tl; dr
在Kubernetes中使用Spring Scheduler在Kubernetes中使用Spring Scheduler时要警惕线程,锁定和工作持续时间,以防止重复和延迟的作业运行。如果您不在春季调度程序路线上,请考虑替代解决方案,例如Kubernetes CronJob。
背景
我和我的夫妇的任务是在我们的春季启动应用程序中实现两个日常作业,以通过电子邮件发送一组用户。在进入解决方案之前,我们概述了我们的问题约束:
- 我们的Spring Boot应用程序已部署在Kubernetes上
- 计划的工作
- 需要在特定时间运行
- 有可变的运行时间,通常在几分钟的顺序上运行
- 共享核心应用程序实施并拆分依赖性将引入风险和复杂性
我们将解决方案范围缩小到Spring Scheduler并使用Kubernetes CronJob。我们决定从Spring Scheduler开始,因为它很熟悉,并且在添加了几个注释后,我们正在运行。这两个工作定于11:00运行,我们添加了一些伐木,以便我们可以关注它们:
@Scheduled(cron = "0 0 11 * * *")
public void job1() {
System.out.println("Running job1.");
sendEmails();
}
@Scheduled(cron = "0 0 11 * * *")
public void job2() {
System.out.println("Running job2.");
sendMoreEmails();
}
我们将更改推向了开发环境,并在等待新工作运行时讨论了我们的测试策略。我们的初始测试是检查日志中与计划作业相关的条目。为了测试我们的工作是否按预期运行,我们需要验证每项工作:
- 在配置的时间(上午11点)运行
- 精确运行一次 我们将使用桌子来跟踪我们的进度:
| job | 在配置的时间 | 运行精确一次 |
|---|---|---|
| job1 | - | - |
| job2 | - | - |
问题
当我们那天晚些时候检查日志时,我们发现工作已经运行了。但是,我们看到两个工作都有两个日志条目!我们还注意到,在这两种情况下,第二份工作(Job2)在11:00之后开始略微开始:
2023-01-15 11:00:00.000 [ scheduling-1] [pod-1] : Running job1.
2023-01-15 11:00:00.000 [ scheduling-1] [pod-2] : Running job1.
2023-01-15 11:07:42.915 [ scheduling-1] [pod-1] : Running job2.
2023-01-15 11:08:03.792 [ scheduling-1] [pod-2] : Running job2.
我们的测试结果:
| job | 在配置的时间 | 运行精确一次 |
|---|---|---|
| job1 | ||
| job2 |
我们从日志中学到了两件事:
- 重复条目来自不同的应用程序实例(基于日志上下文中的POD名称)
- 每个实例上的作业在同一线程上运行 - 调度-1
很奇怪。我们走的兔子洞!

重复的作业运行
由于我们在开发环境中只有两个应用程序实例,因此我们猜测它正在每个实例上运行计划的作业。我们通过增加和减少POD的数量并检查我们的日志来验证这一点。
在堆栈溢出上进行快速搜索告诉我们we weren’t the first ones遇到了在Kubernetes部署的应用程序中运行计划作业的问题。在查看了一些解决方案并与同事聊天后,我们决定查看一种名为ShedLock的锁定解决方案。简而言之,Shedlock维护一个数据库表,该表可以用作应用程序实例中的锁定。我们要掩盖shedlock配置,因为许多人已经拥有covered it in depth。配置后,第一个运行该作业的应用程序将创建一个锁定,以防止任何其他实例运行同一作业。完成工作或达到最大锁定时间后,锁定锁定。
在这里,我们的工作是带有Shedlock注释(@Scheduledlock),最小锁定时间(Lockatleastfor的)和最大锁定时间(``Lockatmostfor)的样子:
@Scheduled(cron = "0 0 11 * * *")
@SchedulerLock(name = "job1", lockAtLeastFor = "PT5m", lockAtMostFor = "PT10m")
public void job1() {
System.out.println("Running job1.");
sendEmails();
}
@Scheduled(cron = "0 0 11 * * *")
@SchedulerLock(name = "job2", lockAtLeastFor = "PT5m", lockAtMostFor = "PT10m")
public void job2() {
System.out.println("Running job2.");
sendMoreEmails();
}
注意:我们会回到一个
我们部署了更改并再次检查了日志:
2023-01-16 11:00:00.000 [ scheduling-1] [pod-1] : Running job1.
