,由于机器学习(ML)模型,我们看到了连续的困难问题。例如,Natural Language AI和Vision AI从文本和图像中提取洞察力,具有类似于人类的结果。他们解决了我们交流方式中心的问题:
- 自然语言处理(NLP)
- 光学特征识别(OCR)
- 手写识别(HWR)
下一步是什么?好吧,它已经与Document AI一起在这里,并且不断增长:
- 文档理解(DU)
文档AI建立在这些基础上,使您以多种形式从文档中提取信息:
- 文字
- 结构
- 语义实体
- 归一化值
- 丰富
- 定性信号
在本文中,您将看到以下内容:
- 文档AI 的概述
- 实践和视觉示例
- 文档处理演示(包括源代码)
处理文件
处理器类型
您可以想象到的文档类型很多,为了满足所有需求,文档处理器是文档AI的核心。它们可以是以下类型:
- 一般处理器处理常见任务,例如检测文档表或解析表格。
- 专业处理器分析特定文件,例如发票,收据,薪水单,银行对帐单,身份文件,官方表格等。
- 自定义处理器满足其他特定需求,让您根据自己的文档自动培训私人ML模型,并执行自定义文档分类或自定义实体检测等任务。
处理器位置
创建处理器时,您指定其位置。这有助于控制文档将在哪里处理。这是当前的多区域:
| 位置 | api location
|
API端点 |
|---|---|---|
| 欧盟 | eu |
eu-documentai.googleapis.com |
| 美国 | us |
us-documentai.googleapis.com |
此外,单区域位置可用一些处理器;这使您可以解决本地法规要求。如果您定期进行实时或大量文档处理文档,则这也可以帮助获得较低的潜伏期的响应。例如,以下是“文档OCR”通用处理器的当前位置:
OCR_PROCESSOR位置 |
api location
|
|---|---|
| 美国 | us |
| 欧盟 | eu |
| 印度(孟买) | asia-south1 |
| 新加坡(荣朗西) | asia-southeast1 |
| 澳大利亚(悉尼) | australia-southeast1 |
| 英格兰(伦敦) | europe-west2 |
| 德国(法兰克福) | europe-west3 |
| qu©bec(蒙特特©al) | northamerica-northeast1 |
注意:API端点是根据公约{location}-documentai.googleapis.com命名的。
有关更多信息,请查看Regional and multi-regional support。
处理器版本
处理器可以随着时间的流逝而发展,以提供更精确的结果,新功能或修复程序。例如,以下是“费用解析器”专用处理器的当前版本:
name |
display_name |
create_time |
|---|---|---|
| 预审计的Expense-V1.1-2021-04-09 | 稳定 | 2021-04-09 |
| 预读取 - Expense-V1.2-2022-02-18 | 稳定 | 2022-02-18 |
| 预读取 - Expense-V1.3-2022-07-15 | 稳定 | 2022-07-15 |
| 预审计的Expense-V1.4-2022-11-18 | 释放候选人 | 2022-11-18 |
您通常可以执行以下操作:
- 在生产中使用
Stable版本1.3。 - 使用
Release Candidate版本1.4从新功能中受益或测试未来版本。
要保持更新,请关注Release notes。
接口
文档AI可以通过通常的接口向开发人员和从业者使用:
- REST API(基于通用JSON的界面)
- RPC API(低延迟GRPC接口,所有Google服务使用)
- Client Libraries(GRPC包装器,以您首选的编程语言开发)
- Cloud Console(Web Admin用户界面)
要求
有两种方法可以处理文档:
- 同步与在线请求一起分析单个文档并直接使用结果
- 异步带有批处理请求,以在多个或更大的文档上启动批处理处理操作
| 接口 | 同步方法 | 异步方法 |
|---|---|---|
| 休息 | process |
batchProcess |
| RPC | ProcessDocument |
BatchProcessDocuments |
| 客户库:Python | process_document |
batch_process_documents |
| 客户库库:node.js | processDocument |
batchProcessDocuments |
| 客户库库:Java,â级 |
从像素中提取信息
让我们从使用“文档OCR”一般处理器分析此简单的屏幕截图开始,然后检查像素如何成为结构化数据。
输入图像

文档AI响应
- 响应包含一个
Document实例。 - 在自然阅读顺序中检测到的输入的整个文本在
Document.text下序列化。 - 结构化数据以每个页面为基础返回(此处的一页)。
- “文档OCR”处理器返回所有处理器共有的结构骨架。
{ // document
"mime_type": "image/png",
"text": "Willkommen!\nBienvenue !\nWelcome!\nQuestion: What is the answer to the ultimate question of life?\nAnswer: 42\n",
"pages": [
{
"page_number": 1,
"dimension": {/*…*/},
"layout": {/*…*/},
"detected_languages": [/*…*/],
"blocks": [/*…*/],
"paragraphs": [/*…*/],
"lines": [/*…*/],
"tokens": [/*…*/],
"image": {/*…*/}
}
]
}
本文中的示例显示了使用GRPC和Python(例如Python)使用的惯例,显示了Snake-Case字段名称(例如mime_type)。对于骆驼案环境(例如REST/JSON),两个惯例之间有一个直接的映射:
-
mime_type-mimeType -
page_numberpageNumber
文本级别
对于每个页面,返回了四个级别的文本检测:
blocksparagraphslinestokens
在这些列表中,每个项目都公开了一个layout,包括该项目的位置相对于bounding_poly.normalized_vertices中的页面。
这使我们可以突出显示检测到的令牌:

这是最后一个令牌:
{ // document.pages[0].tokens[21]
"layout": {
"text_anchor": {
// "42\n" ← document.text[104:107]
"text_segments": [{ "start_index": "104", "end_index": "107" }]
},
"confidence": 0.99, // Confident at 99% that the answer is "42" ;)
"bounding_poly": {
// The 4 bounding box vertices, relative to the page
// Page (top, left)..(bottom, right): (0.0, 0.0)..(1.0, 1.0)
"normalized_vertices": [ { "x": 0.4028, "y": 0.5352 },
{ "x": 0.4327, "y": 0.5352 },
{ "x": 0.4327, "y": 0.6056 },
{ "x": 0.4028, "y": 0.6056 } ]
} //,…
} //,…
}
注意:为了可读性,将浮子值截断了。
语言支持
文档通常使用一种单语言编写,但有时使用多种语言。您可以在不同的文本级别检索检测到的语言。
在我们的上一个示例中,检测到两个块(pages[0].blocks[])。让我们强调它们:

左侧块是德语,法语和英语的混合,而右块仅是英语。这是在页面级别报告三种语言的方式:
{ // document.pages[0]
"detected_languages": [
{ "language_code": "en", "confidence": 0.77 },
{ "language_code": "de", "confidence": 0.12 },
{ "language_code": "fr", "confidence": 0.11 }
]
}
注意:在此级别上,语言置信率大致对应于每种语言中检测到的文本的比例。
现在,让我们突出显示五个检测线(pages[0].lines[]):

也在行级别报告了每种语言:
{ // document.pages[0]
"lines": [
// "Willkommen!"
{ "detected_languages": [{ "language_code": "de", "confidence": 1.0 }] },
// "Bienvenue !"
{ "detected_languages": [{ "language_code": "fr", "confidence": 1.0 }] },
// "Welcome!"
{ "detected_languages": [{ "language_code": "en", "confidence": 1.0 }] },
// "Question: What is the answer to the ultimate question of life?"
{ "detected_languages": [{ "language_code": "en", "confidence": 1.0 }] },
// "Answer: 42"
{ "detected_languages": [{ "language_code": "en", "confidence": 1.0 }] }
]
}
如果需要,您也可以在令牌级别获得语言信息。 “问题”在法语和英语中是相同的单词,在这种情况下,可以充分返回为英语令牌:
{ // document.pages[0].tokens[6]
"layout": {
"text_anchor": {
// "Question" ← document.text[33:41]
"text_segments": [{ "start_index": "33", "end_index": "41" }]
},
"confidence": 0.99
},
// In this context, the token "Question" is English, not French
"detected_languages": [{ "language_code": "en" }]
}
在屏幕截图中,您是否注意到左侧块中特殊的东西?

好吧,标点符号规则在语言之间可能有所不同。法语使用印刷空间来用于双标点标记(“双”为“两部分”,例如在"!","?","«","«"等)。标点符号是可以“翻译中迷失”的语言的重要组成部分。在这里,该空间保存在"Bienvenue !"的转录中。不错的触摸文档AI或我应该说,触摸©!
{ // document.pages[0].lines[1]
"layout": {
"text_anchor": {
"text_segments": [
// "Bienvenue !\n" ← document.text[12:24]
// The French typographical space before "!" is preserved \o/
{ "start_index": "12", "end_index": "24" }
]
},
"confidence": 0.99
}
}
有关更多信息,请参见Language support。
手写检测
现在一个更困难的问题''让我们检查一下手写的处理方式。
此示例是印刷和手写文本的混合,我在其中写了一个问题和答案。这是检测到的令牌:

我很惊讶地看到自己的笔迹转录:
{ // document
"text": "Willkommen!\nBienvenue !\nWelcome!\nQuestion: What is the answer to the ultimate question of life?\nAnswer:\n42\n"
}
我要求家人(曾经写法语)做同样的事情。每个唯一的手写样本也可以正确检测到:

te抄录:
{ // document
"text": [
"Willkommen!\nBienvenue !\nWelcome!\n",
"Willkommen!\nBienvenue !\nWelcome!\n",
"Willkommen!\nBienvenue !\nWelcome!\n",
"Willkommen!\nBienvenue !\nWelcome!\n",
"Question: What is the answer to the ultimate question of life?\nAnswer: 42\n",
"Question: What is the answer to the ultimate question of life?\nAnswer: 42\n",
"Question: What is the answer to the ultimate question of life?\nAnswer: 42\n",
"Question: What is the answer to the ultimate question of life?\nAnswer: 42\n"
]
}
这看起来很神奇,但这是ML模型的目标之一:返回结果尽可能接近人类的反应。
置信度得分
我们犯了错误,ML模型也可以。为了更好地欣赏您获得的结构化数据,结果包括置信度分数:
- 置信度得分不代表准确性。
- 他们表示模型对提取的结果有多信心。
- 他们让您和您的用户思考模型的提取。
让我们在上一个示例之上覆盖置信度得分:

将其分组为桶后,置信度得分通常很高,有几个离群值:

这里的最低置信度得分是57%。它对应于一个简短的手写单词(象征)(较少的信心上下文),而且确实不是特别清晰:
{ // document.pages[0].tokens[71].layout
"text_anchor": {
// "42\n" ← document.text[351:354]
"text_segments": [ { "start_index": "351", "end_index": "354" } ]
},
// 57% ← Confidence that this token is "42"
"confidence": 0.57
}
要获得最佳结果,请记住这些一般的经验法则:
- ML结果是最好的猜测,这可能是正确或不正确的。
- 置信分数较低的结果更有可能是错误的猜测。
- 如果我们不能顺利阅读文档的一部分,或者需要三思而后行,那么对于ML模型来说可能也很难。
尽管所有文本都在提出的示例中正确转录,但根据输入文档并非总是如此。构建更安全的解决方案 - 特别是在关键业务应用程序中 - 您可以考虑以下内容:
- 请与您的用户清楚,结果是自动生成的。
- 传达解决方案的范围和局限性。
- 通过可解释的信息或可过滤结果改善用户体验。
- 设计您的过程以触发人类干预以较低的置信度得分。
- 监视您的解决方案以检测随着时间的变化(稳定指标的漂移,用户满意度下降等)。 。
要了解有关AI原则和最佳实践的更多信息,请查看Responsible AI practices。
旋转,偏斜,失真
您错误地扫描了几次文档?好吧,这不再是一个问题。文本检测对旋转,偏斜和其他扭曲非常健壮。
在此示例中,网络摄像头输入不仅颠倒,而且偏斜,模糊,并且具有异常方向的文本:

在进行进一步分析之前,请记录AI在页面级别考虑最佳阅读方向,并在需要时(Deskews)(如果需要)。这为您提供了可以以更自然的方式使用和可视化的结果。一旦通过文档AI处理,前面的示例就会易于阅读,而无需扭曲脖子:

在结果中,默认情况下每个页面都有一个image字段。这表示文档AI使用以提取信息的图像。所有页面结果和坐标都是相对于此图像的。当一个页面被分解后,存在一个transforms元素,并包含应用于图像的转换矩阵列表:
{ // document.page[0]
// The image for the page. All coordinates are relative to this image.
"image": { "content": "…", "mime_type": "image/png", "width": 1150 /*…*/ },
// 1 transformation matrix was applied to deskew the page
"transforms": [ { "rows": 2, "cols": 3 /*…*/ } ]
}
注意:
- 页面图像可以是不同的格式。例如,如果您的输入是JPEG映像,则响应将包括相同的JPEG或DESKEWED PNG(如前示例中)。
- Deskewed图像具有较大的尺寸(Deskwing添加了空白的外部区域)。
- 如果您在解决方案中不需要视觉结果,则可以在请求中指定一个
field_mask,以接收较轻的响应,只有您的感兴趣领域。
方向
文档并不总是以单个方向的所有文本,在这种情况下,单独使用的文本是不够的。在此示例中,该句子以四个不同的方向分解。每个部分都以其自然取向得到正确认可和处理:

在layout字段中报告了方向:
[ // document.pages[0].blocks
{ "layout": { "orientation": "PAGE_RIGHT" } }, // → 90° clockwise
{ "layout": { "orientation": "PAGE_UP" } }, // ↑ Natural orientation
{ "layout": { "orientation": "PAGE_LEFT" } }, // ← 90° counterclockwise
{ "layout": { "orientation": "PAGE_DOWN" } } // ↓ 180° from upright
]
注意:在每个OCR级别返回方向(blocks,paragraphs,lines和tokens)。
噪音
当文档来自我们的模拟世界时,您可以期待 - 意外。由于ML模型是从现实世界样品中训练的,其中包含现实生活噪声 - 一个非常有趣的结果是,文档AI对噪声也非常强大。
在用皱巴巴的纸张的示例中,文本开始很难读取,但仍被OCR模型正确转录:

文档也可能是肮脏的或弄脏的。使用相同的样本,这在添加一些噪声层后一直在工作:

在这两种情况下,正确检测到完全相同的文本:
{ // document
"text": "Coffee\nCoffee is a brewed beverage made from particular beans. Arthur Dent made himself some coffee on the\nThursday of Earth's destruction; this behaviour was most unusual, as he usually drank tea.\n"
}
您已经看到了大多数核心功能。它们得到了“文档OCR”一般处理器以及其他处理器的支持,这些处理器利用这些功能专注于更具体的文档类型并提供其他信息。让我们检查下一级处理器:“形式解析器”处理器。
表单字段
“形式解析器”处理器使您可以检测表单字段。表单字段是字段名称和字段值的组合,也称为键值对。
在此示例中,如前所述检测到打印和手写文本:

此外,表单解析器返回form_fields的列表:
{ // document
"text": "My name:\nDEEP THOUGHT\nYour question: What is the answer to the ultimate question?\nMy answer:\n42\n",
"pages": [
{
"page_number": 1,
"dimension": {/*…*/},
"layout": {/*…*/},
"detected_languages": [/*…*/],
"blocks": [/*…*/],
"paragraphs": [/*…*/],
"lines": [/*…*/],
"tokens": [/*…*/],
"form_fields": [/* NEW */],
"image": {/*…*/}
}
]
}
这是如何返回检测到的键值对:
{ // document.pages[0]
"form_fields": [
{ // "My name:\n"
"field_name": { "text_anchor": {/*…*/}, "confidence": 0.96 /*,…*/ },
// "DEEP THOUGHT\n"
"field_value": { "text_anchor": {/*…*/}, "confidence": 0.96 /*,…*/ }
},
{ // "Your question: "
"field_name": { "text_anchor": {/*…*/}, "confidence": 0.98 /*,…*/ },
// "What is the answer to the ultimate question?\n"
"field_value": { "text_anchor": {/*…*/}, "confidence": 0.98 /*,…*/ }
},
{ // "My answer:\n"
"field_name": { "text_anchor": {/*…*/}, "confidence": 0.76 /*,…*/ },
// "42\n"
"field_value": { "text_anchor": {/*…*/}, "confidence": 0.76 /*,…*/ }
}
]
}
这是他们检测到的边界框:

注意:表单字段可以遵循灵活的布局。在此示例中,密钥和值按左右顺序。接下来,您将看到一个右左示例。这些只是简单的任意示例。它还可以与垂直或自由布局一起使用,其中键和值在逻辑上(视觉上)相关。
复选框
表单解析器还检测到复选框。复选框实际上是特定的表单字段值。
此示例是法国考试,其确切时应检查。为了进行测试,我使用了不同类型的复选框,即印刷或手工制作的复选框。所有表单字段均被检测到,确认为字段名称,相应的复选框作为字段值:

检测到复选框时,表单字段包含一个额外的value_type字段,该字段为unfilled_checkbox或filled_checkbox:
{ // document.pages[0]
"form_fields": [
{ // [ ] Les cyclines se lient aux CDK…
"field_name": {/*…*/},
"field_value": {/*…*/},
"value_type": "unfilled_checkbox"
},
{ // [x] Les mutations peuvent être provoquées…
"field_name": {/*…*/},
"field_value": {/*…*/},
"value_type": "filled_checkbox"
} //,…
]
}
能够分析表格可以通过合并甚至为您自动加入内容来节省大量时间。
上一个复选框检测示例实际上是先前实验以自动更正我妻子的考试副本的演变。
使用复选框的概念证明变得更好,但是对于True/False手写答案已经足够结论。这是可以自动更正和自动射击的方式:

表
形式解析器还可以检测另一个重要的结构元素:表。
在此示例中,单词以表格的布局表示,没有任何边界。形式解析器找到了一个非常靠近(隐藏)布局的表。这是检测到的单元格:

在另一个示例中,有些单元格中填充文本,而另一些则为空白。有足够的信号使形式解析器检测表格结构:

检测到表时,形式解析器将返回带有行和单元格的tables列表。这是返回表的方式:
{ // document.pages[0]
"tables": [{
"layout": {/*…*/},
"header_rows": [{
// | ALPHA | | | | EPSILON | | ETA | |
"cells": [/*…*/]
}],
"body_rows": [{
// | | KAPPA | | MU | | XI | | PI |
"cells": [/*…*/]
},
{
// | RHO | | TAU | | PHI | | | OMEGA |
"cells": [/*…*/]
}]
}]
}
这是第一个单元格:
{ // document.pages[0].tables[0].header_rows[0].cells[0]
"layout": {
// ALPHA\n
"text_anchor": {/*…*/},
"confidence": 0.9979,
"bounding_poly": {/*…*/},
"orientation": "PAGE_UP"
},
"row_span": 1,
"col_span": 1
}
专业处理器
专业处理器专注于域特异性文档和提取实体。它们涵盖了许多不同的文档类型,这些文档类型当前可以在以下家庭中分类:
- 采购收据,发票,水电费,采购订单,
- 贷款银行对帐单,支付单,官方表格,
- 身份国家ID,驾驶执照,护照,
- 合同法律协议
例如,采购处理器通常检测到total_amount和currency实体:
{ // document
"entities": [
{
"text_anchor": {/*…*/},
"type_": "total_amount",
"mention_text": "15",
"confidence": 0.96,
"page_anchor": {/*…*/},
"id": "0"
},
{
"text_anchor": {/*…*/},
"type_": "currency",
"mention_text": "USD",
"confidence": 0.95,
"page_anchor": {/*…*/},
"id": "1"
}
]
}
有关更多信息,请查看Fields detected。
花费
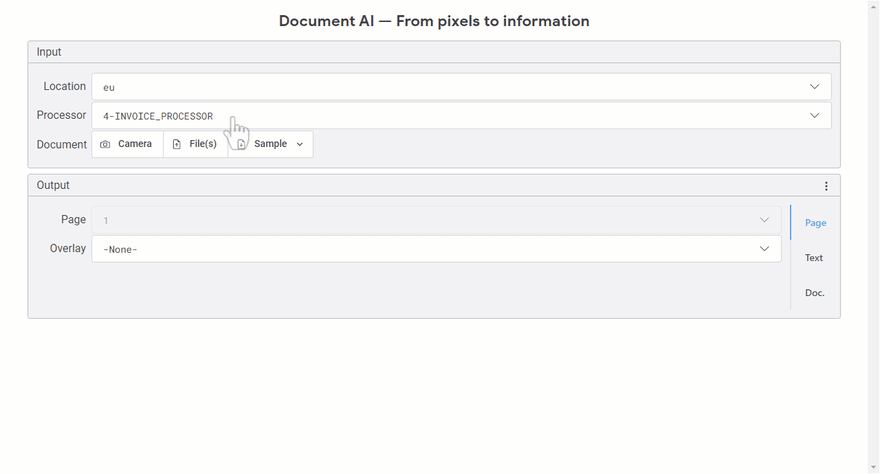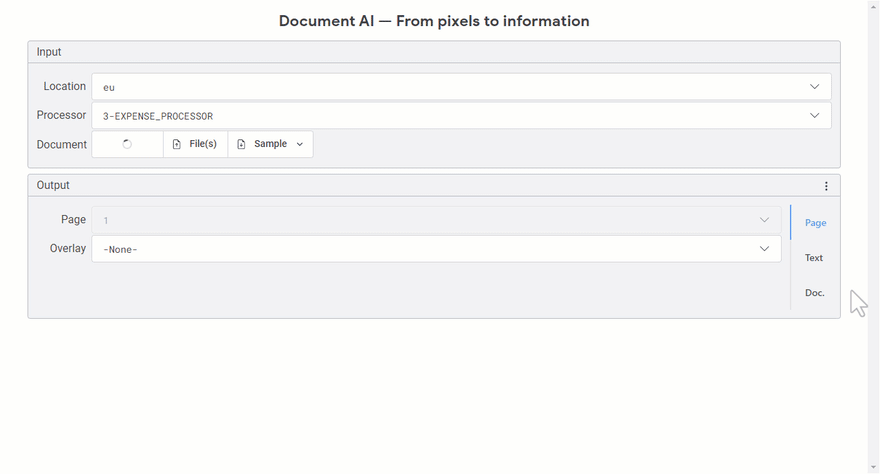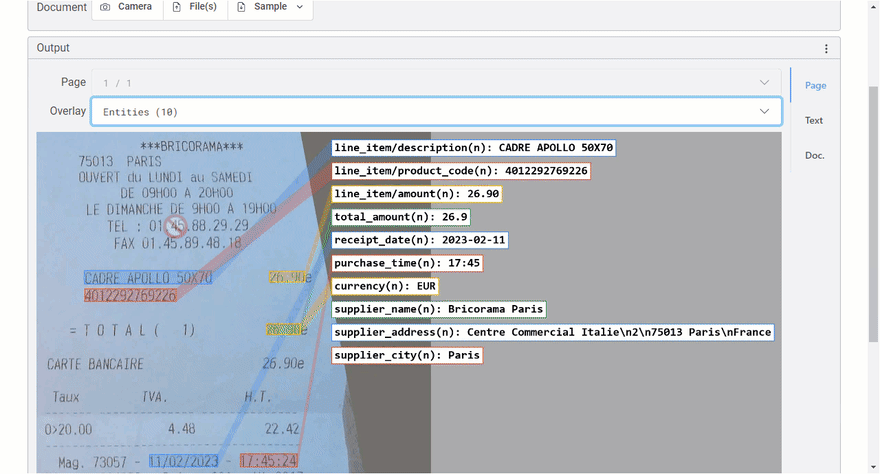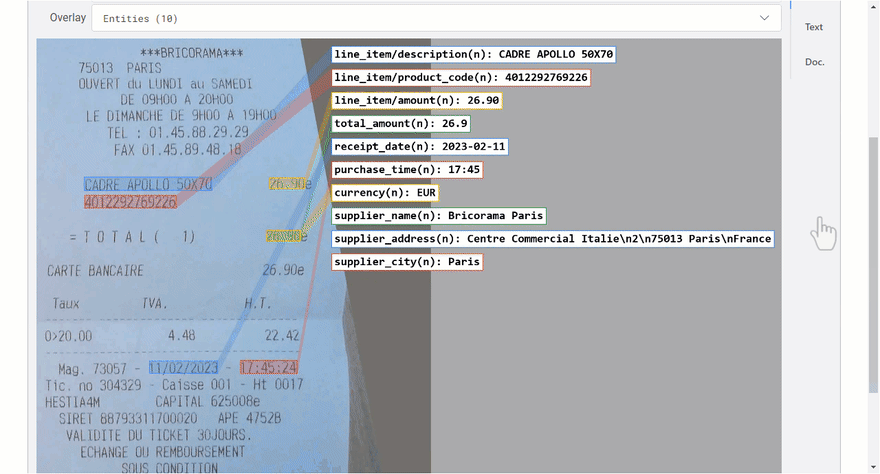
“费用解析器”使您可以处理各种类型的收据。让我们分析此实际(法语)收据:

一些言论:
- 提取所有预期的实体。
- 理想情况下(很挑剔),我也想获得税率。如果客户对此有需求,这可能是将来版本中的受支持实体。
- 由于收据的非常薄的纸,背面的文字通过透明度可见(另一种类型的噪声)。
- 供应商名称是错误的(实际上是从背面镜像的文本),但信心很低(4%)。您通常会特别注意(在此处显示不同)或忽略它。
- 实际供应商信息是故意隐藏的(收据的顶部)。 ,您会看到另一个带有供应商数据的示例。
- 收据通常印在单个(有时在多个)页面上。费用解析器支持分析最多10页的费用文件。
采购文档通常在表格布局中列出数据的一部分。在这里,它们返回了许多line_item/*实体。当将实体检测为层次结构的一部分时,结果将嵌套在父实体的properties字段中,提供了附加的信息。这是摘录:
{ // document.entities[7]
"text_anchor": {/*…*/},
"type_": "line_item",
"mention_text": "*BANANE BIO 1.99",
"confidence": 1.0,
"page_anchor": {/*…*/},
"id": "9",
"properties": [
{
"text_anchor": {/*…*/},
"type_": "line_item/description",
"mention_text": "*BANANE BIO",
"confidence": 0.54613465,
"page_anchor": {/*…*/},
"id": "10"
},
{
"text_anchor": {/*…*/},
"type_": "line_item/amount",
"mention_text": "1.99",
"confidence": 0.36692643,
"page_anchor": {/*…*/},
"id": "11"
}
]
}
有关更多信息,请参见Expense Parser详细信息。
实体归一化
获得结果通常不够。结果通常需要在后处理阶段进行处理,这既耗时又是错误的源头。为了解决这个问题,专业处理器还可以在可能的情况下返回归一化值。这使您可以直接使用从整个文档的上下文中合并的标准值。
让我们与该收据进行检查:

首先,根据normalized_value的标准代码返回收据货币:
{ // document.entities[0]
"type_": "currency",
"mention_text": "€",
"normalized_value": {
"text": "EUR"
} //,…
}
然后,收据日期为11/12/2022。但是是11月12日还是12月11日?文档AI使用文档的上下文(法语收据),并提供了消除所有歧义的归一化值:
{ // document.entities[1]
"type_": "receipt_date",
"mention_text": "11/12/2022",
"normalized_value": {
"text": "2022-12-11",
"date_value": {
"year": 2022,
"month": 12,
"day": 11
}
} //,…
}
同样,收据包含以非标准方式编写的购买时间。结果还包括一个避免任何解释的规范值:
{ // document.entities[5]
"type_": "purchase_time",
"mention_text": "12h42\n",
"normalized_value": {
"datetime_value": {
"hours": 12,
"minutes": 42
}
} //,…
}
归一化值简化了后处理阶段:
- 他们提供了直接使用的标准值(例如,在数据仓库中启用直接存储)。
- 它们可以防止错误(尤其是我们在转换数据时犯的重复出现的开发人员错误)。
- 他们消除了歧义,并通过使用整个文档的上下文避免了错误的解释。
有关更多信息,请查看koude69结构。
实体丰富
您是否注意到收据中有更多信息?

- “ Maison Jeanne d'Arc,Place de Gaulle” 提到了Arc的房子和地名。但是,没有地址,邮政编码,城市甚至国家。
- 这笔收据很可能来自法国的一个博物馆,但琼(Joan of Arc
- 那么,这对应于哪个位置?
- 手动搜索应该提示调查,但是我们可以保持自动化吗?
提取数据背后的信息需要额外的知识或人类调查。
自动化解决方案通常会忽略此部分数据,但记录AI以独特的方式处理此数据。
为了了解世界的信息,Google一直在始终分析网络已有20多年的历史。
结果是一个名为“知识图”的巨大最新知识库。
文档AI利用此知识图来归一化和丰富实体。
首先,供应商以其通常的名称正确检测和标准化:
{ // document.entities[6]
"type_": "supplier_name",
"normalized_value": {
"text": "Maison de Jeanne d'Arc"
} //,…
}
然后,供应商城也被返回:
{ // document.entities[8]
"type_": "supplier_city",
"normalized_value": {
"text": "Orléans"
} //,…
}
注意:Arc的琼(Joan of Arc)在1429年在OrléAns度过了一段时间,她在17岁时带领被围困的城市解放(但这是另一个故事)。
最后,完整和规范的供应商地址也是结果的一部分,在此处结束我们的案子:
{ // document.entities[7]
"type_": "supplier_address",
"normalized_value": {
"text": "3 Pl. du Général de Gaulle\n45000 Orléans\nFrance"
} //,…
}
富集实体带来显着价值:
- 它们是规范的结果,避免了信息冲突和差异。
- 他们可以添加信息,以防止忽略有用的数据。
- 他们可以完成或修复部分正确的数据。
- 简而言之,它们提供了可靠,一致且可比的信息。
这是收据中检测到的预期的和非明显实体的回顾:

注意:丝毫特征元素可以足以检测实体。
我经常惊讶地发现我没想到的实体,最终意识到我错过了文档中的线索。
例如,我最近想知道费用处理器如何能够识别特定的商店。
收据仅指定了邮政编码,零售链在我附近有几家商店。
好吧,一个公共电话号码(隐藏在页脚中)足以唯一地识别有关商店并提供其完整地址。
要了解有关知识图和可能富集的更多信息,请查看Enrichment and normalization。
发票
发票是最精致的采购文档类型,通常在多个页面上传播。
这是一个显示“发票解析器”提取的实体的示例:

一些言论:
- 提取相关信息(甚至在90°左侧检测到供应商税ID)。
- 如前所述,发票解析器提取了许多
line_item/*实体,也可以提取supplier_*和receiver_*Info。 - 这是一张典型的发票(由历史法国能源提供商发行),在第一页上有许多数字。
- 原始来源是匿名,印刷,染色和扫描为PDF(栅格)的PDF(数字)。
有关更多信息,请参见Invoice Parser详细信息。
条形码
针对某些处理器启用条形码检测。在此示例中,发票解析器检测条形码(清单号):

注意:我没有带有条形码的发票,所以我使用了(稍微匿名的)包装列表。
条形码在页面级别返回,如下:
{ // document.pages[0]
"detected_barcodes": [
{
"layout": {/*…*/},
"barcode": {
"format_": "CODE_39",
"value_format": "TEXT",
"raw_value": "E-58702865"
}
}
]
}
有关更多信息,请查看koude73结构。
身份文件
身份处理器可让您提取身份实体。在这个美国护照标本(信用:Bureau of Consular Affairs)中,可以自动提取预期字段:

有关身份处理器的更多详细信息,您可以阅读我以前的文章Automate identity document processing。
文档信号
一些处理器返回文档信号 - 相对于文档本身的信息。
例如,“文档OCR”处理器返回文档的质量分数,估计可能影响结果准确性的缺陷。
前面的皱巴布示例的高质量得分为95%,眩光是潜在的缺陷:

同一示例以低于4倍的分辨率为53%的质量得分较低,模糊为主要潜在问题:

一些其他评论:
- 低分让您可以标记可能需要手动审查(或新的更好捕获)的文档。
- 令人惊讶的是,在两种情况下,完全相同的文本都正确提取(我检查了两次),但情况并非总是如此。
- 质量分数既作为实体(带有
quality_scoreparent entity)和页面级的image_quality_scores字段(请参阅ImageQualityScores)。 - 这是通过释放候选者
pretrained-ocr-v1.1-2022-09-12进行测试的。
这是在页面级别返回图像质量得分的方式:
{ // document.pages[0]
"image_quality_scores": {
"quality_score": 0.53,
"detected_defects": [
{ "confidence": 0.98, "type_": "quality/defect_blurry" },
{ "confidence": 0.77, "type_": "quality/defect_glare" },
{ "confidence": 0.16, "type_": "quality/defect_text_too_small" },
{ "confidence": 0.05, "type_": "quality/defect_noisy" },
{ "confidence": 0.03, "type_": "quality/defect_faint" },
{ "confidence": 0.01, "type_": "quality/defect_dark" }
]
}
}
同样,“身份证明”处理器为您提供有关ID文档有效性的信号。
首先,这可以帮助检测文档是否看起来像ID。此前示例是一个随机文档,分析为NOT_AN_ID:

这是相应的实体:
{ // document
"entities": [
{
"type_": "fraud_signals_is_identity_document",
"mention_text": "NOT_AN_ID" //,…
},
{
"type_": "fraud_signals_suspicious_words",
"mention_text": "PASS" //,…
},
{
"type_": "fraud_signals_image_manipulation",
"mention_text": "PASS" //,…
},
{
"type_": "fraud_signals_online_duplicate",
"mention_text": "PASS" //,…
}
]
}
上一个护照示例确实被检测为ID,但也触发有用的欺诈信号:

结果包括#1是一个标本,#2可以在线找到:
{ // document
"entities": [
{
"type_": "fraud_signals_is_identity_document",
"mention_text": "PASS" //,…
},
{
"type_": "fraud_signals_suspicious_words",
"mention_text": "SUSPICIOUS_WORDS_FOUND" //,…
},
{
"type_": "evidence_suspicious_word",
"mention_text": "SPECIMEN" //,…
},
{
"type_": "fraud_signals_image_manipulation",
"mention_text": "POSSIBLE_IMAGE_MANIPULATION" //,…
},
{
"type_": "evidence_thumbnail_url",
"mention_text": "https://….gstatic.com/images?…" //,…
},
{
"type_": "evidence_hostname",
"mention_text": "pbs.twimg.com" //,…
},
{
"type_": "fraud_signals_online_duplicate",
"mention_text": "POSSIBLE_ONLINE_DUPLICATE" //,…
}
]
}
随着新用例的出现,一些处理器可能会提取新的文档信号。关注Release notes保持更新。
预训练的处理器
文档AI已经很大,并且不断发展。这是一个显示当前处理器库以及如何从云控制台创建处理器的屏幕列表:

带工作台的定制处理器
如果您有自己的特定于业务的文档,则可能希望提取现有处理器不涵盖的自定义实体。文档AI Workbench可以通过创建自己的自定义处理器(通过您自己的文档培训,通过两种方式)来帮助您解决此问题:
- 使用上升,您可以扩展现有处理器。
- 您还可以从头开始创建新处理器。
有关更多信息,请观看我的队友霍尔特制作的精彩介绍视频:

表现
要捕获您的文档,您可能会使用:
- 扫描仪
- 相机
使用扫描仪,您需要选择每英寸点的分辨率(DPI)。为了优化性能(尤其是结果的准确性和一致性),您可以牢记以下内容:
- 300 dpi通常是一个不错的地方
- 200 dpi通常是最低限度的
这是捕获一张纸所需的分辨率:

注意:尺寸在水平方向中显示(图像传感器通常具有景观天然分辨率)。
使用相机,每英寸捕获的点取决于相机分辨率,也取决于您放大文档的方式。这是A4纸的示例:
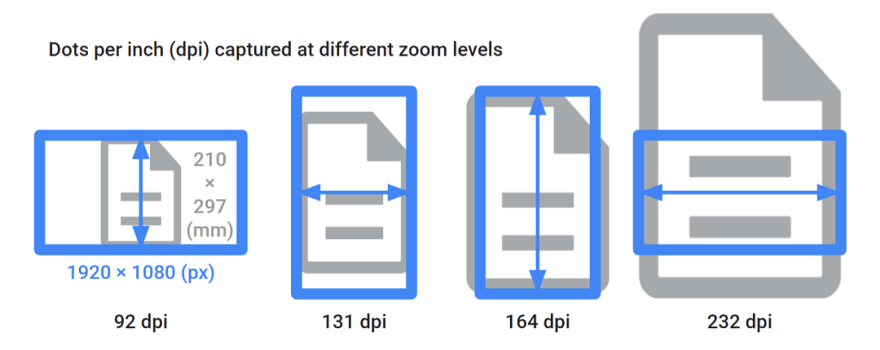
这转化为不同的DPI范围。这是指示值:

为了给您一个想法,这是PNG图像大小在不同分辨率下捕获同一文档时的演变。像素的总数是表面。尽管PNG压缩略微限制了生长,但大小几乎倍增:

一些一般性观察:
- 文件捕获通常在100-600 dpi范围内,具体取决于用例。
- 100-200 DPI可能足以容纳某些特定的最终用户解决方案,例如处理从手机摄像机或笔记本电脑网络摄像头捕获的小收据。
- 300-600 dpi的扫描可能会提供更好的结果,但会生成更大的文件并使您的处理管道慢。
- 扫描超过600 dpi的可能性较小。它们对于非常小的文档(例如幻灯片或负膜)或需要抬高的文档(例如打印海报)很有用。
- 如果您的用例涉及带有小文本,条形码或非常嘈杂(例如模糊)输入的文档,则通常需要通过更高的捕获分辨率进行补偿。
- 捕获设备对使用技术具有固有的噪声。他们通常有可以产生不同结果的选择。另外,在弱光环境中,图像传感器更加嘈杂。
- 您体系结构中的每个转换步骤都可能引入副作用和潜在的信息丢失。
- 有损的图像格式(例如JPEG)可以很好地降低图像大小。另一方面,过高的压缩水平(设置)可能会产生对检测性能的负面影响(导致图像质量的强烈降解,因此结果准确性的强烈降解)。 )。
- 无损格式(例如PNG)意味着更大的文件大小,但可能会带来较低分辨率的好处。通过保留以后转换为其他格式或较小的分辨率而不会丢失信息的可能性,它们也可能更适合未来(例如,用于档案)。
- 存储成本相当低,因此考虑更高可接受的扫描解决方案,优化解决方案的性能和整体成本也可能很有趣。
- 简而言之,选择捕获设备,分辨率和格式取决于您的用例,并且是准确性,速度和成本之间的权衡。
为了确定解决方案并获得更准确,更快或一致的结果,您可以考虑以下内容:
- 通过不同分辨率的最差文档检查解决方案的性能。
- 对您的处理管道中使用的不同格式有清晰的了解。
- 使用实际文档测试解决方案(尽可能接近您的生产中的内容)。另外,随着ML模型经过实际文档的培训,在测试真实文档时,您可能会获得更好的结果。
- 尽可能将无损格式保持在上游;文档可以转换为下游的有损格式。
- 评估以更高的分辨率捕获然后降低缩放是否会产生更好的结果。
- 使用有损耗的格式时,将压缩水平列出。通常有一个阈值,在保持良好的压缩比的同时,压缩伪像可以忽略不计。
- 使用摄像头时,控制您的照明环境并避免弱光条件。
- 让您的用户意识到模糊捕获可能会降低性能。
例如:
- 本文中的示例都可以使用摄像机的分析范围为100至220 dpi。但是,结果并不总是与低分辨率一致。
- 出于实际原因,我主要使用笔记本电脑,手机或专用相机。有很多很棒的(称为文档摄像机)可以坐在您的桌子上,并提供快速自动对焦的固体捕获。
- 对于企业级解决方案,我可能会坚持300次DPI扫描。多功能打印机通常具有提供出色的PNG,PDF或TIFF捕获的扫描仪。
- 条形码(包含在上面的包装列表样本中)用扫描仪在150 dpi下开始检测到,并使用网络摄像头进行200 dpi。被复印(即扫描 +印刷)后,仍在150 dpi检测到扫描仪,但需要使用网络摄像头进行缩放。
- 在捕获浏览器和网络摄像头的文档时,我检查了HTML帆布默认格式:它是png(很好!),但在RGBA中(带有透明频道,对文档图像不必要)。
这使数据变得更大而没有任何好处。优化是一个参数(
canvas.getContext('2d')canvas.getContext('2d', { alpha: false })),并使捕获发送到后端9%至18%。
样品演示
我把自己放在你的鞋子里,看看构建文档处理原型所需的内容,并做出以下选择:
- 使用香草JavaScript的前端,负责管理用户交互和输入文档
- 使用Python客户端库的后端,负责所有文档处理和效果图
- 同步呼叫记录AI,实时处理文档
- 没有云存储,以避免存储个人身份信息(分析存储客户端)
这是基于开源Python项目的选择的软件堆栈:

- 使用云运行:
将其部署到生产中的一种可能的体系结构:
这是我用来处理python中的文档的核心函数:
from typing import BinaryIO
from google.cloud.documentai_v1 import (
Document,
DocumentProcessorServiceClient,
ProcessRequest,
RawDocument,
)
def process_document(
file: BinaryIO,
mime_type: str,
project: str,
location: str,
processor_id: str,
) -> Document:
"""Analyze the input file with Document AI."""
client_options = {"api_endpoint": f"{location}-documentai.googleapis.com"}
client = DocumentProcessorServiceClient(client_options=client_options)
raw_document = RawDocument(content=file.read(), mime_type=mime_type)
name = client.processor_path(project, location, processor_id)
request = ProcessRequest(
raw_document=raw_document,
name=name,
skip_human_review=True,
)
response = client.process_document(request)
return response.document
要确保“您看到的是您得到的”,本文中的示例图像和动画是由演示生成的:

注意:为避免在开发应用程序时重复和不必要的呼叫记录AI,请缓存示例文档分析(JSON Serialization)。这使您可以检查返回的结构化文档,还可以解释为什么在此(实时而不是加速)屏幕截图中立即响应。
分析文档需要几秒钟。这是用户上传PDF扫描的示例:

您也可以从Web应用程序中捕获相机捕获:
查看source code,并随时重复使用。您还会找到将其部署为无服务器应用的说明。
更多的?
- 测试文件?尝试Document AI in your browser。
- 视频系列?观看The future of documents。
- Google Cloud的新手?查看$300 free trial offer。
- 学习和成长? `成为Google Cloud Innovator。
- 反馈还是问题? –在Twitter(@PicardParis)或LinkedIn(in/PicardParis)上伸出援手。