会导致数据一致性和可移植性的问题。
-
与SQL数据库相比,NOSQL数据库具有较小的开发人员和用户社区,这意味着可用的资源和支持更少。
-
由于其设计和用例不同,NOSQL数据库具有更陡峭的学习曲线,并且需要专门的技能才能有效运行。
图数据库
图形数据库是一种数据库,该数据库以节点和边缘来存储数据。数据以非常灵活的方式存储,而无需遵循预定义的模型。该图形成两个节点之间的关系,可以指向或无方向性。这些数据库旨在处理数据/节点之间的复杂关系。
节点用于存储数据。每个节点都包含一组属性,这些属性提供了有关节点本身的信息。
边缘存储两个节点或实体之间的关系。边缘总是具有起始和结束节点。

图数据库如何工作?
与依靠表和列的传统关系数据库不同,图形数据库使用无模式的结构。这意味着没有预定义的表或列,并且可以以灵活,可扩展和高效的方式存储数据。
图形数据库使用各种类型的数据模型,包括属性图和RDF(资源描述框架)图。在属性图中,每个节点和边缘可以具有多个属性,它们是描述节点或边缘属性的键值对。在RDF图中,节点和边缘表示为URI(统一资源标识符),并使用三重态(主题,谓词,对象)表示实体之间的关系。
图形数据库通常使用查询语言,例如Cypher或Gremlin来遍历图形,查询数据和更新数据。这些查询语言设计为用户友好,使工程师可以轻松地使用图形数据库。
什么时候使用图形数据库?
涉及复杂数据时,使用图形数据库。它们对于需要对实体之间的建模和查询关系的应用程序特别有用,例如在社交网络,推荐引擎和欺诈检测系统中。
社交网络
我们知道社交网络非常复杂且高度联系。他们遵循非常复杂的数据结构。他们遵循用户帖子,评论和其他实体之间的关系。图形数据库允许用户轻松地穿越图形并发现实体之间。
这是一个示例,说明如何在社交网络中使用图形数据库:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create user node with attributes
user = Node("User", name="John Doe", age=25, location="New York", interests=["programming", "video games"])
# add user node to graph
graph.create(user)
以上代码创建一个用户节点,该节点具有诸如名称,年龄,位置和兴趣的属性,并将其添加到图数据库中。
推荐引擎
建议引擎是机器学习算法,用于根据用户以前的动作,偏好和行为向用户推荐项目。它们通常用于电子商务网站,流媒体平台和社交媒体网站,以向用户提供个性化建议。
图形数据库可用于推荐引擎中,以更有效地表示和处理数据。图形数据库旨在存储实体之间和查询关系,这是推荐引擎的基本方面。这是如何在推荐引擎中使用图形数据库的示例:
假设我们想构建电影推荐引擎。我们可以将电影和用户表示为图中的节点,并使用边缘表示电影评分和用户偏好等关系。
每个电影节点都可以具有标题,类型,导演和演员等属性。每个用户节点都可以具有年龄,性别和位置等属性。节点之间的边缘可以表示不同类型的关系。例如,“观察”边缘可以将用户节点连接到电影节点,其评分属性代表用户的评级。
通过使用图形数据库,我们可以轻松查询图形以为特定用户提出建议。例如,我们可以找到类似用户评分的电影,或者找到与用户评分高的电影有关的电影。
这是如何使用Python软件包py2neo添加电影节点的示例:
from py2neo import Graph, Node
# set up graph connection
graph = Graph()
# create movie node with attributes
movie = Node("Movie", title="The Matrix", genre="Science Fiction", director="Lana Wachowski", actors=["Keanu Reeves", "Carrie-Anne Moss"])
# add movie node to graph
graph.create(movie)
上面代码创建一个带有标题,类型,导演和演员等属性的电影节点,并使用py2neo软件包将其添加到图形数据库中。您可以在同一图中添加更多节点。
欺诈检测系统
FD需要能够通过各种模式来识别可疑行为。图数据库在欺诈检测中非常有用,因为它们可以分析关系并确定可能表明骗局的关系。
这是Cypher中的一个示例,它可以从不同商人中检索所有涉及相同信用卡的交易:
MATCH (c:CreditCard)-[:USED_FOR]->(t:Transaction)-[:AT_MERCHANT]->(m:Merchant)
WITH c, m, COUNT(t) AS tx_count
WHERE tx_count > 1
RETURN c.number, m.name, tx_count
该查询的作用是与不同商人交易的所有信用卡匹配,并返回信用卡号,商户名和涉及该信用卡的交易数量。这可能有助于确定骗局。
如何使用图形数据库?