2023-01-16 11:00:00.000 [ scheduling-1] [pod-2] : Running job2.
2023-01-16 11:08:03.206 [ scheduling-1] [pod-2] : Running job1.
再次重复的日志!但是,这一次只是为了工作之一 - 进步!
| job | 在配置的时间 | 运行精确一次 |
|---|---|---|
| job1 | ||
| job2 |
锁的持续时间
我的一对和我被卡住了,所以我们画了一个图来绘制一系列事件:
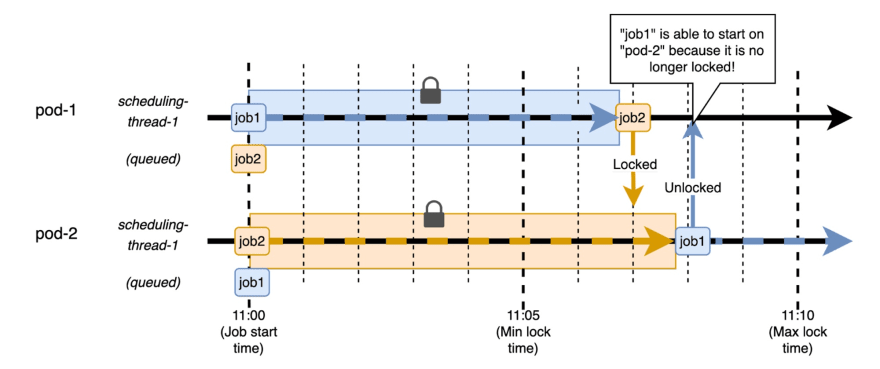
这两个工作都同时开始,并启用了两个锁。 Job1完成后,锁定了。同时,Job2仍在第二个实例上运行。 Job2结束后,Job1被脱水了,它可以开始,因为锁已经发布。
锁定的解决方案太短是将其增加比其他工作更长。因此,最小锁定时间(lockatleastforâ)的JOB1应比Job2的时间更长,反之亦然。由于我们的工作只每天跑一次,因此我们能够与锁定时间保持自由 - 我们将其锁定至少15小时,最多20小时。
@Scheduled(cron = "0 0 11 * * *")
@SchedulerLock(name = "job1", lockAtLeastFor = "PT15h", lockAtMostFor = "PT20h")
public void job1() {
System.out.println("Running job1.");
sendEmails();
}
@Scheduled(cron = "0 0 11 * * *")
@SchedulerLock(name = "job2", lockAtLeastFor = "PT15h", lockAtMostFor = "PT20h")
public void job2() {
System.out.println("Running job2.");
sendMoreEmails();
}
现在我们的时间表看起来像这样:
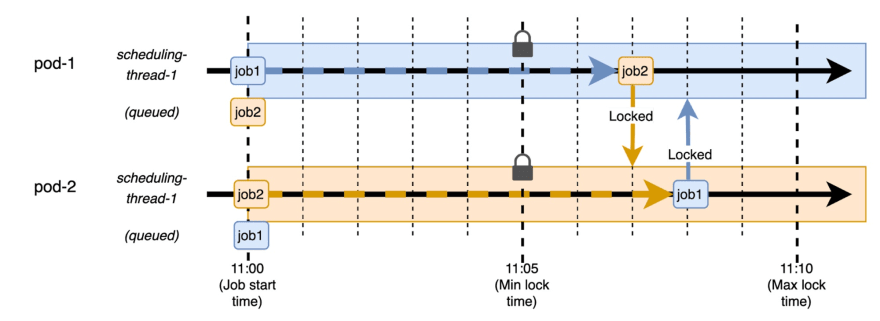
对于我们的八分钟工作来说,锁定15个小时是过分的,但是我的一对,我同意,一般而言,锁定时间应该最大化,以减少它们多次运行的机会。我们认为,如果您的工作每分钟每分钟运行,则应将其锁定59秒,如果每小时运行,则应锁定59分钟,依此类推。
我们再次部署并检查了日志:
2023-01-16 11:00:00.000 [ scheduling-1] [pod-1] : Running job1.
2023-01-16 11:00:00.000 [ scheduling-1] [pod-2] : Running job2.
| job | 在配置的时间 | 运行精确一次 |
|---|---|---|
| job1 | ||
| job2 |
成功!

在同一线程上计划的作业
我们已经用锁定解决了重复的运行,但是我和我的一对仍然挂在同一线程上运行的作业上。我们的解决方案没有万无一失,因为添加另一份工作仍然会导致一份工作在另一个工作后排队。这意味着第三份工作将在另一项时间之后而不是在计划的时间之后运行:
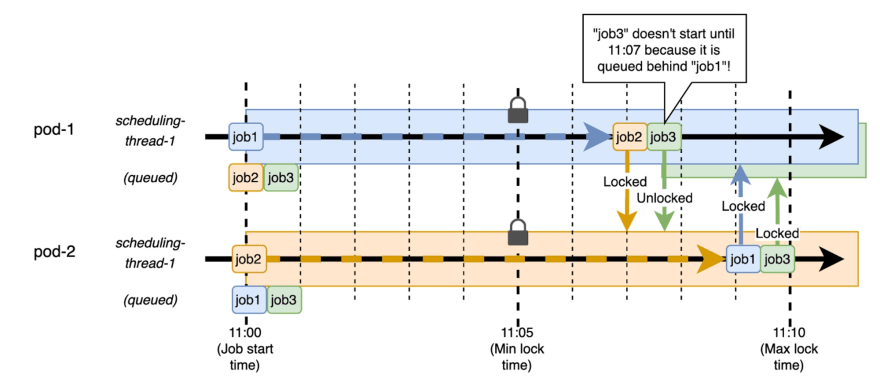
更一般而言,只要有更多的计划作业就会比应用程序实例更多,就会出现排队问题。阅读了一些激动人心的春季文档后,我们得知Spring Scheduler is configured to use a single thread by default。修复程序是增加分配给调度程序的线程:
@Configuration
public class SchedulingConfigurerConfiguration implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
// Set thread pool size to 10
taskScheduler.setPoolSize(10);
taskScheduler.initialize();
taskRegistrar.setTaskScheduler(taskScheduler);
}
}
现在,调度程序有更多线程,我们可以避免排队作业,每个线程都将在配置的时间开始。一旦开始工作,就可以将锁定锁定,以防止任何其他应用程序实例开始同一工作:
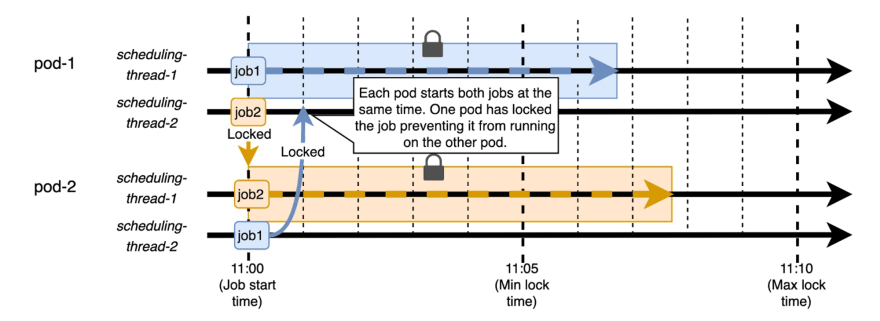
我和我的一对同意,最安全的路线是配置锁定和增加线程的数量。通过使用这两种解决方案,我们可以最大程度地减少任何工作不止一次或不在正确的时间运行的机会。
结论
我和我的一对了解了很多关于春季计划程序的陷阱以及Kubernetes中的工作如何引入新的复杂性。在螺纹,锁定,工作持续时间和应用程序实例之间,您可能会遇到很多潜在的障碍。希望我们的发现至少有助于几个人导航实施。
参考
- https://stackoverflow.com/a/49533618/20514850
- https://levelup.gitconnected.com/solving-multiple-executions-of-scheduled-tasks-across-multiple-nodes-even-with-shedlock-spring-2b1d26db9356
- https://www.baeldung.com/shedlock-spring
- https://dhananjay4058.medium.com/lock-scheduled-tasks-with-shedlock-and-spring-boot-f67200dad675
- https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/