在这个故事中,我将告诉您我们如何开发一种结构化方法来解决复杂的技术问题并成功提高了我们的应用程序的性能高达30次。
我们开始开发具有收集技术要求的新企业应用程序。最初,我们发现我们的应用程序应包括这些主要功能:
- 包含图表的报告
- 一个简单的任务跟踪系统
- 所有公司员工的清单
所有这些数据也应供离线使用。听起来不是那么难,对吗?我们这么认为。我们在JSON上找到了最初的技术堆栈基础,以进行客户服务器的交互,并在移动设备上脱机数据存储。在iOS上,我们使用了Coredata包装器MagicalRecord,几年前非常受欢迎。今天,这肯定是一个错误的选择,因为它用Objective-C编写,并且在过去三年中没有任何更新。但是,在2014年,它是免费的,开源的,并且在Github上有10k+的星星,但主要原因是缺乏任何选择。在Android上,我们由于相同的原因决定使用ormlite。
在开发过程的早期阶段,一切都很好。我们在开发服务器上有一些演示报告和数十名员工。但是,将产品出售给第一个客户后,我们立即遇到了严重的性能问题。我们来自后端团队的同事将客户的生产数据库的一部分导入了我们的测试环境。我们发现我们的应用程序还没有准备好使用200k员工的列表来运营。下载完整列表需要5到10分钟,滚动性能很差,搜索根本没有工作。那不是我们的最终用户所期望的。另一个问题是报告。其中一些包含数百万积分的图表,因此我们遇到了同样的问题:下载缓慢且性能差。
我们试图制作一些hotfix,向客户服务器请求引入分页,并将批量写入写入本地数据库,但我们无法提高性能足够高。对我们来说幸运的是,我们的销售部门与客户签署了6个月的长期合同,第一部分是更新一些内部系统,因此我们有一个或两个月的时间来解决我们的问题。我们了解到,我们需要对发生错误的事情进行全面研究,而不是编写混乱的错误修复。在下面,我将在详细信息上告诉您我们的方法。
这个调查
我们从优化员工列表绩效开始。经过几乎没有尝试进行快速错误修复的尝试失败后,我们决定将下载员工列表的过程分开,并将其显示为较小的步骤,并测量每个步骤的持续时间以找出需要修复的内容。
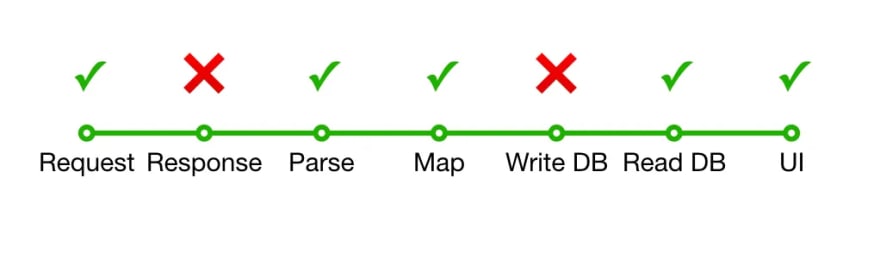
最后,我们发现等待服务器响应(30s)并写入本地数据库(5â10m)是整个过程中最长的两个部分,而其他部分仅花了几百毫秒,因此没有,因此没有t需要我们的注意。
服务器响应
在进行任何优化之前,我们有一个请求下载员工的完整列表。故意选择此方法是因为此列表的任何一部分都不具有最终用户的任何值。没有人愿意看到以字母A开头的姓氏的员工,我们的用户需要一个完整的列表来访问所有联系人并执行离线搜索。