现在,您知道什么是图形数据库以及它们的工作方式以及何时可以使用它们。现在问题出现了:“好吧,这很酷,但是我该怎么使用呢?”您需要遵循一些步骤来使用图形数据库 -
选择图形数据库软件
首先,您需要选择一个特定的图形数据库平台来使用,例如Neo4j,OrientDB,JanusGraph,Arangodb或Amazon Neptune。选择平台后,您可以使用平台的查询语言开始使用图形数据。
计划您的图形模型
选择数据库软件后,定义实体及其之间的关系。您可以使用纸,笔或图表工具来创建图形模型的视觉表示。
创建图形数据库
最终确定图形模型后,在图形数据库软件中创建一个新的数据库实例。根据软件,您可以使用命令行或GUI创建一个新的数据库实例。
定义模式
在将节点和边缘添加到图形数据库之前,请定义架构。该模式定义了实体和关系类型,属性及其数据类型。大多数图形数据库软件都支持动态架构更新。 (我知道我说“这是一个无模式的结构”,但最好定义概述结构)
添加节点和边缘
节点表示图形数据库中的实体,边缘表示实体之间的关系。您可以使用软件的特定语言(例如Cypher
)添加节点和边缘
CREATE (user:User {name: 'Jatin'})
CREATE (article:Article {title: 'Graph Databases vs. Relational Databases'})
CREATE (user)-[:WROTE]->(article)
以上代码创建了两个节点,一个节点带有标签“用户”,一个带有标签“文章”的节点,然后使用书面关系类型在两个节点之间创建一个关系。
查询数据
要查询数据,您可以在Cypher中使用MATCH子句。例如,要查找Jatin所写的所有文章,您可以使用以下代码:
MATCH (user:User {name: 'Jatin'})-[:WROTE]->(article:Article)
RETURN article.title
更新数据
要更新数据,您可以在Cypher中使用SET子句。例如,要将带有ID 47的文章标题更新为“图数据库”,您可以使用以下代码:
MATCH (article:Article {id: 47})
SET article.title = 'Graph Databases'
删除数据
要删除数据,您可以在Cypher中使用DELETE子句。例如,要删除具有ID 47的文章节点以及连接到节点的任何关系,您可以使用以下代码:
MATCH (article:Article {id: 47})
DETACH DELETE article
此代码首先匹配文章节点,然后在删除节点本身之前将任何连接到节点的关系分离。
优点
-
它们非常灵活地处理复杂的数据和关系。
-
他们使用图形遍历浏览大量互连数据。
-
它们也可以水平扩展,这意味着添加更多的机器来处理越来越多的数据。
-
图形数据库可以同时支持查询时对大或小数据进行实时更新。
缺点
-
它们对于整齐地适合表和行的结构化数据可能不那么有效。
-
它们更复杂,可能需要比关系数据库更多的知识。
包起来
NOSQL数据库和图形数据库都有不同的优势和劣势,并且选择使用的选择取决于您应用程序的特定要求。
NOSQL数据库是需要大量数据的应用程序的理想选择。它们与结构化和半结构化数据合作,可以轻松地分配,分布和复制。 NOSQL数据库的示例包括MongoDB,Cassandra和DynamoDB等。
另一方面,图形数据库非常适合需要复杂且高度连接的数据结构(例如社交网络,推荐引擎和欺诈检测系统)的应用程序。它们还可以与任何具有复杂且相互联系的关系的数据集配置得很好。图数据库的示例包括Neo4J,OrientDB和ArangodB等。
总而言之,NOSQL数据库和图形数据库都有其自己的位置和使用情况。重要的是根据数据的结构和复杂性,所需的性能和可伸缩性以及其他因素(例如成本和易用性)选择最适合您应用程序需求的数据库类型。
如果您想对这些或其他主题进行更多解释,请在评论部分中告诉我。而且不要忘记给文章。我会在下一个见到你。同时,您可以在这里关注我:
