1. Amazon DynamoDB的核心组件
- 表:与其他数据库系统一样,DynamoDB将数据存储在表中。表是项目的集合。
- 项目:每个表包含零或更多项目。 DynamoDB中的项目类似于其他数据库系统中关系数据库,记录或元组中的行概念。在DynamoDB中,可以存储在表中的项目数量没有限制。
- 属性:每个项目都包含一个或多个属性。属性是一个基本数据元素,不需要进一步分解。 DynamoDB中的属性在许多方面与其他数据库系统中的列相似。
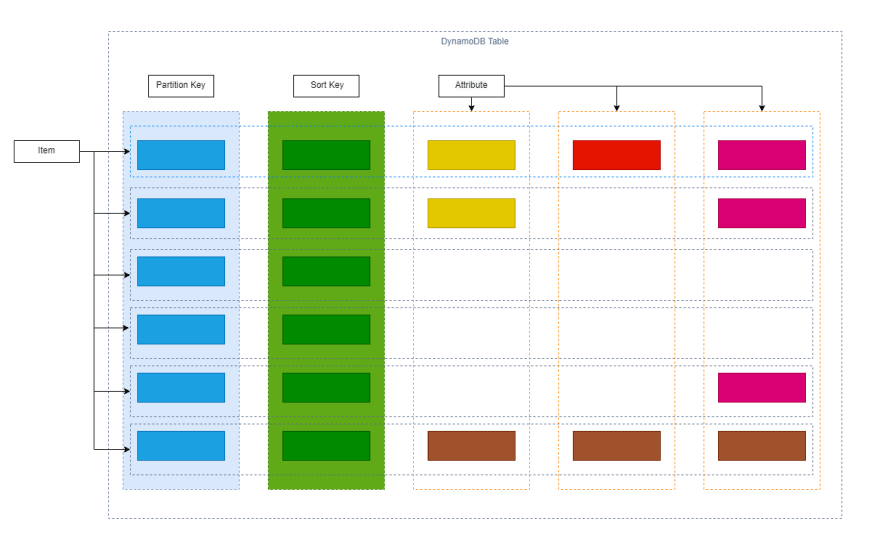
2.主键
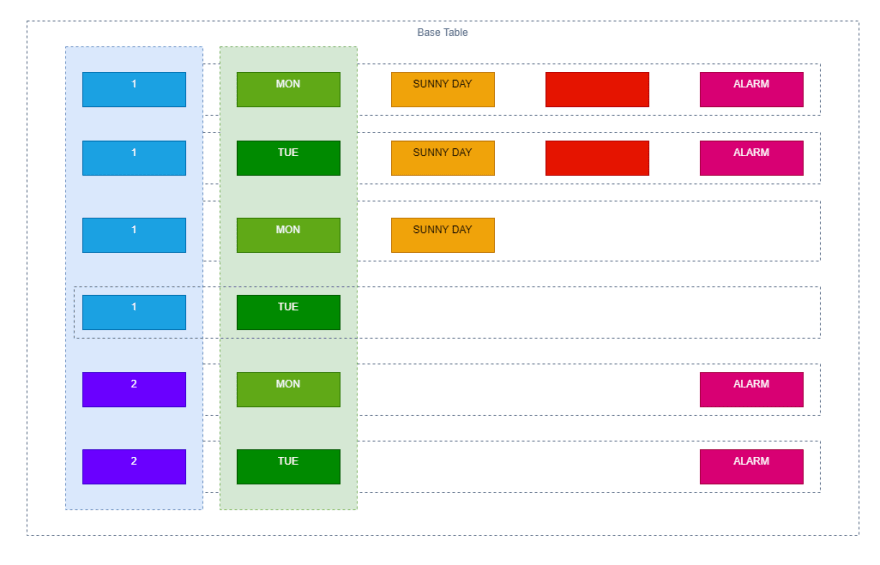
创建表格时,除表名称外,还必须指定表的主键。主键唯一地标识了表中的每个项目,以确保没有两个项目可以具有相同的密钥。 DynamoDB支持两种不同类型的主要密钥:分区键和复合主键。
。分区密钥是一个简单的主键,由称为分区键的属性组成。 DynamoDB使用分区密钥的值作为内部哈希的输入,哈希的输出定义了将存储项目的分区(DynamoDB内部的物理内存)。在只有分区键的表中,没有两个项目可以具有相同的分区键值。
另一方面,复合主键由分区键和一个键组成。 DynamoDB使用分区键值作为内部哈希的输入,哈希的输出定义了将存储该项目的分区(dynamodb中的物理内存)。所有具有相同分区键值的项目都以排序键值分类顺序存储在一起。在带有分区键和排序密钥的表中,多个项目可以具有相同的分区键值,但是这些项目必须具有不同的排序键值。复合主键在查询数据时为您提供了更大的灵活性。
3.次要索引
您可以在表上创建一个或多个次要索引。
辅助索引允许在表中查询数据,其中包含来自原始分区键和表格的不同键。使用DynamoDB,数据查询操作比扫描更快,更具成本效益。
这是一个示例DynamoDB表:
如果我们执行数据查询操作,我们可以通过分区密钥的值并分类密钥找到数据。