我们还具有通过服务器之间用户设备之间同步的最喜欢的联系人功能。首先,我们将喜爱的数据移动到本地数据库中的分离请求和分开表。这并不能使我们的性能提高,但让我们在服务器端启用完整员工列表的内存存储。
响应时间优化的最终也是最重要的部分是引入三角洲 - 更新。如上所述,我们在服务器端存储了一个内存中的员工列表。它将响应时间从〜30秒减少到仅1秒钟,由于网络延迟,我们无法再减少它。在与后端和销售团队讨论解决方案之后,我们还发现,通常每天只能更新员工列表,因此无需更频繁的更新。因此,为了减少服务器端上的负载并加快数据库在移动客户端上的编写,我们引入了Delta-updates。在第一个安装我们的应用程序下载完整列表之后,第二天,它要求服务器提供一个小的delta-update,以提供最新数据应用程序的版本(时间戳)。

本地数据库优化
delta-ups急剧减少了员工列表更新时间。但是,我们仍然有两个问题:
- 由于sqlite写作速度,初始负载太慢
- 施加几个三角洲(例如,在不活动2周之后)也花了很多时间,因为完全相同的原因
批处理写作并没有提高性能,我们决定尝试不同的方法。我们有一个假设,即Sqlite或MagicalRecord在我们的情况下都是瓶颈。因此,我们提出了2种可能的解决方案:
- 切换ORM
- 用其他db 切换sqlite
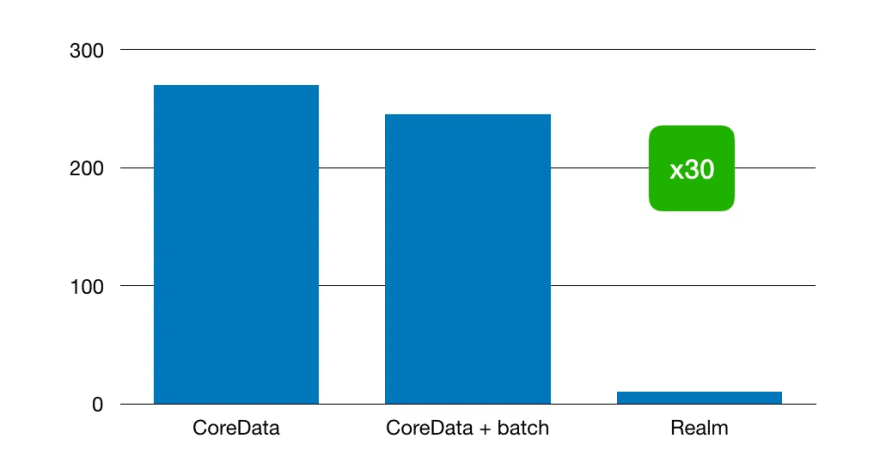
我们没有找到对MagicalRecord的任何替代品,因此决定使用Coredata。作为SQLITE替换,我们使用了领域。 然后,我们开发了一项合成测试来测量200K实体的写作性能。结果几乎相同。这就是为什么我们还决定将MagicalRecord包括在我们的测试中。我们惊讶地发现,所有3个测试都在几乎相同的时间内进行。在这里,我们终于找到了我们的问题:建立实体之间的关系。在合成测试中,我们将书面写入单个表,而在生产应用程序中,我们有2个与关系的表。请参阅下图:

每个员工都有大约3个联系人:电子邮件,手机和工作电话。因此,我们需要将200k员工写入一个表格,与另一个桌子联系60万个联系人,并在这两个表之间创建600k关系。
我们更新了合成测试,发现 coredata(或sqlite本身)正在与关系非常慢一起工作。我们能够实现从Coredata转换为领域的30倍性能提高。这样做的主要原因是领域的无sql性质。您可以找到更多的技术细节和解释here。请参阅下图:
搜索性能
因此,我们能够实现出色的下载绩效,将初始加载时间从几分钟减少到仅15秒。滚动现在也很光滑。但是,我们仍然对搜索性能不满意。在某些情况下,揭示所有搜索结果花费了几分钟。在下面,我要向您解释为什么它如此复杂。
这是两个不同表中所有搜索字段的列表:
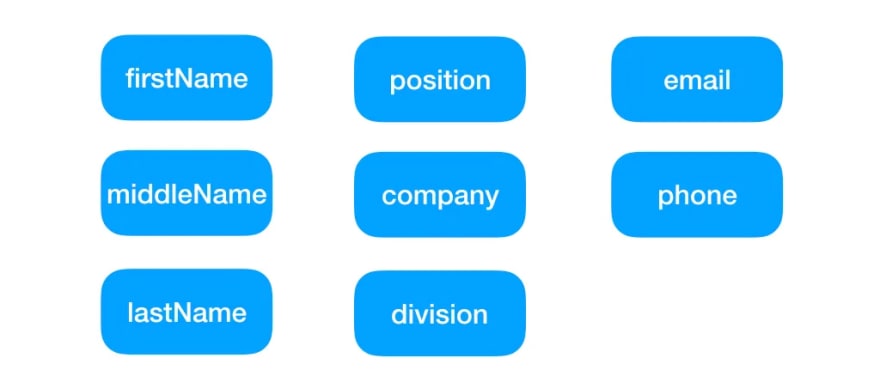
需要在名字,中间名,姓氏,位置,公司,部门,电子邮件和电话的任何组合上开发全文搜索。请记住,我们的数据库中有20万名员工和近60万个联系人(电子邮件和电话)。我们必须为每个用户的输入运行8个搜索查询。它花了太多时间来处理数据库的最终响应。另一个并发症是西里尔人字符的广泛使用。所有名称,职位,公司和部门都是仅西里尔的。虽然电子邮件是拉丁字符和数字的混合,而手机仅是数字的。我会跳过电话扩展的更深层细节。
首先,我们决定将最小搜索查询限制为3个符号。然后,我们对这些符号进行了一些基本分析。如果有拉丁字符,那绝对是一个电子邮件地址。因此,我们只能运行1个查询,而不是运行一个查询。我们在电话号码上也是如此。但是,有些电子邮件包含数字,这就是为什么我们通过电子邮件和电话进行2个查询。通过此优化,我们将搜索查询的数量剪切了两次。
我们仍然需要提高名称,位置,部门和公司标题搜索绩效。在对不同网站上最新出版物的另一项研究之后,我们发现我们的主要问题是病例不敏感的搜索。由于检查了像a, à, á, â, ä, ã, æ, å, ā这样的类似字符,因此对仅拉丁字符的工作非常快,而其他所有其他角色的工作速度为8次。有9个不同的字母!对于许多其他人来说也是如此。因此,我们必须关闭案例不敏感的搜索并在表中创建小写字段。根据特定词,这给了我们8至12倍的性能。
我们还使用我们对俄罗斯写作细节的知识删除了一些名字,中间和姓氏搜索组合。用户通常使用1个组合中的1个:
- 第一个
- 最后
- 第一个最后
- 最后一个第一个
- 第一个中间
- 第一个中间
- 最后一个第一个中间
俄罗斯没有人会寻找Middle First或Middle Last组合。这些知识让我们删除,例如,通过中间名字段搜索单个单词输入。通过此最终更新,我们又增加了1.5倍的性能。
我们创建了一个合成测试来测量搜索性能。它包含〜100个不同的搜索查询,主要集中在姓名和位置搜索上,就像现实生活中一样。这是我们的结果:
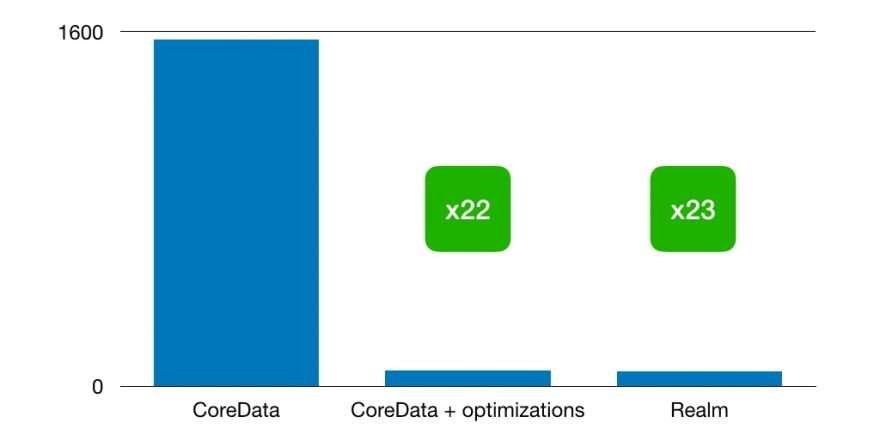
应用了所有新的搜索优化算法后,我们提高了搜索性能 23次!
报告解决方法
在员工取得成功列表绩效改进之后,我们开始完全过渡到领域。最终,我们发现一些报告仍然非常缓慢。我们实现了与服务器端相同的存储模型:将每个报告存储在4-5个不同的表中。我们有5种不同的报告类型,每个报告类型都有不同的数据结构。例如,其中一份报告由章节组成,章节包含图表,包含序列的图表,而系列包含点。我们创建了5个表来存储所有这些数据。一些图表包含数百万点,这确实是大量数据。
进行了时间测量研究后,我们发现在这种情况下,我们的瓶颈再次是数据库。但是,我们已经切换到领域,这给了我们一些性能的提高,实际上,我们没有其他数据库可以切换。我们发现的最简单的解决方案是将映射的数据直接发送到UI并在后台线程中写入DB以备将来使用。它应该很快起作用,但会产生建筑地狱。考虑一下,您需要每次尝试从数据库中获取数据时,都需要将DB的托管对象映射到某些普通对象。由于托管对象的行为,创建某些协议(接口)的选择不是很大的选择:它可以在每时每刻都会更改甚至删除,我们需要观察到这一点。但是,普通物体总是保持不变。
最后,我们发现,如果我们可以在UI中使用普通对象,则根本不需要托管对象。 我们可以将原始JSON数据直接存储在数据库中并按需映射。我们仍然在报告表上有一些字段,例如标题,更新日期,作者等t包含与数据库其他部分的任何关系,这就是为什么可以将其存储为RAW JSON。这项调整使我们最多增加了300次(是,三百倍)的性能和惊人的用户体验。
得到教训
我们花了将近3周的时间试图优化Coredata查询,但我们未能通过。但是,我们能够停止这些尝试并找到了更好的解决方案。切换数据库是非常困难的过程。完成这项任务大约需要2个月,我仍然不确定是否可以更快地完成此任务。在我们的iOS应用程序中,我们使用了Viper体系结构并实现了面向服务的方法,但是由于Coredata的性质(我们广泛使用NSFetchedResultsController来提高性能),我们仍然在交互式中拥有服务的一部分(数据库)层。但是,就Viper而言,Interactor不应该对我们使用的特定数据库适配器有所了解,这要求我们删除NSFetchedResultsController使用情况。由于性能,我们负担不起。是的,这是一个周期参考:)因此,我们决定将服务层的一部分留在交互者中,用领域的通知机制代替NSFetchedResultsController。这是最困难的部分,我们根本没有更改数据库实体,只是用RealMobject替换了NSManageBject的继承。
我的iOS和Android团队都非常喜欢与领域合作。它可以快速工作,易于学习且易于使用。它需要的代码要少得多,尤其是与旧的Ormlite甚至新房间相比的Android。
我们学到了什么:
- 在进行任何优化之前,请确保您知道需要改进特定位置
- 如果您不确定该怎么做
- 进行实验并尝试新技术
- 始终为您的特定任务寻找合适的解决方案
也许领域不适合您的特定任务,因为它对我们有效,但是在做出选择之前,请尝试对您的任务进行一些绩效测试。切换本地数据库的成本总是比运行一些测试的成本大。
底线
领域通常会更快,由于其无sql性质而比柯达塔更快。主要优势是对表之间的关系非常快速地管理。此外,与iOS和Android平台上的现有SQL ORMS进行比较要容易得多。但是,您可能会在更深层次的地区遇到一些错误和缺乏文档。就我个人而言,我会在下一个应用程序上选择领域。