Python无头浏览器是一种可以平稳刮擦动态内容的工具,而无需真正的浏览器。它将降低刮擦成本并扩展您的爬行过程。
使用基于浏览器的解决方案的网络刮擦可帮助您处理需要JavaScript的网站。另一方面,网络刮擦可能是一个漫长的过程,尤其是在处理复杂网站或大量数据列表时。
在本指南中,我们将介绍Python无头浏览器,其类型,优点和缺点
。让我们深入研究!
什么是Python中的无头浏览器?
无头浏览器是一个没有图形用户界面(GUI)的Web浏览器,但是真实浏览器的功能。
它具有所有标准功能,例如处理JavaScript,单击链接等。Python是一种编程语言,可让您享受其完整功能。
您可以自动化浏览器并使用Python无头浏览器学习语言。它还可以节省您在开发和刮擦阶段的时间,因为它使用较少的内存。
。Python无头浏览器的好处
任何无头浏览器过程都比真实浏览器使用的内存少。那是因为它不需要为浏览器和网站绘制图形元素。
此外,Python无头浏览器快速,可以尤其可以加快刮擦过程。例如,如果要从网站提取数据,则可以对刮板进行编程以从无头浏览器中获取数据,并避免等待页面完全加载。
它也允许多任务处理,因为您可以在无头浏览器在后台运行时使用计算机。
Python无头浏览器的缺点
Python无头浏览器的主要缺点是无法执行需要视觉交互的动作,并且很难进行调试。
因此,您无法检查元素或观察测试运行。
此外,您对用户通常如何与网站进行交互的想法非常有限。
Python硒无头
最受欢迎的Python无头浏览器是Python Selenium,其主要用途是自动化Web应用程序,包括Web刮擦。
python硒具有与浏览器和硒相同的功能。因此,如果可以无头操作浏览器,则可以python硒。
硒中包含哪些无头浏览器?
Chrome,Edge和Firefox是Selenium Python中的三个无头浏览器。这三个浏览器可用于无头部执行python硒。
1。无头铬硒python
从version 59开始,Chrome以无头能力运输。您可以从命令行调用Chrome二进制执行无头铬。
chrome --headless --disable-gpu --remote-debugging-port=9222 https://zenrows.com
2。边缘
此浏览器最初是用Microsoft的专有浏览器引擎EdgeHTML构建的。但是,在2018年底,它被重建为带有眨眼和V8发动机的铬浏览器,使其成为最好的无头浏览器之一。
3。 Firefox
Firefox是另一个广泛使用的浏览器。要打开无头Firefox,请在命令行或终端上键入命令,如下所示。
firefox -headless https://zenrows.com
您如何在Selenium Python中无头?
让我们看看如何通过python selenium headless无头部进行浏览器自动化。
在此示例中,我们将刮擦pokâ©yon细节,例如名称,链接和ScrapeMe的价格。
这是页面的样子。

先决条件
使用Python无头浏览器刮擦网页之前,让我们安装以下工具:
1。安装硒
安装Python后,让我们继续使用下面的命令代码在Python中安装Selenium。
pip install selenium
好消息大部分时间都是,python会自动安装硒,因此您不必担心。
2。安装WebDriver Manager
Python Selenium需要安装相同浏览器版本的Web驱动器。您可以下载并设置ChromeDriver与已安装的Chrome浏览器一起工作。
不幸的是,有一些缺点,例如忘记Webdriver二进制的特定路径或在WebDriver和浏览器之间具有不匹配的版本。
为了避免这些问题,我们将使用Webdriver Manager进行Python。库帮助您管理与环境相关的网络驱动器。
它将下载正确的WebDriver并提供与二进制文件的相关链接。因此,您无需明确地将其写入脚本。
您还可以使用PIP安装WebDrive Manager。只需打开命令行或终端并键入以下命令。
pip install webdriver-manager
现在,我们准备使用Python无头浏览器来刮擦一些pokâmon数据。让我们深入研究!
步骤1:打开页面
让我们编写一个打开页面的代码,以确认我们的环境已正确设置并准备好刮擦。
运行下面的代码将自动打开Chrome,然后转到目标页面。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) as driver:
driver.get(url)
页面应该像这样:
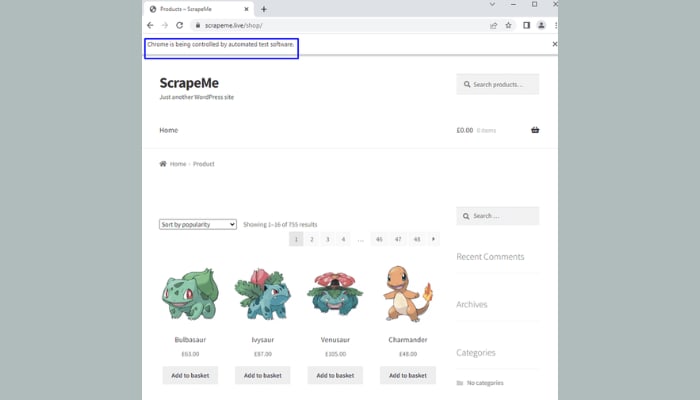
步骤2:切换到Python Selenium无头模式
页面打开后,其余过程将变得更容易。当然,我们不希望浏览器出现在显示器上,而是希望Chrome无头部运行。切换到Python中的无头铬很简单。
我们只需要添加两行代码并在调用WebDriver时使用选项参数。
# ...
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
# ...
完整的代码看起来像这样:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
options = webdriver.ChromeOptions() #newly added
options.headless = True #newly added
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver: #modified
driver.get(url)
如果您运行代码,您将在命令行或终端上看到少量信息。
不出现Chrome并入侵我们的屏幕。
很棒!
但是代码成功到达页面了吗?如何验证刮板是否打开正确的页面?有错误吗?当您执行python硒无头时提出了一些问题。
您的代码必须为解决上述问题创建尽可能多的日志。
日志可能会有所不同,这取决于您的需求。它可以是文本格式的日志文件,专用的日志数据库或终端上的简单输出。
为简单起见,我们将通过在终端上输出刮擦结果来创建日志。让我们在下面添加两行代码以打印页面URL和标题。这将确保python硒无需按需运行。
# ...
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
# ...
print("Page URL:", driver.current_url)
print("Page Title:", driver.title)

我们的爬行者不会获得意想不到的结果,这真是太神奇了。既然了,让我们刮一些poké©mon Data。
步骤3:刮擦数据
在深入之前,我们需要找到使用真实浏览器来检查网页的HTML元素。
要执行此操作,右键单击任何图像,然后选择检查。 Chrome DevTools将在“元素”选项卡上打开。
让我们继续找到符合所示选项中名称,价格和其他信息的元素。浏览器将突出显示所选元素覆盖的区域,从而更容易识别正确的元素。

<a href="https://scrapeme.live/shop/Bulbasaur/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link">
很容易,对吧?
要获取名称元素,请悬停在名称上,直到无头浏览器突出显示为止。

<h2 class="woocommerce-loop-product__title">Bulbasaur</h2>
“ H2”元素停留在父元素内。让我们将该元素放入代码中,因此Selenium Python中的无头Chrome可以从页面中提取哪些元素。
Selenium提供了几种选择和提取所需元素的方法,例如使用元素ID,标签名称,类,CSS选择器和XPATH 。让我们使用XPath方法。
稍微调整初始代码将使刮板显示更多信息,例如URL,title和poké©mon名称。
这是我们的新代码的样子。
#...
from selenium.webdriver.common.by import By
#...
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
#...
pokemons_data = []
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
print(pokemon_name.text)