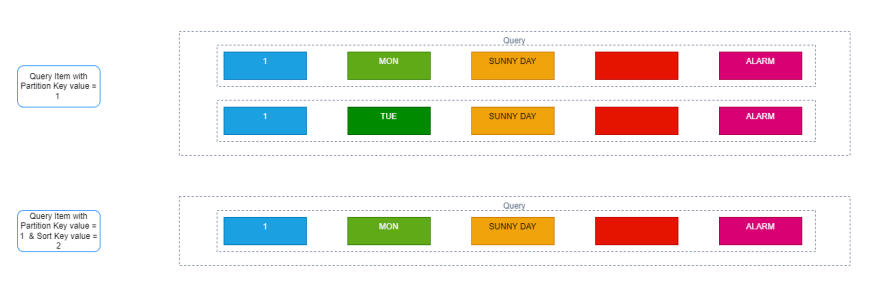
如果我们执行数据扫描操作,我们将扫描整个表,然后通过任何属性过滤。 (实施过滤器时,我们仍然必须花费扫描整个表的成本。)

dynamoDB不会迫使您使用索引,但是在数据查询方面,它们确实使您的应用程序更具灵活性。在表格上创建辅助索引后,您可以以与从表中读取数据相同的方式从索引中读取数据。
DynamoDB支持两种类型的索引:
全局次要索引,它们具有与表上的索引不同的分区键和排序键。
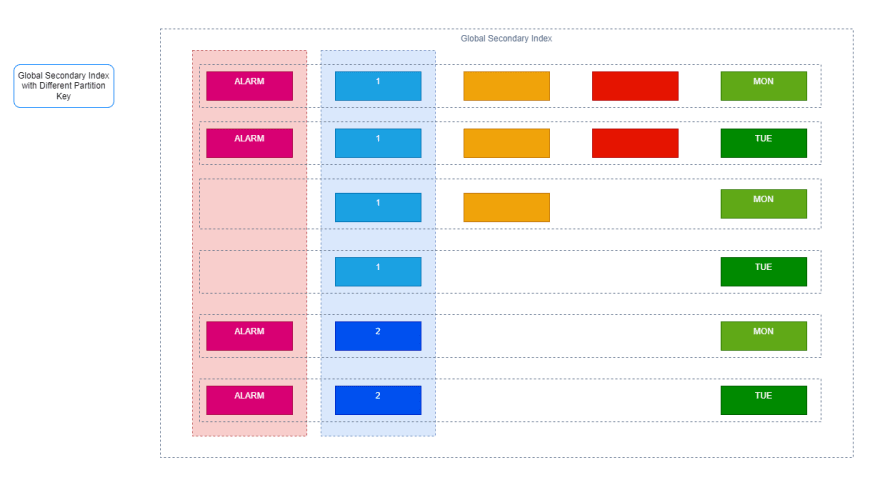
本地次要索引,它们具有与表相同的分区键,但具有不同的排序键。
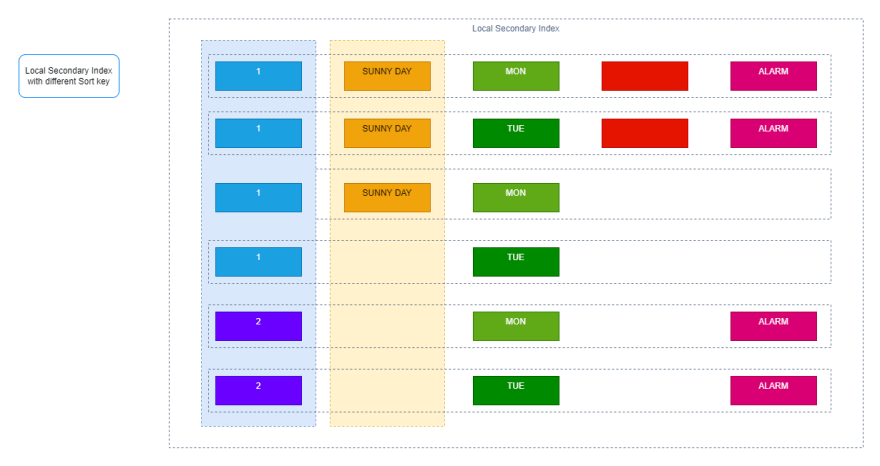
dynamoDB中的每个表最多有20个全局辅助索引(默认限制)和5个本地辅助索引。
4.命名规则和数据类型
DynamoDB中的表,属性和其他对象必须具有名称。以下是DynamoDB的命名规则:
所有名称都必须用UTF-8编码,并对案例敏感。
表名称和索引名称必须在3至255个字符之间,并且只能包含以下字符:
- a至z
- a至z
- 0至9
- _(下划线)
- (连字符)
- 。 (点)
属性名称必须至少一个字符,但不超过64 kb。
以下是例外。这些属性名称不能超过255个字符:
- 辅助索引分区的关键名称。
- 辅助索引排序关键名称。
- 任何用户指定的预期属性的名称(仅适用于本地辅助indexes)。
dynamoDB支持表中属性的许多不同数据类型,可以分类如下:
- 标量类型:标量类型只能表示一个值。标量类型是数字,字符串,二进制,布尔值和null。
- 文档类型:文档类型可以代表具有嵌套属性的复杂结构,例如JSON文档。文档类型是列表和映射。
- 设置类型:设置类型可以代表许多标量值。设置类型是字符串集,数字集和二进制集。
5.阅读一致性
最终始终读取
