SQL语句是用结构化查询语言(SQL)编写的查询,用于与数据库进行交互。它用于检索或操纵存储在数据库中的数据。 SQL语句由指定要查询的数据以及将在该数据上执行的操作的条款,表达式和谓词组成。
SQL语句:
创建数据库:
SQL中的创建数据库语句用于创建一个新的数据库。它由创建数据库关键字组成,然后是数据库的名称。可选地,可以指定字符集和整理。一旦创建数据库,就可以将表添加到其中。
查询:
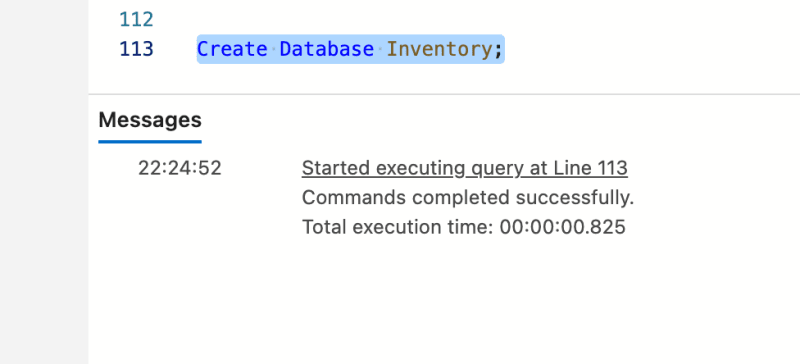
Create Database [database name];
Create Database Inventory;
Alter数据库:
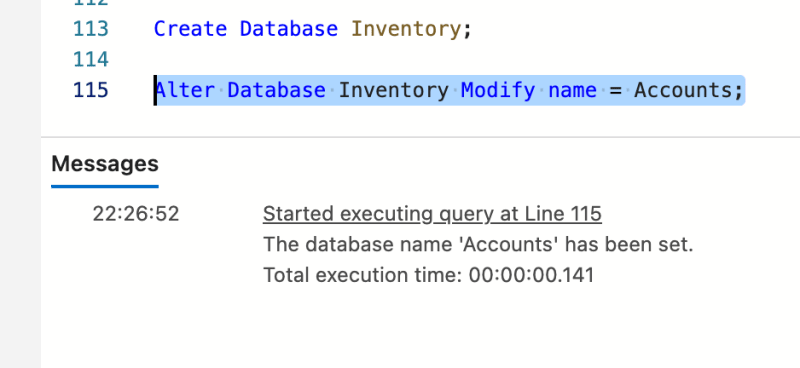
如果要更改数据库的名称,则可以运行此命令进行更改:
ALTER DATABASE [olddatabase] MODIFY NAME = [newdatabase];
Alter Database Inventory Modify name = Accounts;
记住:sql不是一种敏感语言,这意味着您可以在小写或大写中编写查询
创建表之前,请确保您正在使用要使用的同一数据库。
更改数据库:
创建表:
SQL中的创建表语句用于在数据库中创建新表。它由创建表关键字组成,然后是表的名称和列定义列表。每个列定义都由列名,其数据类型和任何其他约束组成。创建表后,可以将数据添加到它。
SQL的数据类型包含:
bool,varchar,int,float,lit
查询:
Create table [table name] (
[row name] datatype validation,
[row name] datatype validation,
);
表01
Create table vendor(
id int Primary key,
name varchar(256) not null,
email varchar(256) not null,
);
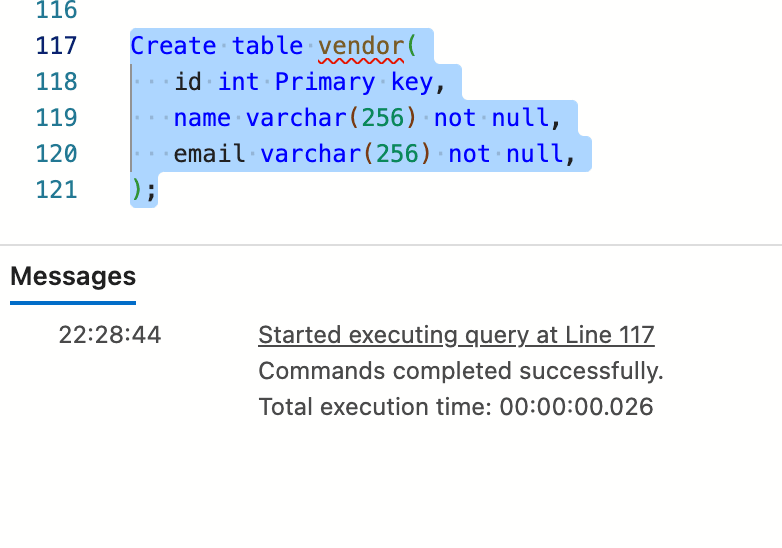
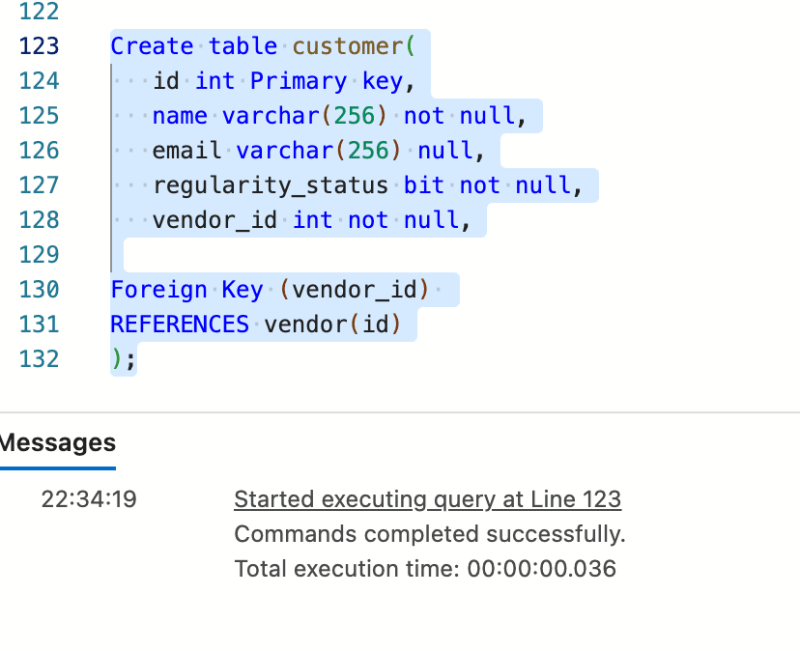
表02
Create table customer(
id int Primary key,
name varchar(256) not null,
email varchar(256) null,
regularity_status bit not null,
vendor_id int not null,
Foreign Key (vendor_id)
REFERENCES vendor(id)
);
插入语句:
SQL中的插入语句用于将新记录添加到表中。它由插入关键字组成,然后是表名称以及列名和值列表。例如,要将新行插入称为“客户”的表中,可以使用以下语句:
查询:
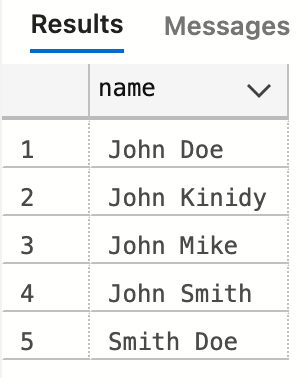
INSERT INTO customer (id, name, email, regularity_status) VALUES (1, 'John Doe', 'john@example.com', 1);
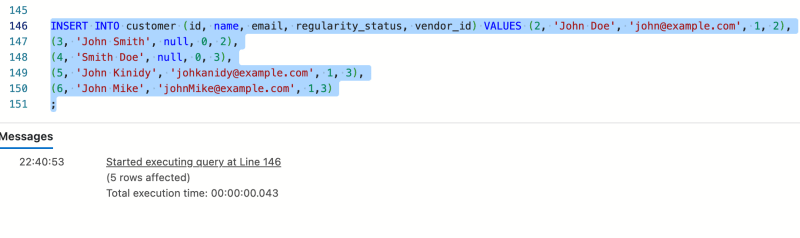
要插入多行,无需一次又一次地编写。您可以使用:
INSERT INTO customer (id, name, email, regularity_status) VALUES (2, 'John Doe', 'john@example.com', 1),
(3, 'John Smith', null, 0),
(4, 'Smith Doe', null, 0),
(5, 'John Kinidy', 'johkanidy@example.com', 1),
(6, 'John Mike', 'johnMike@example.com', 1),
;
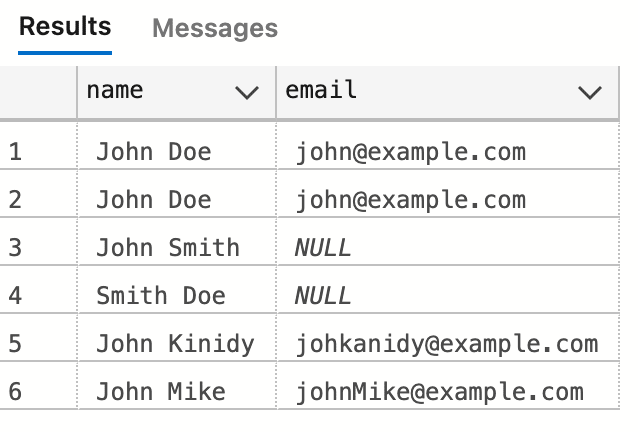
选择语句:
SQL中的选择语句用于从表中检索数据。它由选择的关键字组成,然后是列名列表和来自关键字的列表,然后是表名。例如,要从称为“客户”的表中检索所有列,可以使用以下语句:
查询:
Select [column name] from [table name];
SELECT * FROM customer;
SELECT name, email from customer;
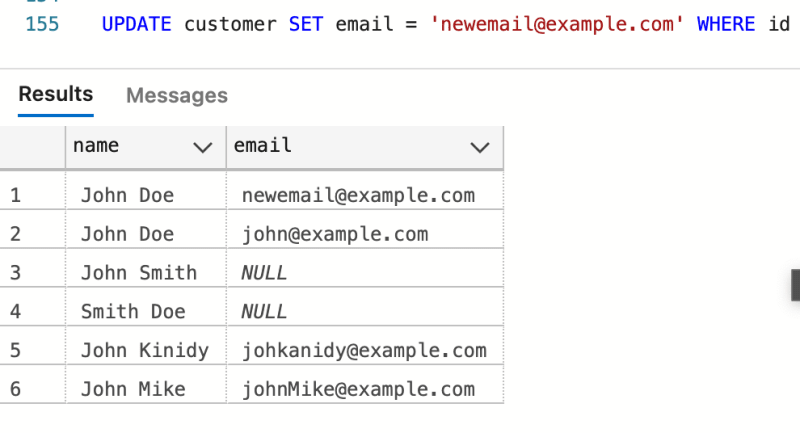
更新语句:
SQL中的更新语句用于修改表中的现有记录。它由更新关键字组成,然后是表名和列名称和值列表。例如,要使用1个ID更新客户的电子邮件地址,可以使用以下语句:
UPDATE customer SET email = 'newemail@example.com' WHERE id = 1;
删除语句:
SQL中的删除语句用于从表中删除记录。它由删除关键字组成,然后是表名,以及指定要删除的记录的子句。例如,要删除所有具有1个ID的客户,可以使用以下语句:
DELETE FROM customer WHERE id = 1;
独特的关键字:
SQL中的独特关键字用于仅返回结果集中的唯一值。它通常与Select语句结合使用,然后是结果集中应包含的列名。例如,要从称为“客户”的表中返回唯一名称,可以使用以下语句:
SELECT DISTINCT name FROM customer;
其中关键字:
SQL中的WHERE子句用于过滤结果集中的记录。它通常与Select语句结合使用,然后是必须满足的条件才能将记录包含在结果集中。例如,要仅返回具有1个ID的客户,可以使用以下语句:
SELECT * FROM customer WHERE id = 1;
和,或者,不是关键字:
and,或者不是SQL中的逻辑运算符,用于在某个子句中结合多个条件。并要求两个条件都是正确的,以便将记录包含在结果集中,或者要求其中一个条件是真实的,并且不需要条件是错误的。例如,要仅返回使用1或2的ID客户,可以使用以下语句:
SELECT * FROM customer WHERE id = 1 OR id = 2;
SELECT * FROM customer WHERE id = 1 and email = 'newemail@example.com';
空功能:
SQL中的NULL关键字用于表示缺失或未知值。它通常与Where子句结合使用,然后是运算符,例如无效或不是零。例如,要仅返回使用零电子邮件地址的客户,可以使用以下语句:
SELECT * FROM customer WHERE email IS NULL;
喜欢关键字:
SQL中的类似运算符用于将列值与模式进行比较。它通常与Where子句结合使用,然后是一个可以包括通配符的字符串图案。例如,要返回名称以“约翰”开头的客户,可以使用以下语句:
SELECT * FROM customer WHERE name LIKE 'John%';
类似的语句具有两个通配符%,_当我们想在此specific word之前检索所有字母时,我们在specific word之前使用%。可能是:
SELECT * FROM customer WHERE name LIKE '%Doe';
同样,当我们要检索一个包含oe的单词时,但是在此specific word之前只有一个字母,然后我们使用:
SELECT * FROM customer WHERE name LIKE '_oe';
顶级关键字:
SQL中的顶部关键字用于限制结果集中返回的行数。它通常与Select语句结合使用,然后是指示应返回多少行的数字。例如,要返回前10位客户,可以使用以下语句:
SELECT TOP 10 * FROM customer;
汇总函数:
count(),add(),avg()
SQL中的计数,总和和AVG函数用于对一组记录执行汇总计算。计数返回结果集中的记录数,总和添加指定列的值,并计算指定列的平均值。例如,要计算客户的平均年龄,可以使用以下语句:
SELECT AVG(age) FROM customer;
同样,要计算客户的总和,可以使用以下语句:
SELECT Sum(regularity_status) FROM customer;
要计算客户计数,可以使用以下语句:
SELECT Count(name) FROM customer;
min,最大函数:
SQL中的最小和最大函数用于查找指定列的最小值和最大值。它们通常与Select语句结合使用,然后是列的名称。例如,要找到最古老和最年轻的客户,可以使用以下陈述:
SELECT MIN(age) FROM customer;
SELECT MAX(age) FROM customer;
关键字:
SQL中的运算符之间用于过滤落在指定范围内的记录。它通常与Where子句结合使用,然后是两个指示范围开始和结束的值。例如,要仅返回18至30岁之间的客户,可以使用以下语句:
SELECT * FROM customers WHERE age BETWEEN 18 AND 30;
别名关键字:
SQL中的别名用于给列或表个临时名称。它通常与Select语句结合使用,然后是列或表格的名称以及所需的别名。例如,要给客户表“ C”,可以使用以下语句:
SELECT name as Customer_Name FROM customer;
SELECT c.name FROM customer as c;
联合,相交和除操作员以外:
联合,相交和除SQL中的运算符除外,用于结合多个选择语句的结果。 Union结合了两个选择语句的结果,Intersect仅返回两个选择语句中发现的记录,除了返回第一个选择语句中发现的记录,而不是第二个记录。例如,要结合两个选择语句的结果,可以使用以下语句:


SELECT * FROM customer UNION SELECT * FROM vendor;
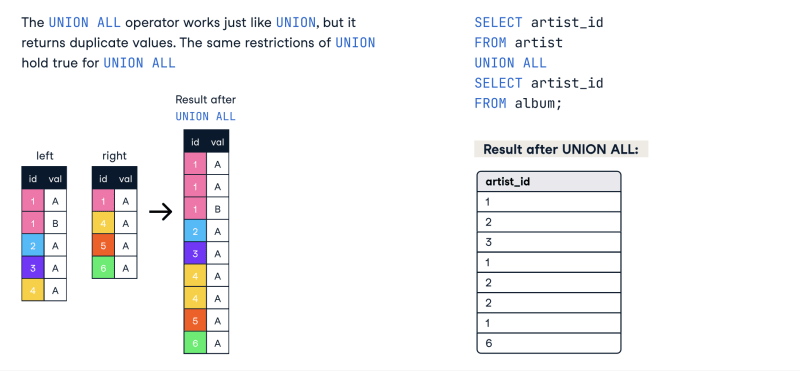
联合SQL中的所有操作员用于结合两个选择语句的结果。它与联合运营商相似,只是它不会从结果集中删除重复记录。例如,要结合两个选择语句的结果,可以使用以下语句:
SELECT * FROM customers1 UNION ALL SELECT * FROM customers2;
以上语句将结合两个选择语句的结果并返回所有记录,包括任何重复。

SELECT * FROM customer INTERSECT SELECT * FROM vendor;

SELECT * FROM customer EXCEPT SELECT * FROM vendor;
订购条款:
SQL中的子句的顺序用于对结果集中的记录进行排序。它通常与Select语句结合使用,然后是应用于排序的列的名称。例如,要按年龄对客户进行分类,可以使用以下语句:
SELECT * FROM customer ORDER BY age;
在这里,我们还可以通过添加关键字asc或desc:
来根据上升或降序排序结果
SELECT * FROM customer ORDER BY name desc;
默认情况下,按订单可以按升序订购。
在操作员中:
SQL中的运算符用于检查值列表中是否存在值。它通常与Where子句结合使用,然后是逗号分隔值的列表。例如,要检查客户的年龄是18、21还是25岁,可以使用以下语句:
SELECT * FROM customer WHERE age IN (18, 21, 25);
是操作员:
SQL中的IS运算符用于将值与另一个值或已知常数进行比较。它通常与Where子句结合使用,然后进行比较的值,并将其与其进行比较。例如,要检查客户的年龄是否等于18岁,可以使用以下语句:
SELECT * FROM customers WHERE age IS 18;
by Ly子句:
SQL中的子句组成的组用于基于指定的列或表达式将记录分组在一起。它通常与Select语句结合使用,然后是用于分组的列的名称或表达式的名称。例如,要按年龄分组客户,可以使用以下语句:
SELECT name, count(name) from customer group by name;
有子句:
SQL中的have子句被用来滤除结果集中的记录。它通常是通过子句与组结合使用的,其次是必须满足的条件才能在结果集中包含记录。例如,仅返回平均年龄大于18岁的客户组,可以使用以下语句:
SELECT name, count(name) as Similar_names from customer group by name having count(name) > 2;
案例子句:
SQL中的案例语句用于在查询中创建条件逻辑。它通常与Select语句结合使用,然后是条件和如果满足条件的情况将返回的值。例如,要根据他们的年龄为每个客户分配字母等级,可以使用以下陈述:
SELECT *,
CASE WHEN age < 18 THEN 'Teen'
WHEN age BETWEEN 18 AND 25 THEN 'Young Adulthood'
WHEN age > 25 THEN 'Adulthood'
END AS Adolescence
FROM customer;
加入:
SQL中的JOIN语句用于根据公共字段组合两个或多个表的数据。它通常由两个或多个表的名称组成,然后是一个指定联接条件的ON子句。例如,要加入客户和订单表,可以使用以下语句:
SELECT * FROM customer
JOIN orders
ON customer.vendor_id = vendor.id;
SQL连接的类型:
SQL中有几种类型的连接,每种连接都确定了连接表是如何相关的以及返回了哪些数据的方式。
¢内在加入:这种类型的联接返回仅来自匹配联接条件的两个表。
•左JOIN:这种类型的联接从左表返回所有行,并且只有符合JOIN条件的右表的行。
•右JOIN:这种类型的加入返回右表的所有行,只有符合JOIN条件的左表的行。
•完整的外部加入:这种类型的联接返回两张表的所有行,无论它们是否与联接条件匹配。
SQL中的其他类型的连接包括:
¢**交叉加入:**这种类型的联接返回两张表的所有可能的行组合,无论它们是否匹配加入条件。
•自我加入:这种类型的联接用于加入表格。它通常用于比较单个表中的值。
•自然加入:这种类型的联接加入了两个表,每个表格中具有相同名称的列。
•联合加入:这种类型的加入将两个选择语句的结果组合为一个结果集。