接下来,从父元素下方的“ href”属性中拉出pokâ©mon链接。此HTML标签将帮助Scraper Spot链接。

<a href="https://scrapeme.live/shop/Bulbasaur/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link">
由于我们把它解决了,让我们添加一些代码来帮助我们的刮板提取并存储名称和链接。
然后,我们可以使用Python词典来管理数据,因此不会混淆。词典将包含每个poké©Mon的数据。
#...
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link
}
pokemons_data.append(temporary_pokemons_data)
print(temporary_pokemons_data)

Superb!
现在让我们去找最后的poké©Mon Data,价格。
跳到真正的浏览器,并快速检查持有价格的元素。然后,我们可以在代码上插入一个跨度标签,以了解刮板的代码,以了解哪个元素包含价格。

#...
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
pokemon_price = parent_element.find_element(By.XPATH, ".//span")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link,
"price": pokemon_price.text
}
print(temporary_pokemons_data)
仅此而已!
唯一剩下的就是运行脚本;瞧,我们得到了所有的poké©mon数据。

如果您迷路了某个地方,这是完整的代码应该的样子。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
driver.get(url)
print("Page URL:", driver.current_url)
print("Page Title:", driver.title)
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
pokemon_price = parent_element.find_element(By.XPATH, ".//span")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link,
"price": pokemon_price.text
}
print(temporary_pokemons_data)
最好的无头浏览器是什么?
Selenium无头Python并不是唯一的无头浏览器,因为还有其他替代方案,有些只使用一种编程语言,而另一些则可以对许多语言具有约束力。
不包括硒,这是您刮擦项目的一些最好的无头浏览器。
1. Zenrows
ZenRows是一种多合一的网络刮擦工具,使用单个API调用来处理所有反机器人旁路,从旋转代理和无头浏览器到验证码。
住宅代理提供了帮助您爬网的网页并像真实用户一样浏览而不会被阻止。
Zenrows在几乎所有流行的编程语言中都可以很好地运作,您可以利用正在进行的免费试用期而无需信用卡的免费试用。
2.木偶
Puppeteer是一个node.js库,可在无头模式下使用API操作Chrome/Chromium。 Google在2017年开发了它,并继续集中势头。
它可以完全使用DevTools协议访问Chrome,在处理Chrome时使Puppeteer优于其他工具。
伪造者也比硒更容易设置和更快。缺点是它仅适用于JavaScript。因此,如果您不熟悉该语言,您会发现使用Puppeteer的具有挑战性。
3. htmlunit
此无头浏览器是用于Java程序的无关浏览器,并且可以在正确配置时模拟特定的浏览器(即Chrome,Firefox或Internet Explorer)。
JavaScript支持相当不错,并保持增强。不幸的是,您只能使用Java语言的HtmlUnit。
4. Zombie.JS
Zombie.JS是测试客户端JavaScript代码的轻量级框架,也用作Node.js库。
由于主要目的是用于测试,因此它使用测试框架完美地运行。与Puppeteer类似,您只能将Zombie.js与JavaScript一起使用。
5.剧作家
Playwright本质上是用于浏览器自动化的node.js库,但它为python,.net和java等其他语言提供了API。与Python硒相比,它相对较快。
结论
Python Headless浏览器为Web刮擦过程提供了好处。例如,它可以最大程度地减少内存足迹,完美处理JavaScript,并且可以在NO-GUI环境下运行;另外,实现仅需几行代码。
在本指南中,我们向您展示了使用Selenium Python中的无头铬从网页刮除数据的分步说明。
本指南中讨论的Python无头浏览器的一些缺点如下:
- 它无法评估图形元素;因此,您将无法在无头模式下执行需要视觉互动的任何动作。
- 很难调试。
ZenRows是一种工具,可提供各种服务来帮助您在任何情况下进行网络刮擦,包括仅使用简单的API调用使用Python无头浏览器。利用无压力和头痛的免费试验和刮擦数据。
您发现内容有帮助吗?在Twitter,LinkedIn和Facebook上分享单词并在Twitter上共享。
本文最初发表在Zenrows上:Headless Browser in Python and Selenium