- 当您从DynamoDB表中读取数据时,响应可能无法反映最近完成的写操作的结果。
- 响应可能包括一些过时的数据。
- 如果您在短时间后重复阅读请求,则响应将返回最新数据。
强烈一致的读数
当您请求强烈一致的读取时, dynamodb 将返回最新数据的响应,反映了所有成功的书面文字的更新。但是,这种一致性带有一些缺点:
- 如果存在网络问题或中断,则可能无法使用 。在这种情况下, dynamodb 可能会返回服务器错误(http 500)。
- 强烈一致的读取可能比最终保持一致读。 。
- 全球次要索引不支持强烈一致的读取。
- 强烈一致的读取使用双吞吐量能力最终一致读。 。
6.读/写能力模式
按需模式
- Amazon DynamoDB按需是一种灵活的付款选项,能够在没有容量计划的情况下每秒提供数千个请求。 dynamodb 按需提供付费按需读取请求,因此您只为使用的费用付费。
- 当您选择按需模式时, dynamodb 会立即响应您的工作负载,因为它们增加或减小到先前达到的流量水平。如果工作负载的吞吐量达到新的峰值,DynamoDB会迅速适应以适应工作负载。使用按需模式的表提供了与DynamoDB已经提供的相同的单数毫秒延迟,服务水平协议(SLA)承诺以及安全性。您可以选择新表和现有表的需求,并且可以继续使用现有的 dynamodb API,而无需更改代码。
- 按需模式是一个不错的选择,如果以下任何一个是正确的:
- 您创建一个带有未知工作量的新板。
- 您的应用程序流量不可预测。
- 您只是喜欢为使用的费用付出的便利性。
准备模式
- 如果您选择了已提供的模式,则指定读取的数量和每秒所需的读取数量。您可以使用自动缩放来自动调整表的供应能力,以应对流量的变化。这可以帮助您管理DynamoDB使用量以保持或低于指定的请求率以预测性能。
- 如果以下任何一个是正确的,则提供的模式是一个不错的选择:
- 您有可预测的应用程序流量。
- 您运行具有一致或增量流量的应用程序。
- 您可以预测控制成本的能力要求。